
На грунце курса па адміністраванні EMC Data Domain наш калега Кузьма Пашкоў зрабіў вялікі агляд пра віды дэдуплікацыі, архітэктуру сістэм капіявання і аднаўлення на прыкладзе прадуктаў СМС, зрабіў агляд прадуктаў СМС, падрабязна спыніўся на Data Domain, а таксама зрабіў агляд курса па адміністраванні Data Domain.
Чаму Data Domain такой дарагой? Чаму гэта не сістэма захавання дадзеных (СЗД)? Што трэба ведаць пра праектаванне/пуска-наладцы/наладзе/тэхдакументацыі гэтых сістэм? На што зважаць? — на гэтыя і іншыя пытанні дадзены вычэрпныя адказы.
Сям'я тэхналогій і прадуктаў Backup Recovery Solutions
Мне, як інжынеру, не сорамна казаць пра тое, што гэты прадукт добры, бо з усіх пералічаных аналогаў — Data Domain з'явіўся на рынку першы, наколькі я помню. Па выніках выпрабаванняў і конкурсаў абіраюць менавіта гэты вырашэнне. Ужываць у дачыненні да гэтага комплекса нават самай найнізкай лінейкі панятак «стары» можна вельмі ўмоўна, бо тэрмін жыцця ў гэтых вырашэнняў складае 5-7 гадоў, што вельмі нямала.
Пачнём з патрэбных уводзін па сістэмах захоўвання ЕМС. Як я разумею, вы ўжо не першы раз сутыкаецеся з прадукцыяй кампаніі СМС, і помніце што СМС, VMware, RSASecruity – гэта адзін кангламерат. Таму прадукцыю ўсіх гэтых карпарацый можна разглядаць у рамках адзінай наменклатуры, не ў сэнсе кіравання кампаній, а ў тым сэнсе, што ўсе гэтыя прадукты інтэгруюцца адзін з адным. У гэтым дасягнута вельмі глыбокая ступень інтэграцыі. Мы будзем разглядаць толькі прадукты кампаніі ЕМС. Нас цікавіць тая яе частка, якая завецца Backup Recovery Solutions. Частка гэтых вырашэнняў яна, як бы запазычаная, за кошт паглынутых кампаній. Прыкладам, галаўны прадукт, які завецца Networker – паўнавартасны сродак рэзервовага капіявання карпарацыйнага класа, які б'ецца са сваімі канкурэнтамі на гэтым рынку – адкуль ён? – з кампаніі Legata, якая з канца 80-х гадоў гэты прадукт распрацоўвала, цяпер гэта ўжо ЕМС.
Далей, той прадукт, які мы з вамі збіраемся вывучыць – Data Domain – была аднайменная кампанія, якая першая на рынку выпусціла падобны праграмна-апаратны комплекс для захоўвання рэзервовых архіўных копій, СМС яе паглынула. Наступны – Avamar. Я адмыслова пералічу галоўныя прадукты, таму што яны ўсе адзін з адным узаемазвязаны. Avamar – так раней звалася кампанія з Каліфорніі, якая зноў жа выпускала сродкі рэзервовага капіявання карпарацыйнага класа з дэдуплікацыяй на крыніцы, вельмі спецыфічнае вырашэнне, якое рэвалюцыянізавала стратэгію рэзервовага капіявання, прадукт раней зваўся Axion, калі я слушна помню. І яшчэ ёсць Data Protection Adviser, наконт гэтага прадукту я не помню ці было гэта распрацоўкай СМС, ці гэта было паглынанне кампаніі.
