ШІ дрэнна працуе на доўгай дыстанцыі — такога супрацоўніка ўжо б звольнілі
Даследчыкі Microsoft выявілі, што сучасныя ШІ-мадэлі і агенты пакуль дрэнна спраўляюцца з працяглымі працоўнымі задачамі. Нават францірныя мадэлі пачынаюць губляць або скажаць змест дакументаў, калі даручыць ім шматкрокавы працэс на дзесяткі ўзаемадзеянняў.
Даследчыкі Microsoft выявілі, што сучасныя ШІ-мадэлі і агенты пакуль дрэнна спраўляюцца з працяглымі працоўнымі задачамі. Нават францірныя мадэлі пачынаюць губляць або скажаць змест дакументаў, калі даручыць ім шматкрокавы працэс на дзесяткі ўзаемадзеянняў.
Аўтары даследавання «LLMs Corrupt Your Documents When You Delegate» вырашылі праверыць, наколькі вялікія моўныя мадэлі спраўляюцца з тым, за што іх усё часцей прасоўваюць на рынку: аўтаномнай працай над складанымі шматэтапнымі задачамі.
Для эксперымента даследчыкі стварылі бенчмарк DELEGATE-52. Ён імітуе доўгія працоўныя працэсы ў 52 прафесійных сферах — ад праграмавання і бухгалтэрыі да крысталографіі і нотнага запісу. У адным з бухгалтарскіх заданняў мадэль атрымлівала дакумент з рэестрам аперацый некамерцыйнай арганізацыі, мусіла падзяліць яго на файлы па катэгорыях і потым зноў сабраць у адзін хроналагічны дакумент.
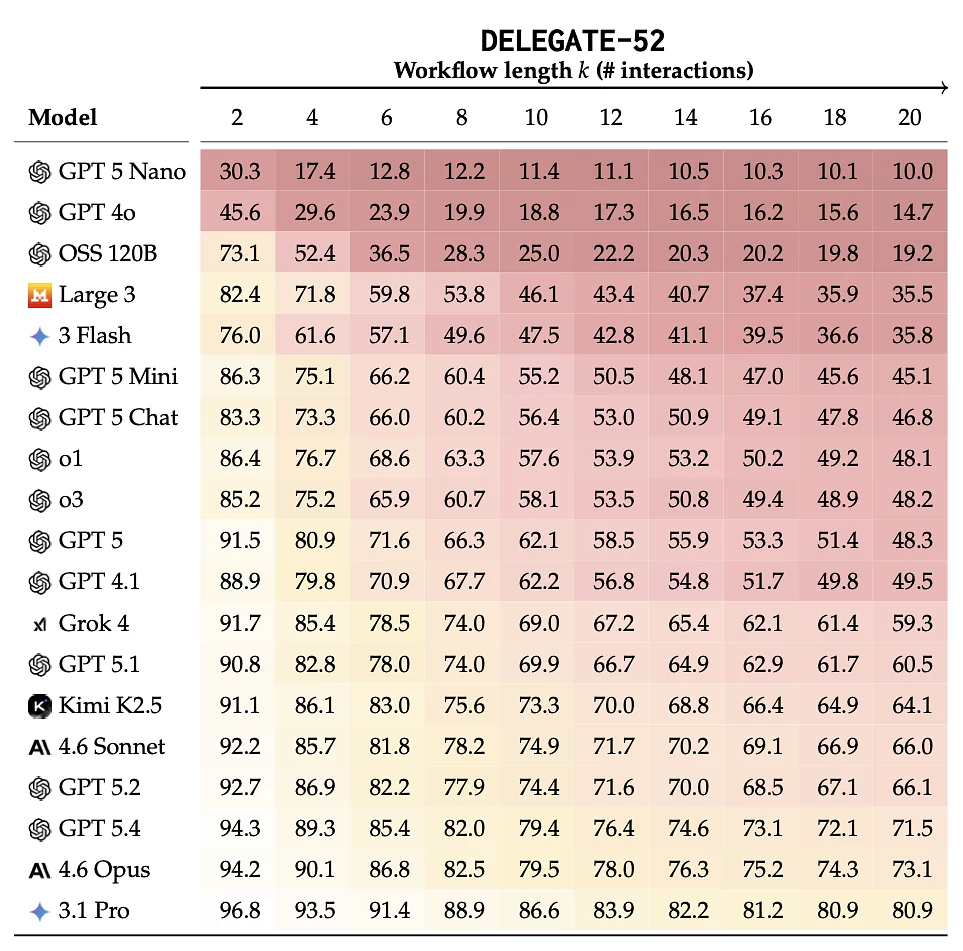
Вынікі бенчмарка DELEGATE-52 для 19 моўных мадэляў пры рознай даўжыні працоўнага працэсу. ШІ-мадэлі губляюць якасць пры працяглых задачах: чым больш узаемадзеянняў, тым мацней дэградацыя дакументаў. Нават лідары тэсту — Gemini 3.1 Pro, Claude 4.6 Opus і GPT-5.4 — адчувальна пагаршаюць вынік пасля 20 крокаў. Крыніца: arXiv.
