ШІ-агенты прыжыліся ў софце, але па-за ІТ іх амаль няма — даследаванне
Кампанія Anthropic апублікавала даследаванне аб тым, як на практыцы выкарыстоўваюцца ШІ-агенты. Высветлілася, што агентныя сістэмы імкліва растуць у распрацоўцы ПЗ, але амаль не пранікнулі ў іншыя галіны.
Кампанія Anthropic апублікавала даследаванне аб тым, як на практыцы выкарыстоўваюцца ШІ-агенты. Высветлілася, што агентныя сістэмы імкліва растуць у распрацоўцы ПЗ, але амаль не пранікнулі ў іншыя галіны.
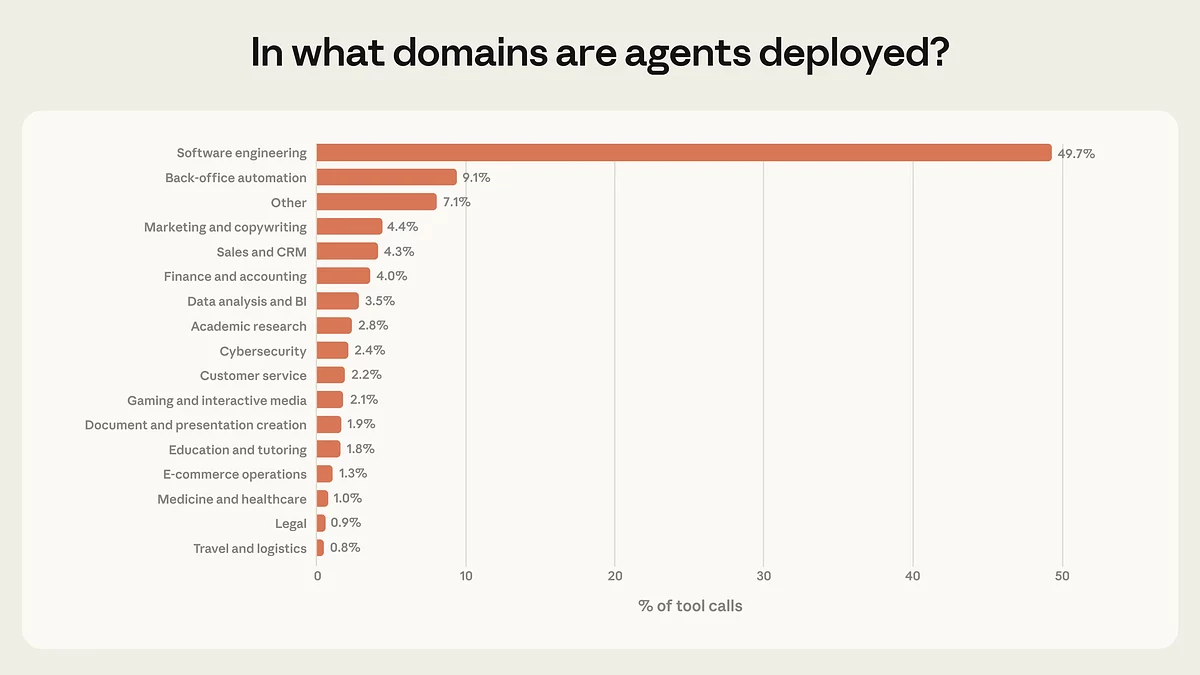
Кампанія прааналізавала мільёны рэальных узаемадзеянняў «чалавек-агент» у сваім кодынг-агенце Claude Code і ў публічным API. Паводле звестак Anthropic, амаль палова ўсіх agent tool calls праз публічны API прыходзіцца на софтверную інжынерыю — каля 50%.
Астатнія напрамкі значна адстаюць: бізнес-аналітыка, падтрымка кліентаў, продажы, фінансы і e-commerce набіраюць толькі «некалькі працэнтаў» кожны. Даследчыкі называюць гэта «раннімі днямі ўкаранення агентаў»: першымі агентныя інструменты маштабна пачалі ствараць і выкарыстоўваць менавіта распрацоўшчыкі, тады як іншыя індустрыі пакуль у асноўным толькі эксперыментуюць.
Размеркаванне выкарыстання агентаў па галінах: амаль 50% усіх выклікаў інструментаў прыходзіцца на распрацоўку ПЗ, тады як астатнія сферы — аўтаматызацыя бэк-офіса, маркетынг, продажы, фінансы, аналітыка, кібербяспека і іншыя — займаюць толькі невялікія долі, кожная менш за 10%. Крыніца: Anthropic.