Насамрэч гэта не поўны спіс, чаму я пералічыў усе гэтыя прадукты? Для таго каб сказаць вам пра тое, што гэта ўсё частцы адзінага цэлага – ужо цяпер, на двары 2015 год, СМС у прайс-лістах, у працы сваіх прэсэйлаў, пазіцыянуе ўсе гэтыя прадукты як часткі адзінага пакета прадуктаў у рамках Backup Recovery Solutions – адзіны прадукт, які дазваляе ўніфікаваць абарону любых дадзеных, якія могуць сустрэцца ў кожнай карпарацыі. З'яднаўшы гэтыя прадукты ўжо на працягу доўгага часу, СМС навучыла гэтыя прадукты вельмі глыбока інтэгравацца. Networker можа працаваць як сам, так і частку функцый дэлегаваць на Data Domain ці Avamar, Avamar можа наўпрост інтэгравацца з Data Domain без Networker, а могуць усё разам працаваць у адной «ражцы-лейцы». Пра Data Protection Advisor– зусім асобная гутарка.
У звязку з гэтым, на курсах па гэтых прадуктах няможна пра гэта не казаць, таму як значная частка функцыяналу завязана на вось гэту інтэграцыю. Калі казаць пра наш Data Domain, то ў ім значная частка функцый ужо гадамі не змяняецца – таму што там усё ўжо даўно добра, яшчэ да паглынання. Але пасля, вялікая частка ўдасканаленняў злучана з тым, што Data Domain павінен умець «сябраваць» са сваімі «братамі», каб гэта стала адзіным цэлым. Калі разглядаць кожны прадукт па асобнасці – тое гэта набор функцый, ці паслуг. Але калі гэтыя прадукты інтэгруюцца, то гэта не матэматычнае складанне функцый, з'яўляюцца нейкія ўнікальныя звыш-уласцівасці, пра якія няможна не казаць. Нават на нашым курсе, які першы ў спісе аўтарызаванага навучання, мы пра гэтыя функцыі будзем досыць шмат казаць. Таму гэтыя рэчы трэба пазіцыянаваць: што ёсць што і якую ролю займае. Прадукты буду пералічваць і апісваць у вызначаным, не выпадковым, парадку.
Спачатку пагавару пра Networker. Гэта галаўны прадукт – ядро сістэмы абароны дадзеных у частцы сістэмнага капіявання і архівавання. З грунту – гэта класічнае шматзвёнавы кліент-серверны сродак рэзервовага капіявання, праграмны комплекс. Дыстрыбутыў, элементы, звёны якога раскладваюцца на: рэзервовыя копіі ў выглядзе кліентаў, серверы рэзервовага капіявання ў выглядзе вузлоў захоўвання, да якіх падлучаны нейкія сховішчы, якія злучаны з кліентамі нейкім асяроддзем перадачы дадзеных. Няхай гэта будзе LAN ці SAN, штосьці ў гэтым духу. І ёсць майстар-сервер, які мы завём бэкап-каталогам. Ёсць цэнтралізаваныя сродкі, дзе ёсць сервер, вядучы адзіны ўлік рэзервовых копій, носьбітаў інфармацыі, на якіх яны трапілі, дзе захоўваюцца палітыкі рэзервовага капіявання, правіла, якое аўтаматызуе ўвесь гэты працэс. Фактычна, на гэтым звяне, якое завецца – Networker сервер, саміх цел рэзервовых копій не захоўваецца, толькі іх улік і кантроль. Сюды «торкаюцца» размаітыя адмінскія кансолі і да т.п. Сувязь усіх звён ажыццяўляецца, натуральна па пратаколе ТСР/IP праз лакальную сетку, праз глабальную сетку – не важна. Нас, натуральна, цікавіць пытанне руху трафіка рэзервовага капіявання.