Вынікі аказаліся трывожнымі. «Нашы высновы паказваюць, што сучасныя LLM дапускаюць істотныя памылкі пры рэдагаванні працоўных дакументаў: францірныя мадэлі Gemini 3.1 Pro, Claude 4.6 Opus і GPT-5.4 у сярэднім губляюць 25% змесціва дакумента за 20 дэлегаваных узаемадзеянняў, а сярэдняе пагаршэнне па ўсіх мадэлях складае 50%», — пішуць даследчыкі.
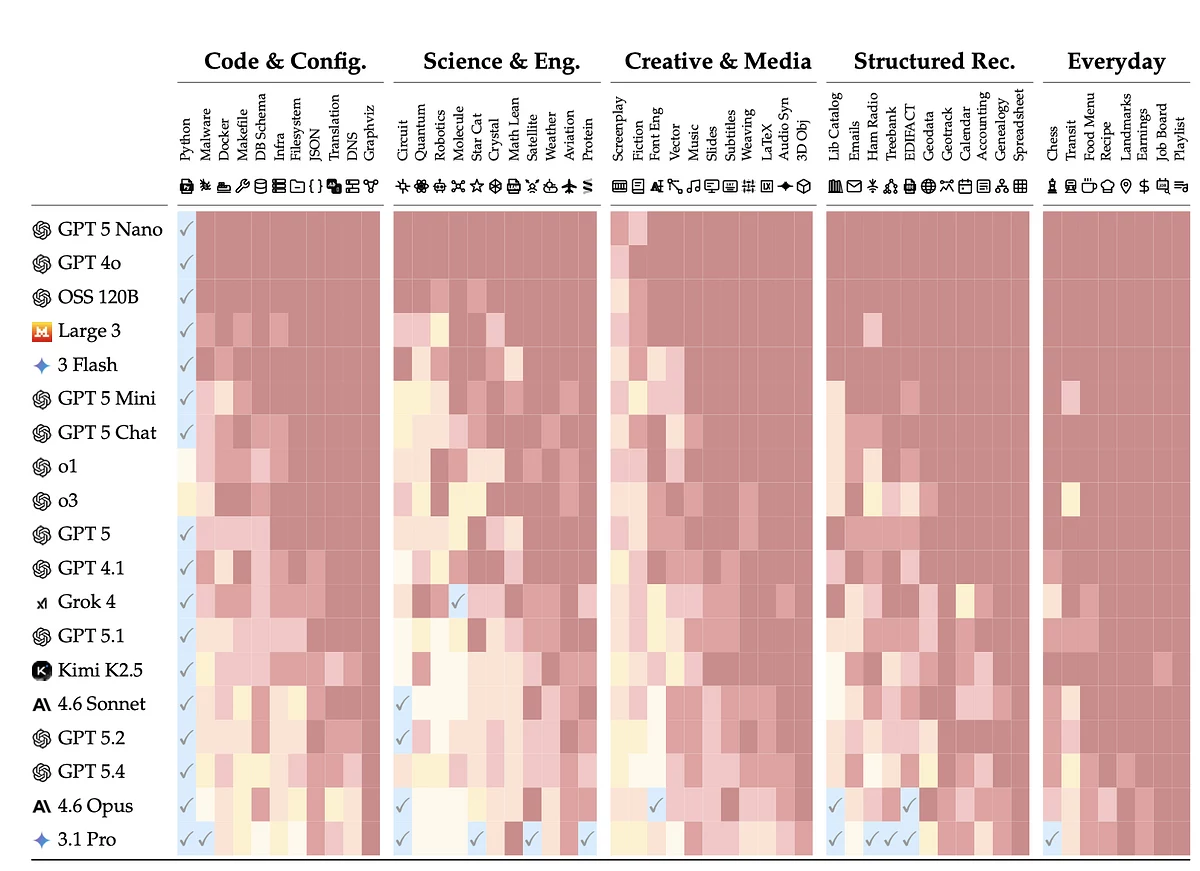
Найлепш мадэлі справіліся з праграмаваннем, горш — з задачамі на натуральнай мове. Каб лічыць мадэль гатовай да канкрэтнай прафесійнай вобласці, аўтары вызначылі парог: не менш за 98% якасці пасля 20 крокаў. Гэты крытэрый вытрымала толькі адна сфера — праграмаванне на Python.