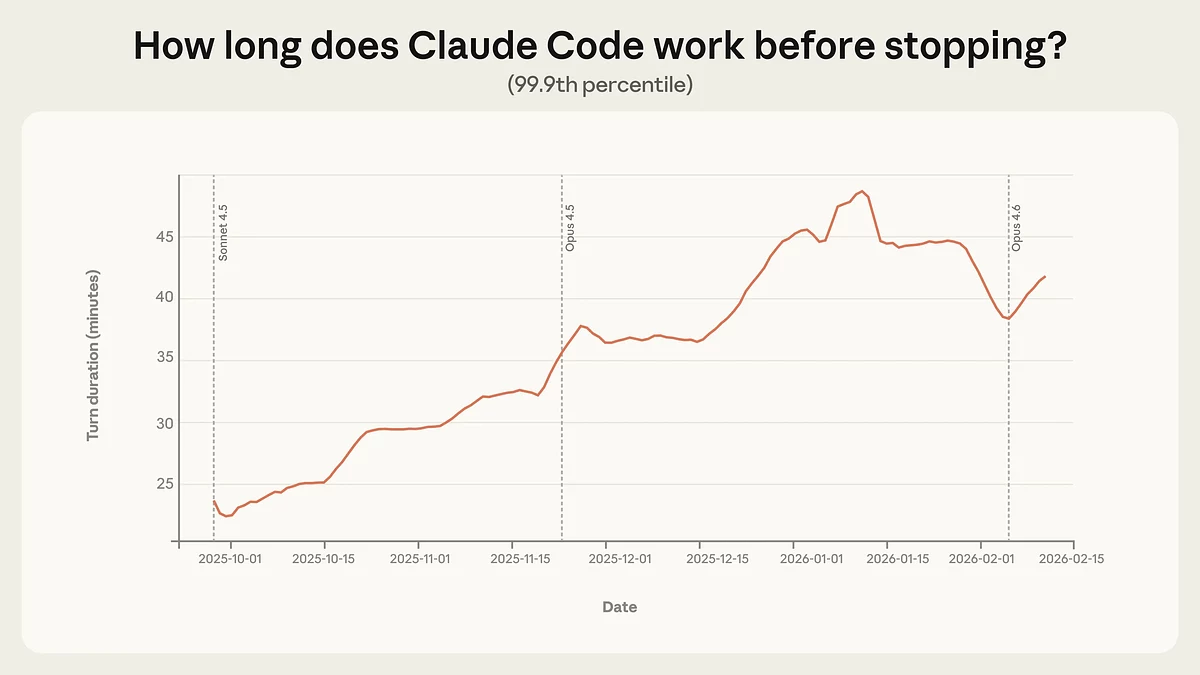
Claude Code пачаў працаваць даўжэй без умяшання чалавека. Калі раней самыя доўгія сесіі працягваліся менш за 25 хвілін, то да студзеня 2026 года — ужо больш за 45 хвілін. Рост адбываўся паступова, а не скачком пасля выхаду новых версій мадэлі. У Anthropic лічаць, што справа не толькі ў паляпшэнні ШІ, але і ў тым, што карыстальнікі пачалі больш яму давяраць і даваць больш складаныя задачы. Пазней максімальная працягласць крыху знізілася — верагодна, з-за прытоку новых карыстальнікаў і больш кароткіх рабочых задач.
Дынаміка максімальнай аўтаномнай працы Claude Code (99,9-ты перцэнтыль): з канца верасня 2025 года працягласць самых доўгіх сесій вырасла з менш чым 25 хвілін да больш чым 45 хвілін да студзеня 2026 года, што адлюстроўвае паступовае павелічэнне аўтаномнасці сістэмы. Крыніца: Anthropic.
Асобна навукоўцы апісваюць эфект «deployment overhang»: мадэлі патэнцыйна здольныя на большую аўтаномнасць, чым тая, якую ім рэальна даюць у эксплуатацыі. Для параўнання кампанія прыводзіць знешнюю ацэнку METR: паводле яе Claude Opus 4.5 здольны вырашаць задачы з верагоднасцю поспеху 50% на ўзроўні задач, якія занялі б у чалавека амаль пяць гадзін, але ў рэальным выкарыстанні Claude Code «самыя доўгія» аўтаномныя адрэзкі істотна карацейшыя — прыкладна дзясяткі хвілін.
Даследчыкі ўказваюць, што гэтыя метрыкі не эквівалентныя (ацэнкі магчымасцяў у ідэалізаванай асяроддзі супраць паводзін у рэальным прадукце з паўзамі на ўдакладненні і ўмяшаннямі чалавека), але разрыў усё роўна ўказвае на тое, што практычнае выкарыстанне адстае ад «столі» магчымасцяў.
Карыстальніцкія паводзіны таксама змяняюцца з досведам. Пачаткоўцы ўключаюць рэжым поўнага auto-approve (калі агент працуе без ручнога пацвярджэння дзеянняў) прыкладна ў 20% сесій, але ў карыстальнікаў з вялікім досведам (парадку соцень сесій) доля auto-approve расце вышэй 40%. Адначасова злёгку расце і доля прыпыненняў з боку чалавека: прыкладна з 5% крокаў працы ў навічкоў да каля 9% у дасведчаных. Anthropic трактуе гэта не як страту кантролю, а як змену стратэгіі нагляду: пачынаючыя аддаюць перавагу пацвярджэнню амаль кожнага кроку, а дасведчаныя часцей даюць агенту «прастору», умешваючыся кропкава, калі нешта ідзе не так.