Вось у нас крыніца рэзервовых копій – якая-колечы, і ў нас destination. Як ужо было сказана, сродкі рэзервовага капіявання Networker – карпарацыйнага класа, гэта значыць, што яно ўмее адлучаць адно ад іншага. Трафік рэзервовага капіявання можа перадавацца па вылучаных сегментах – інтэлектуальна і ўсвядомлена. Звычайная лакальная ethernet-сетка або які-кольвек сторедж эрыа нэтўорк, што працуе па fiberchannel — кожны спосаб сувязі. Гэта значыць, што Networker ведае, што такое LAN Free Backup, чулі пра такі, так? Што яшчэ можа рабіць Networker? Прыкладам, бэкапіць крыніцу рэзервовых копій не нагружаючы яго. Адменна шырыцца не буду, гэта завецца serverless ці proxy backup. Тое, што я пералічваю гэтыя функцыі, гэта не значыць, што іх толькі Networker можа рабіць, гэта значыць, што ён імі валодае як і яго канкурэнты. Networker можа бэкапіць NASы, за кошт таго, што ведае, што такое NDMP, пратакол NDMP freeware backup – хто не ведае што гэта такое? Гэта рэалізацыя lanfree serverless для вылучаных файлавых «памыйніц». Networker, спарадзіўшыся ў 1989 годзе, мае доўгую гісторыю і яго матрыца сумяшчальнага ПА і абсталявання – вельмі вялікая. Ён вылічаны на гетэрагенную сетку, у яго ў крыніцах можа быць што заўгодна, вельмі вялікая матрыца сумяшчальнасці: розных АС і бізнес-праграм, якую ён можа бэкапіць без прыпынку, тое што завецца анлайн-бэкап, у яго велізарную колькасць розных інтэграцый, улучаючы розныя Microsoft і іншыя.
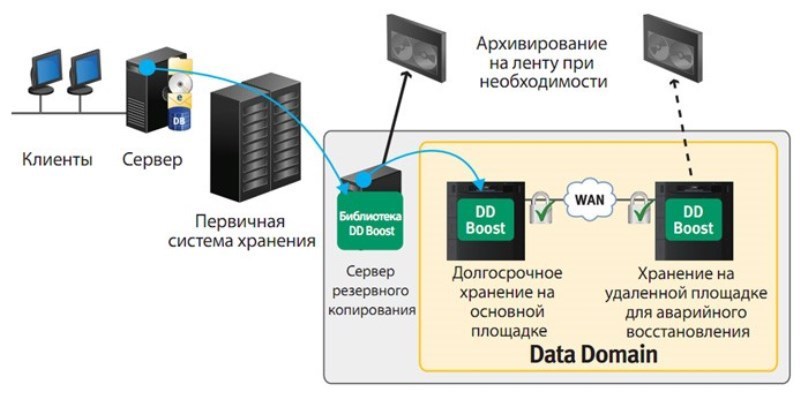
Традыцыйна, Networker, у якасці рэзервовых копій скарыстоўваў рабатызаваныя стужкавыя бібліятэкі перадусім – у гэтым ён досыць добры, у яго матрыца сумяшчальных бібліятэк вельмі вялікая. Ніхто не кажа, што ён не можа бэкапіць на дыскі – зразумела, можа! Але мы ведаем, што на дысках захоўваць бэкапы – задорага, асабліва пры бягучых аб'ёмах. Я гэта кажу да таго, што спрадвечна Networker быў вылічаны на работу са стужкавымі бібліятэкамі і дагэтуль з імі найлепей працуе. І для традыцыйнага падыходу да абароны датацэнтраў – гэта цалкам нармальна. Эканамічна лёгка давесці дамэтнасць выкарыстання Networker для абароны баявых сервераў, якія сядзяць у ЦАДзе: усялякія Ораклы, Сіквела, сервера праграм, велізарныя дадзеныя, якія ў межах ЦАДа, па высакахуткаснай, вылучанай нейкай сетцы, мы ганяем на якія сховішчы рэзервовых копій. Усё добра, але Networker, так ужо атрымалася, ведае, што такое дэдуплікацыя, але не ўмее яе самастойна выконваць. Не таму, што пра гэта не падумалі распрацоўнікі, а таму, што да таго моманту нехта ўжо ўмеў гэту дэдуплікацыю рабіць. Таму, калі вы хочаце для нейкай часткі крыніц рэзервовых копій арганізаваць эфектыўны струменевы сціск, то ў якасці аднаго са мноства сховішчаў, з якім можа працаваць Networker, вы можаце скарыстаць Data Domain, таму што гэта фактычна, дыскавая паліца з вінчэстарамі, з нейкай, будзем лічыць, апаратнай дэдуплікацыяй, якая дазваляе вельмі эфектыўна сціскаць струмені рэзервовых архіўных копій, якія валяцца на гэту паліцу.