Фінальныя вынікі DELEGATE-52 пасля 20 ўзаемадзеянняў у 52 прафесійных сферах. Колеравая шкала паказвае ступень дэградацыі дакумента: пазнака ✓ азначае гатоўнасць да дэлегаванага працоўнага працэсу пры выніку ≥ 98%, а чырвоныя адценні — істотнае пашкоджанне змесціва. Крыніца: arXiv.
Ва ўсіх астатніх сферах мадэлі аказаліся не гатовыя да дэлегаваных працоўных працэсаў. «Разбіўка выніковых вынікаў па сферах паказвае, што мадэлі не гатовыя да дэлегаваных працоўных працэсаў у пераважнай большасці выпадкаў: у 80% нашых сімуляваных сцэнарыяў мадэлі сур’ёзна псавалі дакументы — прынамсі на 20%», — адзначаюць аўтары.
Цікава, што слабейшыя мадэлі часцей проста выдалялі частку змесціва, а больш магутныя мадэлі хутчэй скажалі, чым выдалялі дадзеныя. Памылкі пры гэтым не назапашваліся паступова: часта яны ўзнікалі раптоўна за адзін раўнд узаемадзеяння і адразу зніжалі вынік на 10–30 балаў.
«Больш магутныя мадэлі — Gemini 3.1 Pro, Claude 4.6 і GPT-5.4 — не лепш пазбягаюць дробных памылак; яны адкладаюць крытычныя збоі на пазнейшыя раўнды і перажываюць іх у меншай колькасці ўзаемадзеянняў», — падкрэсліваюць аўтары.
Anthropic: Claude шантажуе, бо вы ўсе занадта шмат пішаце пра «злы» ІІ
Потым даследчыкі праверылі, ці дапамогуць агентныя інструменты: доступ да чытання і запісу файлаў, а таксама выкананне кода праз базавую агентную абвязку. Вынік аказаўся горшым, а не лепшым. «Чатыры пратэставаныя мадэлі працуюць горш у агентным рэжыме з інструментамі, чым без іх, атрымліваючы дадатковае сярэдняе пагаршэнне на 6% да канца эмуляцыі», — пішуць навукоўцы.
Гэта ставіць пад сумнеў частку маркетынгавых абяцанняў вакол ШІ-агентаў. Іх галоўная мэта — дэлегаваць задачу сістэме, а не выконваць яе самому. Але калі агент на доўгай дыстанцыі псуе чвэрць дакумента, карыстальніку ўсё роўна даводзіцца ўважліва правяраць яго працу.
Выданне The Register іранічна адзначае: стажора, які сапсуе чвэрць дакумента падчас доўгага працоўнага працэсу, хутчэй за ўсё хутка б звольнілі. Пры гэтым кампаніі актыўна інвестуюць у ШІ-аўтаматызацыю: паводле дадзеных Deloitte, арганізацыі ў сярэднім выдаткоўваюць на яе 36% сваіх лічбавых бюджэтаў.











Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.