Google прэзентавала Gemini 2.5 — сваю самую разумную мадэль, разумнейшую за o3 ад OpenAI
Google выпусціла новае пакаленне мультымадальных разважальных мадэляў Gemini 2.5. Кампанія называе Gemini 2.5 Pro Experimental сваёй самай разумнай мадэллю з усіх, што яна калі-небудзь выпускала. Яна ўжо даступная ў Google AI Studio і ў аплікацыі Gemini для карыстальнікаў тарыфу Gemini Advanced. Кампанія паведаміла, што ад гэтага моманту ўсе яе новыя ШІ-мадэлі будуць мець здольнасць да разважання.
Google выпусціла новае пакаленне мультымадальных разважальных мадэляў Gemini 2.5. Кампанія называе Gemini 2.5 Pro Experimental сваёй самай разумнай мадэллю з усіх, што яна калі-небудзь выпускала. Яна ўжо даступная ў Google AI Studio і ў аплікацыі Gemini для карыстальнікаў тарыфу Gemini Advanced. Кампанія паведаміла, што ад гэтага моманту ўсе яе новыя ШІ-мадэлі будуць мець здольнасць да разважання.
Першай мадэллю са здольнасцю да разважання на рынку стала o1, якая выйшла ў верасні 2024 года. Зараз падобныя мадэлі прапануюць таксама Anthropic, DeepSeek, Google, xAI і іншыя. Такія мадэлі патрабуюць больш вылічальных магутнасцяў і больш часу на праверку фактаў і асэнсаванне запыту для дасягнення больш якаснага адказу.
Google выпусціла сваю першую разважальную версію Gemini у снежні. Gemini 2.5 лічыцца самай сур’ёзнай спробай кампаніі паспаборнічаць з прасунутымі мадэлямі лінейкі «o» OpenAI.
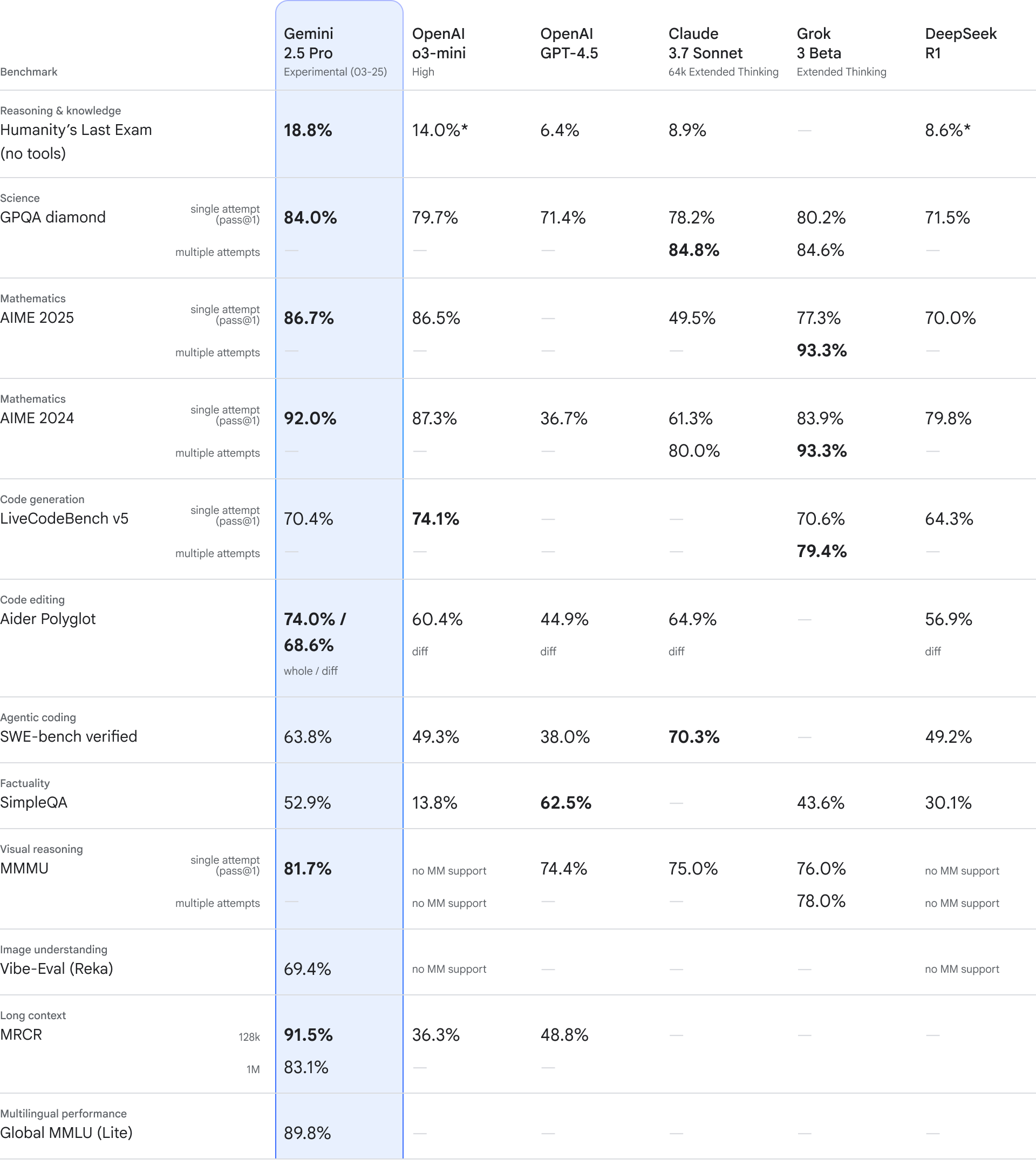
Google сцвярджае, што Gemini 2.5 Pro па шэрагу бенчмаркаў пераўзыходзіць лепшыя з яе папярэдніх мадэляў і некаторыя вядучыя ШІ-мадэлі канкурэнтаў. Асабліва, паводле кампаніі, яна выдатна спраўляецца са стварэннем вэб-аплікацый і напісаннем кода. Напрыклад, на бенчмарку Aider Polyglot, які ацэньвае навыкі рэдагавання кода ў мадэляў, Gemini 2.5 Pro набрала 68,6% — больш, чым найлепшыя мадэлі OpenAI, Anthropic і DeepSeek. На SWE-bench Verified для ацэнкі генерацыі кода Gemini 2.5 Pro набрала 63,8% — больш за o3-mini ад OpenAI і R1 ад DeepSeek, але саступіла Claude 3.7 Sonnet ад Anthropic, якая дасягнула 70,3%. На комплексным бенчмарку Humanity’s Last Exam, што змяшчае тысячы задач па матэматыцы, гуманітарных і прыродазнаўчых навуках, Gemini 2.5 Pro паказала вынік у 18,8%, што лепш за большасць флагманскіх мадэляў канкурэнтаў.
Кантэкстнае акно Gemini 2.5 Pro складае 1 млн токенаў (гэта прыкладна 750 тысяч слоў), і ў бліжэйшы час Google плануе падвоіць гэты паказчык. Кошт доступу да API кампанія пакуль не агучыла, але паабяцала раскрыць больш падрабязнасцяў у бліжэйшыя тыдні.








Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.