Адпаведна, у гэтай скрыні ёсць маса інтэрфейсаў, пра якія мы будзем казаць падрабязна. Думка застаецца ранейшай – адзіны гаспадар, адзіны ўлік рэзервовых копій, частка з іх валіцца на нейкія традыцыйныя сховішчы, а частка валіцца на сховішча з дэдуплікацыяй, дыскавай дэдуплікацыяй. Трэба разумець, што дэдуплікацыя – гэта не панацэя і эканамічна дамэтна скарыстаць яе ў цэлым, і вось такія прадукты ў прыватнасці. Калі мы скарыстаем традыцыйны падыход – стужкі, адчужальныя носьбіты з паслядоўным доступам, то там хуткасць аднаўлення, як ты не здзекуйся, будзе мерацца гадзінамі. Калі гэты паказнік Recovery Time Objective трэба звесці да нейкага прымальнага мінімуму – то трэба захоўваць рэзервовыя копіі на дысках – але гэта дорага, таму давайце ўжываць дэдуплікацыю, калі яна дастасоўная, ведама ж – крыніца рэзервовых копій можа быць з супрацьпаказаннямі да сціску – не ціснецца, і ўсё, і хоць забіся. Тут адразу ж прыходзіць у галаву слушная думка: калі кажуць пра выкарыстанне чаго-небудзь з дэдуплікацыяй, патрабуецца абследаванне аўтаматызаванай сістэмы заказцы ў рамках нейкай методыкі і абгрунтаванне – ацэнка гэтага дасяжнага каэфіцыента. Калі абследаванні няма – што вы можаце чакаць? Нехта кажа, што ён можа «гарантаваць» нейкі каэфіцыент сціску – дзіўна гэта чуць! Ведама ж чысты маркетынг. А ў рэальным жыцці не так усё проста.

Data Domain можа выконваць дэдуплікацыю самастойна, саматугам, марнуючы свае працэсарныя цікі, сваю працэсарную сілу, аператыўную памяць — не напружваючы крыніцу. Гэта вельмі добра. DD можа прымаць струмені рэзервовых копій праз LAN, праз ethernet – 10 гігабіт, 40 гігабіт заяўлена. А можа пры патрэбе дэлегаваць частку функцый, злучаных са сціскам, на саму крыніцу – калі гэта дазволена. Інтэрфейсаў у Data Domain шмат — для прыняцця адначаснага струменя мноства рэзервовых архіўных копій, але самы эфектыўны – ліцэнзійны інтэрфейс DD Boost, гэты пратакол і Data Domain неадлучныя. DD можа выкарыстоўвацца без DD Boost, але гэты сам інтэрфейс можа скарыстаць толькі ў DD.
Data Domain эканамічна дамэтны, гэта лёгка давесці, скарыстаць для абароны, усё ж сервераў, якія седзячы ў ЦАДзе, якія злучаны з DD нейкім агульным, высакахуткасным асяроддзем перадачы дадзеных, гэта не VAN, гэта LAN ці SAN. Ізноў жа, гаворка ідзе толькі пра серверы, для якіх дазволена дэдуплікацыя, а калі няма, тады патрэбныя дыскі. Вось такая проза жыцця, увогуле.
