Google знайшла спосаб трэніраваць АІ у 13 разоў хутчэй і ў 10 разоў энергаэфектыўней
Падраздзяленне Google DeepMind распрацавала новы метад навучання штучнага інтэлекту, які павышае эфектыўнасць сістэмы і зніжае энергаспажыванне. Высокае спажыванне энергіі пры навучанні АІ-мадэляў — адная з галоўных праблем галіны, якая хутка развіваецца.
Падраздзяленне Google DeepMind распрацавала новы метад навучання штучнага інтэлекту, які павышае эфектыўнасць сістэмы і зніжае энергаспажыванне. Высокае спажыванне энергіі пры навучанні АІ-мадэляў — адная з галоўных праблем галіны, якая хутка развіваецца.
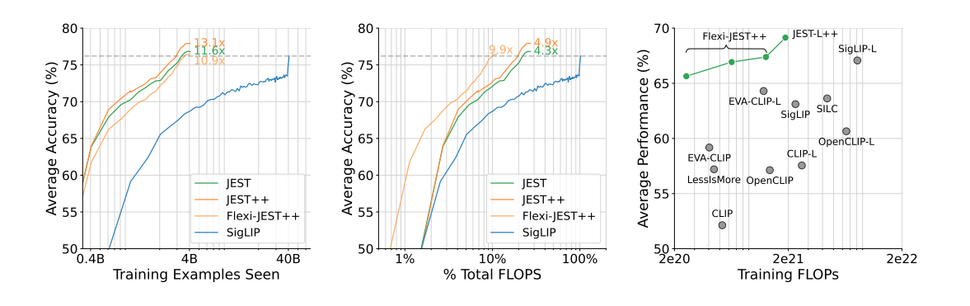
Новы метад навучання называецца JEST (Joint Example Selection). Паводле даных апублікаванага даследавання, тэхналогія забяспечвае 13-кратнае зніжэнне колькасці ітэрацый пры навучанні мадэлі і 10-кратнае зніжэнне энергаспажывання ў параўнанні з існымі метадамі. Аднак метад JEST з’яўляецца значна складанейшым для распрацоўшчыкаў, чым большасць іншых, паколькі для атрымання зыходных даных для навучання спатрэбяцца высокія даследчыя навыкі.
Новы падыход заснаваны на навучанні цэлым пакетам даных, а не асобнымі часткамі. Па-першае, JEST стварае меншую мадэль AI, якая ацэньвае якасць даных і ранжыруе пакеты паводле іх якасці. Затым яна параўноўвае ацэнку з наборам больш нізкай якасці і вызначае пакеты, якія найбольш падыходзяць для навучання. Нарэшце, вялікая мадэль навучаецца на самых якасных дадзеных, адабраных меншай мадэллю.
Метады JEST апярэджвае SigLIP — вядучы метад навучання мадэляў на парах «выява — тэкст» па хуткасці і эфектыўнасці FLOPS, а таксама ў параўнанні з мноствам іншых метадаў. Крыніца: Google DeepMind.
Перавага такога метаду — у значным зніжэнні энергаспажывання, якое з’яўляецца адной з асноўных праблем пры распрацоўцы АІ. Напрыклад, у 2023 годзе нагрузкі АІ складалі каля 4,3 ГВт электраэнергіі. Чым большая мадэль — тым больш энергіі яна затрачвае: адзін запыт ChatGPT спажывае ў дзесяць разоў больш энергіі, чым звычайны пошукавы запыт Google.
Тэхналогія JEST дазваляе зніжаць энергаспажыванне АІ-мадэлі пры захаванні бягучай прадукцыйнасці. Эксперты мяркуюць, што ўкараненне тэхналогіі можа аказаць значны ўплыў на індустрыю, паколькі выдаткі на навучанне мадэляў могуць дасягаць сотняў мільёнаў долараў. Напрыклад, на навучанне GPT-4 было выдаткавана каля $100 мільёнаў. Будучыя мадэлі могуць запатрабаваць яшчэ большых інвестыцый.
Это всё прекрасно. Но где же результаты? Модели, которая в прикладном использовании дотягивала хотя бы до GPT 3.5 - до сих пор нету. Подчеркну, не в оценках на датасетах, а именно в реальном использовании под нужды пользователя. Да и изначально у гугла было вычислительных мощностей больше. Так, может быть, проблема не в том?
Карыстальнік адрэдагаваў каментарый 11 ліпеня 2024, 22:16






Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.
Это всё прекрасно. Но где же результаты? Модели, которая в прикладном использовании дотягивала хотя бы до GPT 3.5 - до сих пор нету. Подчеркну, не в оценках на датасетах, а именно в реальном использовании под нужды пользователя. Да и изначально у гугла было вычислительных мощностей больше. Так, может быть, проблема не в том?
Карыстальнік адрэдагаваў каментарый 11 ліпеня 2024, 22:16