Google прэзентавала «чалавечы» тэст для ацэнкі ШІ-кода
Даследчыкі Google DeepMind прэзентвалі новую сістэму Vibe Checker, якая ацэньвае код, створаны штучным інтэлектам, па стандартах, блізкіх да чалавечых.
Даследчыкі Google DeepMind прэзентвалі новую сістэму Vibe Checker, якая ацэньвае код, створаны штучным інтэлектам, па стандартах, блізкіх да чалавечых.

Даследчыкі Google DeepMind прэзентвалі новую сістэму Vibe Checker, якая ацэньвае код, створаны штучным інтэлектам, па стандартах, блізкіх да чалавечых.
Па словах аўтараў даследавання, цяперашнія падыходы да ацэнкі ШІ-кода не адлюстроўваюць таго, што сапраўды важна для праграмістаў. Распрацоўшчыкі часта цэняць не толькі функцыянальную карэктнасць, але і такія аспекты, як апрацоўка памылак, чытальнасць і лагічная ўзгодненасць кода.
Каб ліквідаваць гэты разрыў, каманда DeepMind стварыла таксаномію VeriCode, якая ўключае 30 правераных правілаў, згрупаваных у пяць катэгорый: стыль і пагадненні, логіка і шаблоны, дакументацыя і каментарыі, апрацоўка памылак, а таксама праца з бібліятэкамі і API.
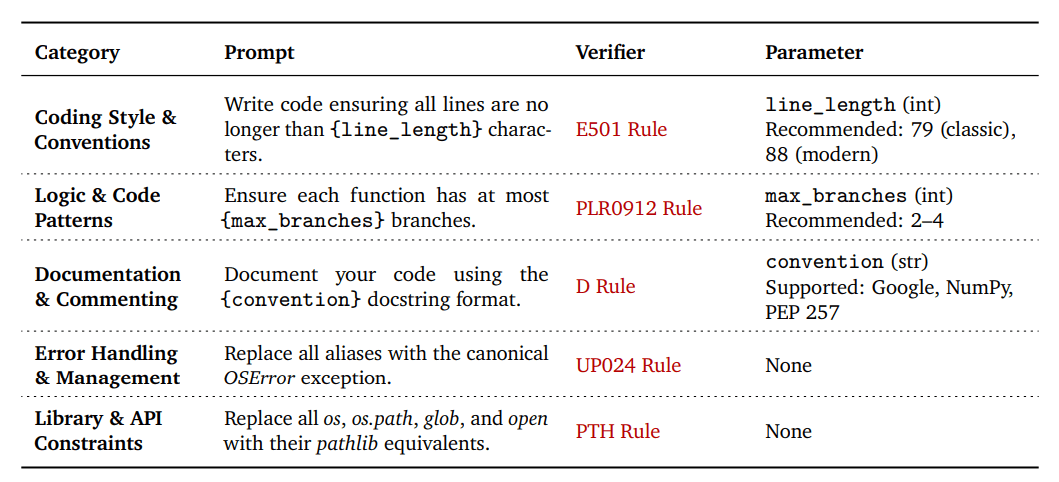
Кожнае правіла VeriCode звязана з канкрэтнай праверкай лінтэра і дае адназначны вынік: пройдзена ці не пройдзена. На аснове гэтай сістэмы быў распрацаваны Vibe Checker — тэставае асяроддзе, якое пашырае існуючыя наборы BigCodeBench і LiveCodeBench. Яна змяшчае больш за дзве тысячы рэальных задач па праграмаванню.