Баявыя серверы, для якіх дэдуплікацыя не дастасоўная, для якіх паказнік RTO не такі жорсткі, іх цалкам нармальна бэкапіць на рабатызаваныя стужкавыя бібліятэкі і г.д. Ёсць крыніцы рэзервовых копій, для якіх паказнік RTO крытычны, іх трэба мець магчымасць хутка аднаўляць, гэтага патрабуе палітыка бяспекі і для іх няма супрацьпаказанняў дэдуплікацыі – купілі Data Domain і сказалі Networker’у частку струменяў рэзервовых копій з гэтых крыніц накіроўваць на такія сховішчы
А што рабіць з трэцяй катэгорыяй крыніц рэзервовых копій і самай шматлікай? – з працоўнымі месцамі? І калі іх злучаюць са сховішчам ненадзейныя каналы сувязі? То працуюць з перабоямі, то прапускная здольнасць слабая і г.д. Бэкапіць іх традыцыйным спосабам і з дэдуплікацыяй на сховішчы – бескарысна, вельмі нязручна. Тут СМС кажа, ок, у нас ёсць вось такі прадукт — Avamar, які канчаткова ж можа быць скарыстаны аўтаномна – і для абароны і сервераў ён пасуе, і для абароны чаго заўгодна. Але яго асаблівасць у тым, што ён заўсёды выконвае сціск на крыніцы. Спачатку, напружваючы крыніцу, уціскаючы, наколькі гэта магчыма, дадзеныя, падлеглыя рэзервоваму капіяванню, а потым толькі ўжо ў сціснутым выглядзе перадае ўнікальную дэльту, копію ў нейкае сховішча. Avamar, у часткі інтэграцыі, можа працаваць з усімі прадуктамі сямейства, можа таксама вельмі эфектыўна працаваць пад кіраваннем Networker.
Улічваючы, што яно ўсё адзін з адным інтэгруецца, усе катэгорыі крыніц рэзервовых копій абараніць – можна тэхналогіямі ад адзінага пастаўшчыка. Засталося толькі што? – карэляцыя падзей, якія адбываюцца ў гэтых складаных праграмна-апаратных комплексах, з падзеямі, якія адбываюцца на сеткавым абсталяванні, сховішчах, сістэмах захоўвання дадзеных і г.д. Для таго, каб адпавядаць тому, што завецца SLA, другое для таго, каб можна было арганізаваць billing. Ідэя вельмі простая – усе вышэйпералічаныя прадукты, па асобнасці, і ў сукупнасці, яны то, што завецца cloud ready. Гэта значыць, што з іх можна пабудаваць воблачны сэрвіс рэзервовага капіявання і здаваць яго ў арэнду. Я – аператар, пабудаваў свае сервер-ЦАДы, паставіў туды гэтых прадуктаў і здаю вам, як юрасобам у арэнду. Каб вам гарантаваць ровень якасці абслугоўвання і кожнаму выстаўляць рахункі, па меры выкарыстанні маёй інфраструктуры патрэбен білінг. Для арганізацыі гэтай часткі нам патрэбен такі прадукт – Data Protection Adviser (DPA), дарадца. Гэта асобны праграмны комплекс, кліенты якога ставяцца на ўсе крыніцы інфармацыі, у якога ёсць цэнтралізаваная БД, куды збіраецца ўся інфармацыя, дзе яна семантычна ўзбуйняецца, спраўджваецца з нейкай БД сігнатур нейкіх падзей. Ну і далей сядзіць нехта, глядзіць на манітор, і яму паказваецца чырвоным колерам – усё дрэнна, ці яму паказваецца, даюцца рады – што рабіць? І ён або піша справаздачы, або рахункі выстаўляе начальству — выдатная рэч.
З чаго складаецца Data Domain
Я пералічыў не ўсе модулі адзінага модульнага прадукту, бо часу ў нас незашмат. Але калі ёсць тыя, хто хоча сабе паказнік RTO звесці да нуля. Ёсць прадукт Recover Point, які зноў жа з усімі інтэгруецца, у прыватнасці з Networker, якія рэалізуюць канцэпцыю бесперапыннай абароны.
