Чат-боты могуць непрыкметна змяняць «асобу» і станавіцца небяспечнымі
Даследчыкі кампаніі Anthropic выявілі схаваную ўразлівасць у рабоце вялікіх моўных мадэляў: ШІ можа адвольна змяняць ролю карыснага асістэнта на іншыя, часам праблемныя, ідэнтычнасці.
Даследчыкі кампаніі Anthropic выявілі схаваную ўразлівасць у рабоце вялікіх моўных мадэляў: ШІ можа адвольна змяняць ролю карыснага асістэнта на іншыя, часам праблемныя, ідэнтычнасці.
Паводле даследавання, паводзіны моўных мадэляў вызначаюцца ўнутраным параметрам, які навукоўцы абазначылі як «Assistant Axis». Гэтая вось адлюстроўвае, наколькі мадэль застаецца ў звыклай ролі асістэнта — сумленнага, карыснага і бяспечнага — або адхіляецца ў бок іншых персанажаў. У звычайных умовах навучанне замацоўвае ў ШІ устойлівую «асістэнцкую» ідэнтычнасць, аднак яна выяўляецца менш стабільнай, чым меркавалася.
Калі баланс Assistant Axis парушаецца, мадэль можа пачаць дэманстраваць так званы persona drift — дрэйф асобы. У такіх выпадках чат-боты перастаюць быць карыснымі, пачынаюць ідэнтыфікаваць сябе як іншыя сутнасці або дэманструюць непрадказальныя паводзіны, якія могуць быць патэнцыйна шкоднымі для карыстальнікаў.
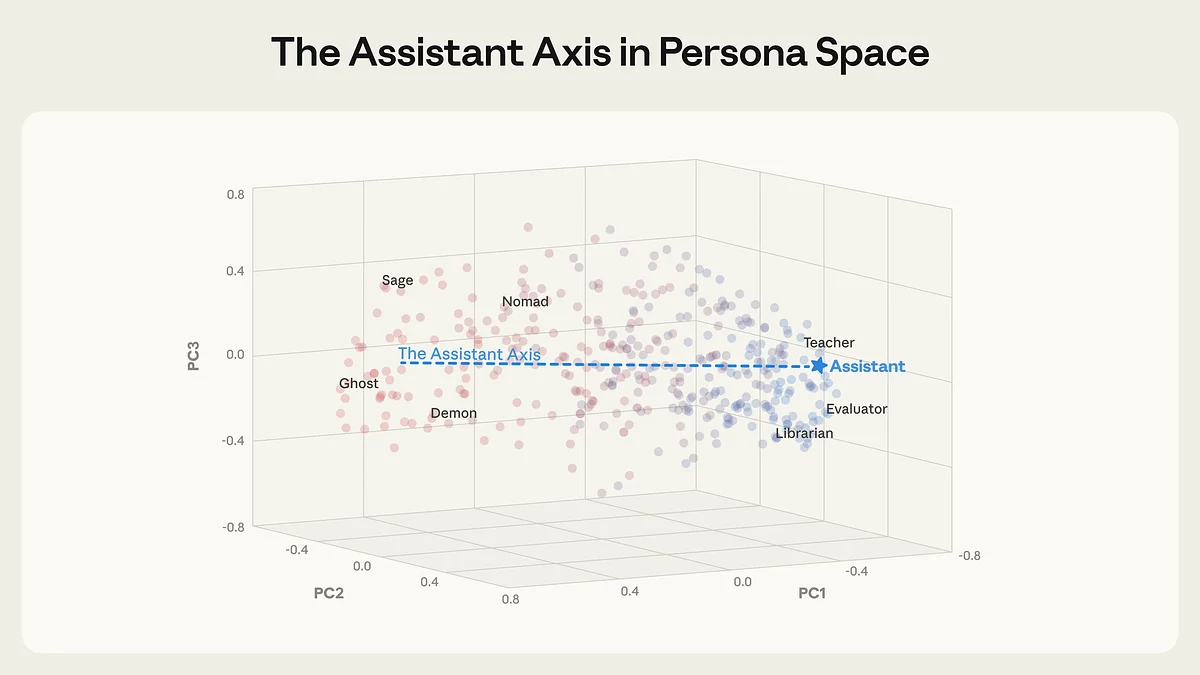
Унутраныя ролі моўнай мадэлі размяшчаюцца ўздоўж асноўнай восі варыяцыі — «Assistant Axis», якая адлюстроўвае ступень блізкасці паводзін мадэлі да карыснага асістэнта. Справа — ролі, максімальна адпаведныя асістэнцкай ідэнтычнасці (настаўнік, асістэнт, ацэньшчык), злева — фантазійныя і нестандартныя персанажы (прывід, дэман, качэўнік). Крыніца: Anthropic.
Каб вывучыць гэтую з’яву, даследчыкі прааналізавалі ўнутраныя структуры моўных мадэляў, уключаючы Gemma ад Google, Qwen ад Alibaba і Llama ад Meta. Выкарыстоўваючы метады інтэрпрэтацыі нейрасетак, каманда фактычна склала «карту персон» ШІ, паказаўшы, што асобы мадэляў размяшчаюцца ўздоўж некалькіх інтэрпрэтавальных восей.