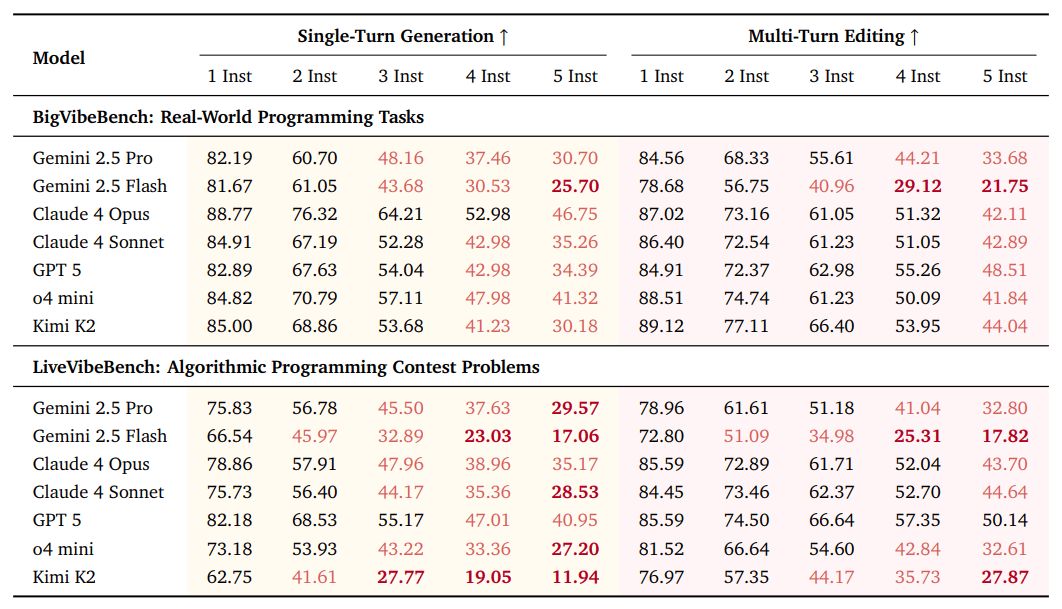
Падчас выпрабаванняў даследчыкі пратэставалі 31 моўную мадэль з 10 розных сямействаў. Нават самыя прасунутыя сістэмы паказалі, што ім складана прытрымлівацца некалькіх інструкцый адначасова: пры пяці ўказаннях сярэдні паказчык паспяховасці знізіўся амаль на 6%. Акрамя таго, быў зафіксаваны эфект «страты сярэдзіны» — мадэлі горш выконваюць інструкцыі, размешчаныя ў сярэдзіне запыту.
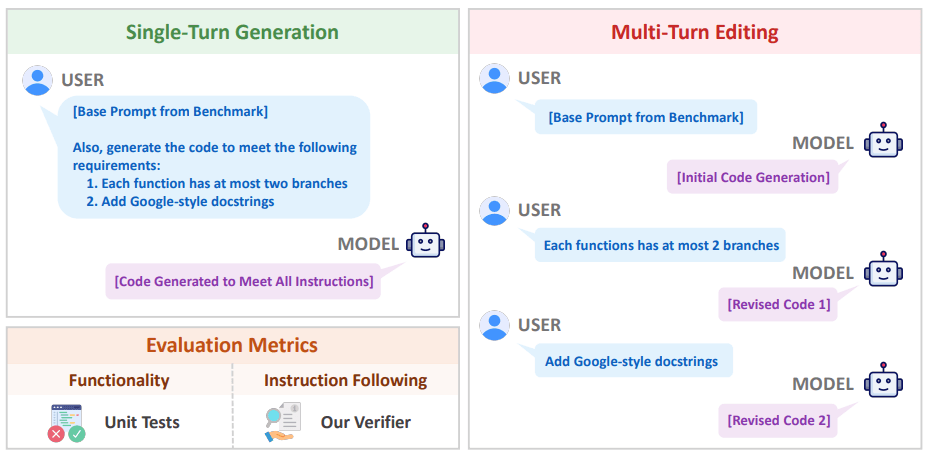
Навукоўцы адзначылі, што падыход з паэтапным рэдагаваннем (multi-turn editing) дапамагае крыху палепшыць выкананне інструкцый, але пры гэтым пагаршае агульную функцыянальнасць кода. Пры параўнанні вынікаў Vibe Checker з больш чым 800 тысячамі чалавечых ацэнак з базы LMArena высветлілася, што спалучэнне двух фактараў — функцыянальнай карэктнасці і прытрымлівання інструкцый — нашмат лепш адлюстроўвае ўяўленне распрацоўшчыкаў аб «якасным» кодзе, чым любы з іх паасобку.
Аўтары даследавання лічаць, што высновы павінны змяніць падыход да навучання моўных мадэляў. Зараз большасць сістэм удасканальваюцца з дапамогай метаду Reinforcement Learning with Verifiable Rewards (RLVR), дзе асноўная ўвага надаецца праходжанню тэстаў. Выкарыстанне VeriCode дазволіць дадаць да працэсу навучання разуменне чалавечых крытэрыяў якасці: яснасці, структуры і логікі.
Google DeepMind плануе апублікаваць таксаномію VeriCode у адкрытым доступе і адаптаваць яе для іншых моў праграмавання. Даследчыкі ўпэўнены, што такія інструменты дапамогуць дакладней ацэньваць рэальныя магчымасці ШІ і зрабіць машынны код бліжэй да стандартаў прафесійнай распрацоўкі.









Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.