У нашым курсе акцэнт будзе зроблены на малую частку гэтага праграмна-апаратнага комплексу – толькі Data Domain. Але заўсёды мы будзем казаць пра яго ў святле інтэграцыі з іншымі прадуктамі з сямейства, або ад пабочных вытворцаў, што таксама не праблема.
Сярод вас шмат дасведчаных хлопцаў, хто ўжо працаваў з канкурэнтамі Data Domain. Калі паспрабаваць вызначыць, што такое Data Domain, тое магчыма атрымаецца так: дыскавае сховішча дэдуплікацый для захоўвання рэзервовых, архіўных копій. Не больш і не менш. Гэта вельмі важны момант. Гэта не СЗД, параўноўваць яе з чымсьці такім няма ніякага сэнсу. Таму што тое — сховішча для захоўвання працоўных дадзеных, для якіх профіль нагрузкі, у агульным то, як бы ўніверсальны: там магчыма і паслядоўнае чытанне, запісы, і адвольныя чытанне, запісы. Там гэтыя сур'ёзныя паказнікі iops, тыя, хто працуе з СЗД гэта ведае. У СЗД, якія б яны ні былі: слабога, сярэдняга, высокага класа – пры ўсіх іншых роўных, ёсць нейкая агульная архітэктура. Фронтэнд, ёсць нейкі кэш, бек энд, ёсць збоеўстойлівасць, мультыпафінг і таму падобнае. Data Domain – гэта не СЗД, ніколі яго так не завіце – гэта грэх:)
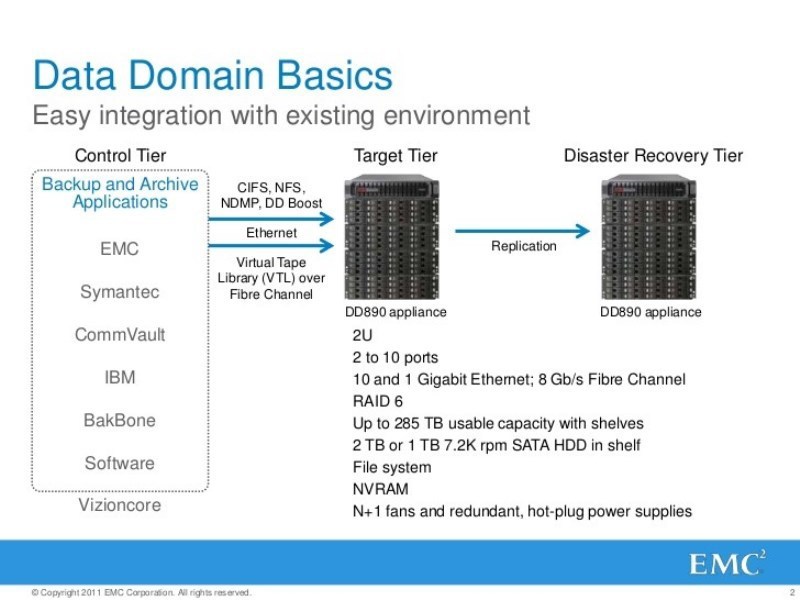
Data Domain – гэта сервер. Калі я бяру гэта жалеза, то я бачу праграмна-апаратны комплекс, ёсць апаратная частка у выглядзе сродкаў вылічальнай тэхнікі, праграмная частка ў выглядзе сістэмнага ПА, гэта АС, есці нейкае там ужытковае ПА.