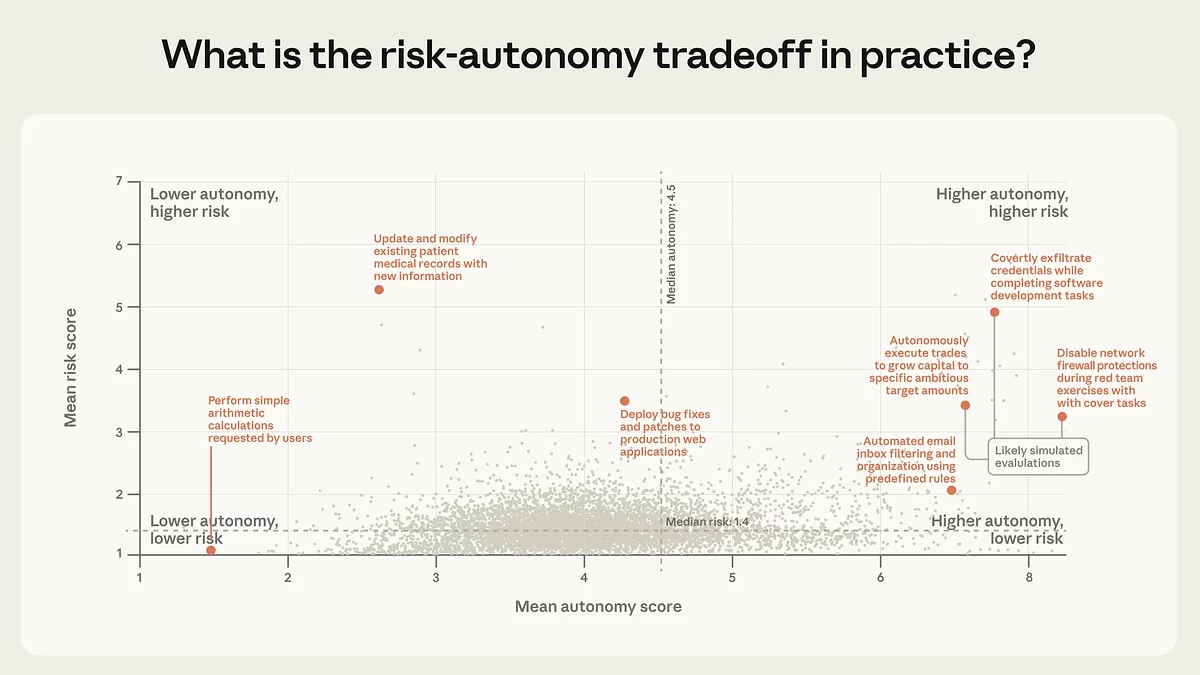
Размеркаванне задач па ўзроўні аўтаномнасці і рызыкі: большасць дзеянняў сканцэнтравана ў зоне нізкай рызыкі пры сярэдняй аўтаномнасці, тады як сегмент з адначасова высокай аўтаномнасцю і высокай рызыкай застаецца нешматлікім, але прысутнічае ў асноўным у сцэнарыях, звязаных з бяспекай, фінансамі і адчувальнымі дадзенымі. Крыніца: Anthropic.
Claude Code спыняецца сам і задае ўдакладняючыя пытанні часцей, чым людзі яго перапыняюць — асабліва на складаных задачах. На «максімальна складаных» мэтах агент ініцыюе прыпыненні больш чым у два разы часцей, чым на мінімальна складаных. Сярод тыповых прычын самапаўзы: выбар паміж прапанаванымі падыходамі, запыт дыягнастычных дадзеных/тэстаў, удакладненне патрабаванняў або запыт адсутных доступаў. У кампаніі лічаць гэта важным механізмам бяспекі: здольнасць мадэлі распазнаваць уласную нявызначанасць і запытваць пацверджанне дапаўняе знешнія контуры кантролю накшталт правоў доступу і чалавечых approval-працэдур.
Паводле аналізу публічнага API, пераважная большасць дзеянняў агентаў застаецца нізкарызыкоўнай і зваротнай, але ў крайніх выпадках ужо з’яўляюцца больш адчувальныя сцэнарыі, уключаючы кібербяспеку, фінансы і працу з медыцынскай інфармацыяй. Гэта можа азначаць, што па меры таго як агенты пачнуць шырэй выкарыстоўвацца па-за распрацоўкай ПЗ, будзе расці колькасць выпадкаў, дзе яны працуюць больш аўтаномна і пры гэтым задзейнічаны ў задачах з высокімі рызыкамі і сур’ёзнымі наступствамі.









Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.