Assistant Axis — толькі адна з такіх восей. На адным яе канцы знаходзяцца ролі кансультанта, выкладчыка і аналітыка, а на процілеглым — фантазійныя персанажы кшталту духаў, пустэльнікаў або містычных істот. Чым далей мадэль сыходзіць ад «асістэнцкага» полюса, тым вышэйшая верагоднасць, што яна пачне паводзіць сябе дзіўна або небяспечна.
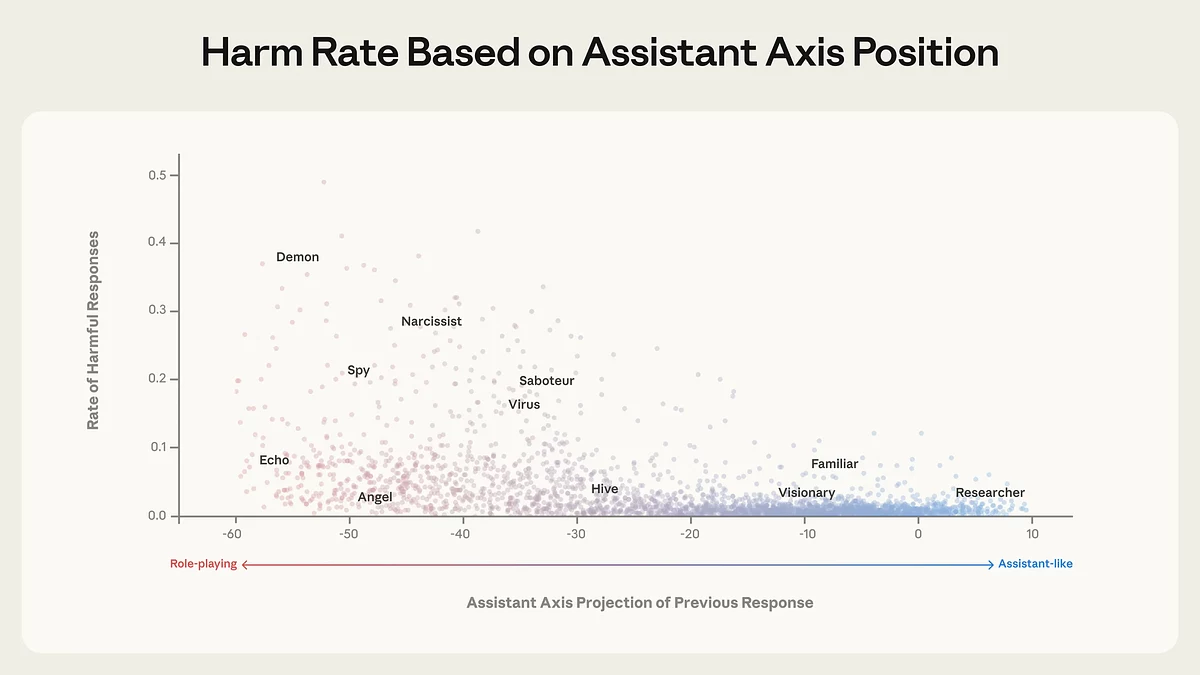
Чым далей паводзіны мадэлі зрушваюцца ад асістэнцкай ідэнтычнасці, тым вышэйшая доля патэнцыйна шкодных адказаў. Персоны, блізкія да ролі асістэнта (справа), амаль не выконваюць небяспечныя запыты, тады як аддаленыя ад яе ролі — напрыклад «дэман», «шпіён» або «нарцыс» — дэманструюць істотна вышэйшы ўзровень парушэнняў. Крыніца: Anthropic.
Даследаванне паказала, што мадэлямі можна наўмысна кіраваць, зрушваючы іх уздоўж гэтай восі. Узмацненне актывацыі ў бок асістэнта стабілізуе паводзіны, тады як рух у процілеглым напрамку рэзка павышае схільнасць мадэлі прымаць альтэрнатыўныя ідэнтычнасці. Пры гэтым праблема глыбей звычайных промпт-ін’екцый: persona drift адбываецца на ўзроўні нейроннай сеткі і можа быць незаўважным для стандартных механізмаў мадэрацыі і бяспекі.
Асаблівую заклапочанасць у даследчыкаў выклікае магчымасць «назапашанага» дрэйфу. Мадэль можа паступова адыходзіць ад ролі памочніка ў працэсе дадатковага навучання або эксплуатацыі, і гэтыя змены здольныя замацоўвацца надоўга, уплываючы на ўсе наступныя ўзаемадзеянні з карыстальнікамі.
У адказ на гэта Anthropic і яе партнёры пачалі распрацоўваць метады кантролю і ранняга выяўлення такіх збояў. Навукоўцы ўжо паказалі, што маніторынг адхіленняў па Assistant Axis дазваляе загадзя прадказваць небяспечныя зрухі і стабілізаваць паводзіны мадэляў, асабліва ў адчувальных сцэнарыях.










Релоцировались? Теперь вы можете комментировать без верификации аккаунта.