Апаратная частка гэта што? Інтэлаўскі чыпсэт, памяці як мага больш, пара блокаў сілкавання, там ёсць шына PCI express, колькі слотаў, у сістэмную плату ўбудавана 4 сеткавых карты з гігабітавымі інтэрфейсамі і 2 медзяных з 10 гігабітамі. Па змаўчанні ўжо ёсць больш за1 надмерных сеткавых інтэрфейс для падлучэння да навакольнага асяроддзя, каб прымаць кіроўны трафік, каб прымаць струмені рэзервовых копій і выдаваць струмені аднаўлення. Ужо добра. У слоты мы можам уторкнуць яшчэ сеткавых карт, у залежнасці ад мадэляў, магутнасць таксама можа быць абмежавана чыпсэтам. Можна ўторкнуць fibre channel host bace adapter, праўда за асобныя грошы, я бачыў такі адаптар 4-х і 8-мі гігабітавы, 16-гігібітавы нехта бачыў? Я бачыў, што іх заяўлялі, як і 40-гтгабітныя ethernet’ы, але пакуль яшчэ іх няма, іх можна чакаць.
Што яшчэ на шыне ёсць? Там па змаўчанні ужо стаіць дыскавы кантролер, SAS і не адзін, іх павінна быць 2. На шыне якіх вісяць нейкія дыскі, дыскавы масіў. У малодшых Data Domain мадэлях гэта адкрыта ў корпусе самага сервера, які мантуецца ў стойку. Колькі там вінчэстараў? Мінімум – 7, максімум – 15. Калі ў вас мадэль Data Domain больш сур'ёзная, вы можаце на шыну SAS-кантролераў, яшчэ дадаць адну ці трохі дыскавых палок. У дыскавых палках круцяцца, раней гэта быў убогія sata-вінчэстары, цяпер гэта NL SAS-вінчэстары. Чым NL SAS ад SAS адрозніваецца? NL SAS – гэта як танны SAS (саташный “вінт”, зроблены праз SAS шыну, хуткасць памену павялічылі, але саму архітэктуру вінчэстэра пакінулі як і было). SAS, груба кажучы, гэта старое добрае scsi. NL SAS – гэта сасаўскія вінчы, якія па выніках вытворчасці не прайшлі нейкіх жорсткіх выпрабаванняў на прадукцыйнасць, надзейнасць, але маюць нейкі прымальны ровень, таму яны ідуць танней. Груба кажучы, у сасаўскіх вінаў час напрацоўкі на адмову ў разы больш чым у NL SAS. Я кажу не пра прадукцыйнасць, а пра надзейнасць. Гэтыя вінчэстары, якіх шмат, дзясяткі ці сотні, яны, натуральна ў нейкія рэйд масівы сабраны. (Кожная паліца збіраецца ў асобны рэйд масіў) гэта яшчэ завуць дыскавы групы (жалезных кантролераў там няма, фактычна гэта софтавы рэйд, гэта ані дрэнна ані добра, проста гэта так працуе, і ў кожнай паліцы яшчэ дадатковы дыск hot spare). Я бачыў, што ў head парачка дыскаў вылучана пад АС. (Раней такога не было, цяпер у больш старэйшых мадэлях Data Domain выкарыстоўваецца 4 дыска для гэтай Data Domain АС. Яны вынесены асобна, там змяшаныя рэйды). Там карысныя дадзеныя не захоўваюцца, там толькі службовыя.
Калі ўспомніць логіку пабудовы рэйд 6 масіваў, якія там стратныя выдаткі? Адна лагічная аперацыя запісу нейкага блока дадзеных – гэта колькі фізічны аперацый (я кажу пра iops)? 3 чытанні + 3 запісы. То бок стратныя выдаткі – дзікія! У 6-га рэйду стратныя выдаткі самыя вялікія, у 5-га менш: 2 чытанні + 2 запісы. Дыскавая сістэма ў гэтым серверы – вельмі павольная, таму мы ўспамінаем пра тое, што мы казалі, што гэта – не СЗД.
