OpenAI: АІ-мадэлі не спраўляюцца з большасцю рэальных фрыланс-задач на праграмаванне
OpenAI стварыла новы бэнчмарк SWE-Lancer, які дэманструе магчымасці і абмежаванні АІ-мадэляў у распрацоўцы софту. Многія задачы ім пад сілу, аднак са складанымі софтвернымі праектамі, якія патрабуюць глыбокага разумення і нетрывіяльных рашэнняў, яны пакуль спраўляюцца не надта.
OpenAI стварыла новы бэнчмарк SWE-Lancer, які дэманструе магчымасці і абмежаванні АІ-мадэляў у распрацоўцы софту. Многія задачы ім пад сілу, аднак са складанымі софтвернымі праектамі, якія патрабуюць глыбокага разумення і нетрывіяльных рашэнняў, яны пакуль спраўляюцца не надта.
Бэнчмарк уключае 1400 рэальных задач з Upwork у дзвюх галінах: уласна распрацоўка і кіраванне праектамі. Калі выканаць іх усе, можна зарабіць $1 млн.
Софтверныя задачы вар'іраваліся ад простых на выпраўленне багаў за $50 (напрыклад, на ліквідацыю лішніх выклікаў API) да рэалізацыі складанага функцыяналу за $32 тысячы (напрыклад, стварэнне кросплатформеннага функцыяналу для прайгравання відэа для настольных, iOS-, Android- і вэб-праграм). Таксама правяралася, наколькі добра мадэлі змогуць ацаніць рашэнні, прапанаваныя жывымі распрацоўшчыкамі.
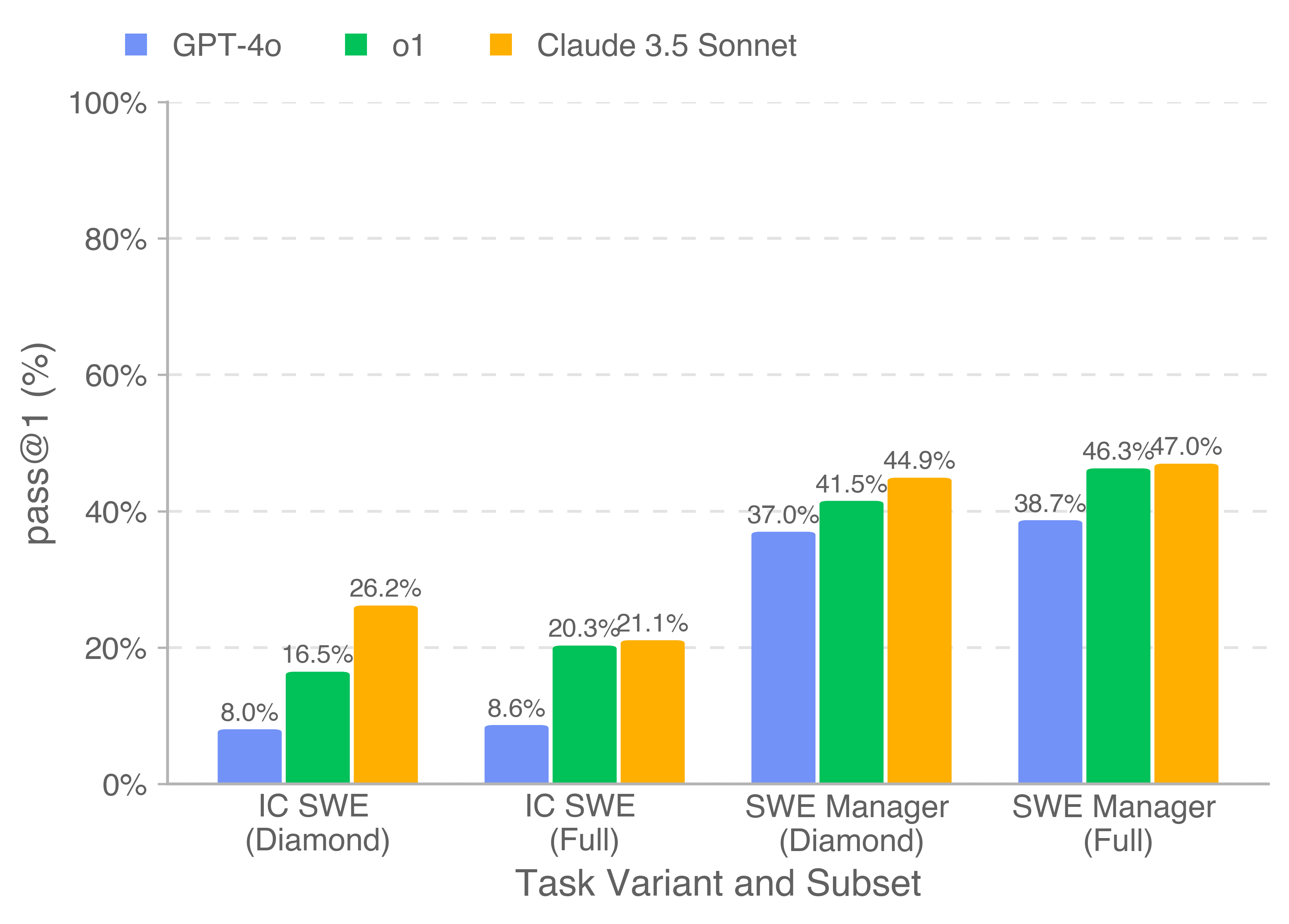
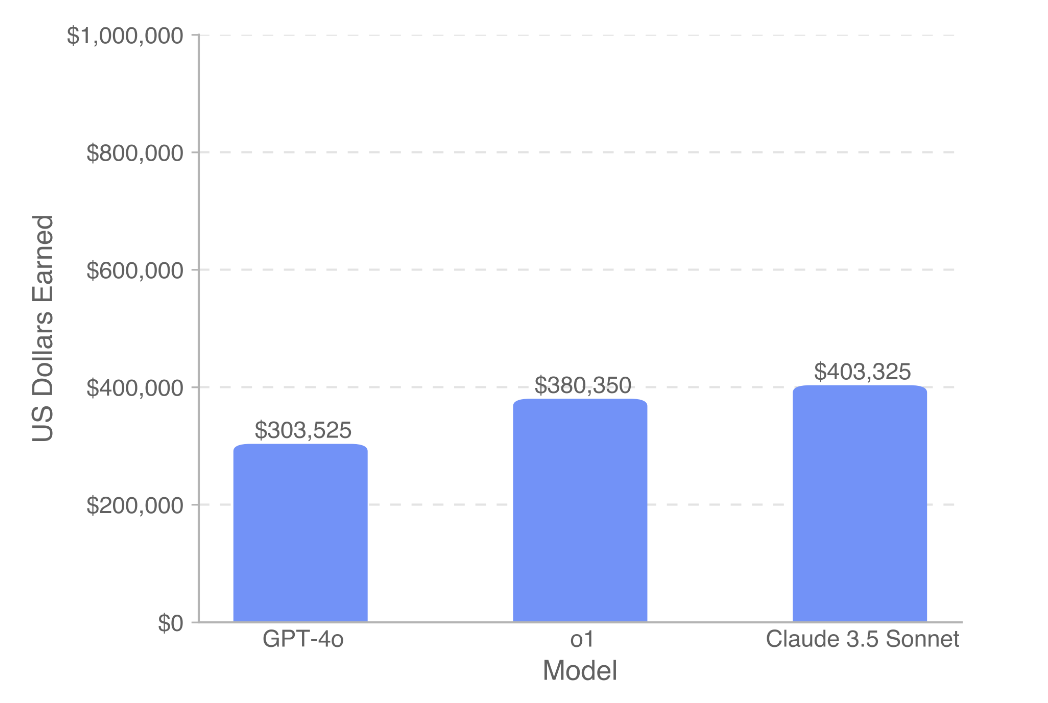
OpenAI адчувала тры мадэлі: GPT-4o, o1 і Claude 3.5 Sonnet. Найлепшы вынік паказала мадэль Anthropic — яна выканала 26,2% задач па праграмаванні і 44,9% заданняў, звязаных з проджэкт-менеджментам. Гэта далёка ад здольнасцяў чалавека, але ўсё роўна шматспадзеўна. Па грошах гэтая мадэль зарабіла $403 тысячы.
Бэнчмарк выкладзены на GitHub. У сваім рэлізе OpenAI адзначае, што вымярэнне ўмення АІ-мадэляў зарабляць грошы дазволіць больш дэталёва даследаваць іх эканамічны эфект для грамадства.




Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.
Сама заработает, сама потратит.