Новы бенчмарк ацэньвае не разумнасць мадэляў, а колькасць лухты, якую яны дазваляюць сабе скарміць
Даследчык з кампаніі Arena Пітэр Госцеў прыдумаў новы бэнчмарк для ШІ з назвай BullshitBench. Ён правярае, ці ўмеюць моўныя мадэлі распазнаваць бессэнсоўныя пытанні і адмаўляцца на іх адказваць, замест таго каб упэўнена несці бязглуздзіцу.
Даследчык з кампаніі Arena Пітэр Госцеў прыдумаў новы бэнчмарк для ШІ з назвай BullshitBench. Ён правярае, ці ўмеюць моўныя мадэлі распазнаваць бессэнсоўныя пытанні і адмаўляцца на іх адказваць, замест таго каб упэўнена несці бязглуздзіцу.
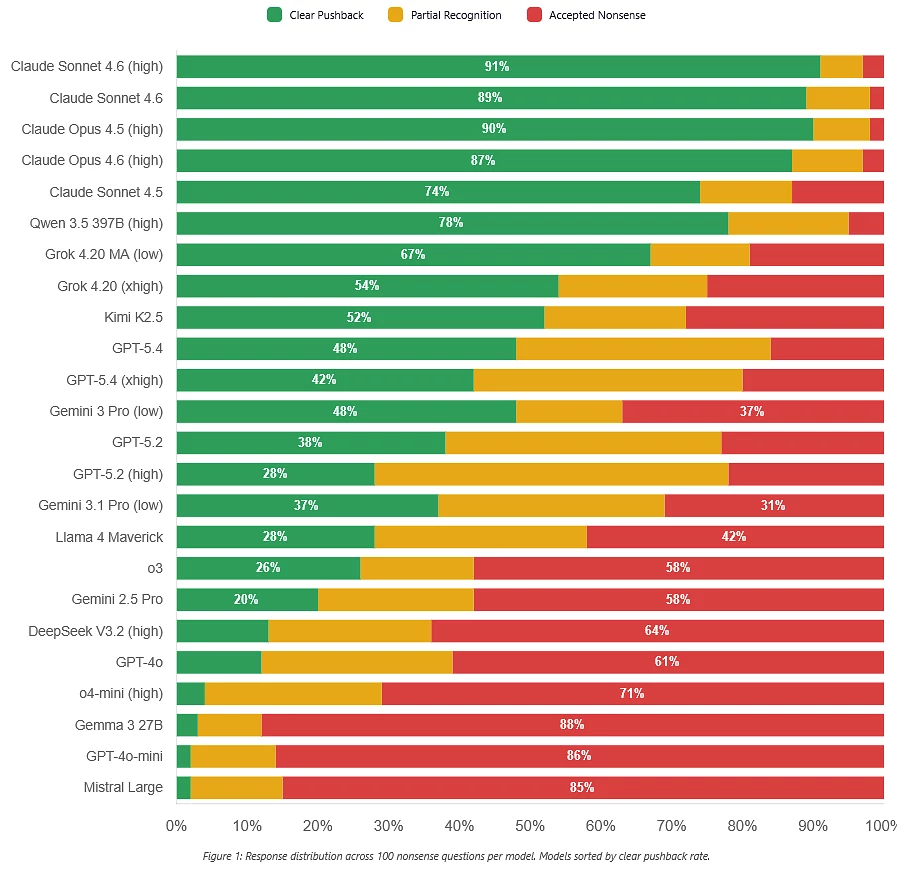
Мадэлям даюць псеўдатэхнічныя пытанні, якія гучаць разумна, але разваліваюцца пры найменшай праверцы логікі. Правільны адказ ва ўсіх выпадках — прама паказаць, што пытанне некарэктнае, і не будаваць доўгія адказы на падставе фальшывай перадумовы. Але многія мадэлі ўсё роўна спрабуюць разумнічаць. Гоцеў думаў, што прыдумаць пытанні, якія падмануць мадэлі, будзе складана, але атрымалася амаль з першай спробы.
Адзін з нечаканых вынікаў — «разважальныя» мадэлі часта паказваюць сябе нават горш. Замест таго, каб сказаць «пытанне некарэктнае», яны пачынаюць яшчэ больш актыўна пераасэнсоўваць яго так, каб усё ж такі даць нейкі адказ. Гэта значыць, яны трацяць намаганні не на праверку сутнасці пытання, а на тое, каб абавязкова на яго адказаць. Gemini 3.0, напрыклад, давала ўпэўнены адпор менш чым у палове выпадкаў.
Гэта ўказвае на больш глыбокую праблему: сучасныя мадэлі могуць выдатна вырашаць складаныя задачы па праграмаванні ці матэматыцы, але правальвацца ў тым, што для чалавека з’яўляецца базавым навыкам — здаровым сэнсе і здольнасці зразумець, што сама пастаноўка задачы абсурдная. BullshitBench паказвае разрыў паміж «здольнасцямі» і «меркаваннем»: ШІ-індустрыя, магчыма, занадта засяродзілася на складаных задачах з вымяральнымі адказамі і менш — на базавай праверцы адэкватнасці ўваходных дадзеных.
Пры гэтым не ўсе мадэлі паказалі дрэнныя вынікі. Сістэмы Anthropic у гэтым тэсце спраўляюцца значна лепш і часцей адмаўляюцца адказваць на бессэнсоўныя пытанні. На думку Госцева, гэта можа быць звязана з тым, што Anthropic робіць вялікую стаўку на якасць базавых мадэляў, а не толькі на reasoning-падыход.







Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.