АС – гэта нейкая лінукс-падобная аперацыёнка, завецца DD OS (Data Domain Operating System). У агульным выпадку, для звычайнага кастамера, спажыўца яна даведзена да непазнавальнага выгляду – традыцыйных шэлаў там няма. Там прасцяцкі камандны інтэрпрэтатар, з нейкай сістэмай камандаў з простым сінтаксісам. І калі ты не інжынер, а служба тэхпадтрымкі, і інжынернага доступу не маеш – то забудзься пра большасць вядомых табе юніксавых камандаў і ўтыліт. У якасці дадатку будзе тэрмінал размаітых дэманаў: Daemon VTL, Deamon DDBoost, Deamon NTP, Deamon NFS і гэтак далей. Камплект якіх убудаваны ў гэты дыстрыбутыў лінукса, каб праз размаітыя гэтыя пратаколы роўня дадатку прымаць/аддаваць струмені рэзервовых копій.

Чаму Data Domain такі дарагі?
Добра, тады пытанне чаму Data Domain такі дарагі? Што тут такога асаблівага ў частках, з чаго я не магу сам сабраць? Не бяром у разлік маркетынг і г.д., калі ўзяць у разлік тэхнічную частку – у адным са слотаў PCI стаіць адна ці некалькі адмысловых плат, якія завуцца NVRAM платы. Спецыялізаваная плата, з нейкім аб'ёмам аператыўнай памяці ў чыпе, 1 гігабайт, 2, 4 гіга, з нейкім, будзем лічыць, спецыялізаваным мікрапрацэсарам. Гэта тая самая плата, з дапамогай якой вось гэтыя струмені ўваходных рэзервовых архіўных копій, з дапамогай цэнтральнага працэсара – уціскаюцца. Тая самая плата, дзе праходзіцца тая самая дэдуплікацыя. Гэта тое, што дазваляе старэйшым мадэлям DD «жэрці» у гадзіну дзясяткі тэрабайт нейкіх дадзеных. Уявіце сабе 10 тэрабайт у гадзіну ўваходны струмень, і якая павінна быць прадукцыйнасць дыскавай падсістэмы, сабранай з NL SASов у рэйдзе 6? Ды іх там павінна быць вар'яцкая колькасць!
Але як у старэйшых так і ў малодшых мадэлях Data Domain дыскавая падсістэма па прадукцыйнасці не адрозніваецца. Сумарная колькасць iops’аў, якую яно можа выдаваць – яно застаецца маленькім. Абсалютна неадэкватным таму набору функцый, якія патрабуюцца для такога аб'ёму дадзеных. Усе гэтыя «пякельныя» тэрабайты сціскаюцца на ўваходзе да прымальнага роўня, і да дыскавай падсістэмы даходзіць толькі прымальная нагрузка. Тэхналогія дэдуплікацыі, дакладней яе рэалізацыя ў Data Domain, запатэнтавана.
Калі злятаць у Каліфорнію, у Санта-Клару, дзе гэта падраздзяленне, цяпер гэта завецца Data Protection and Availability Division, былы BRS, то там у холе, ёсць «зала славы», дзе вісяць усе гэтыя патэнты, іх копіі. А гэта дарагое задавальненне, вы, купляючы Data Domain, сплачваеце ўсе гэтыя патэнты, уладальніку патэнта, за яго супер-распрацоўку, якая ў вызначанай частцы трымаецца ў сакрэце, мы пра гэта таксама пагаворым пазней. Не хачу сказаць, што ў іншых вендараў аналагічных тэхналогій няма, але парадак цэн такі ж як і на Data Domain. Усе яны б'юцца на ўсе жылы за спажыўца. Асноўны канкурэнт – HP Storeonce і IBM Protectier.
То бок Data Domain будзе выглядаць так: сервер, з паліцамі ці без паліц, падлучаны праз ethernet толькі, ці і праз ethernet і праз fiberchannel, прымае струмені рэзервовых копій праз мноства размаітых пратаколаў. Атрымваецца, што асноўнай канкурэнтнай перавагай гэтага прадукту, у ісце з'яўляецца дэдуплікацыя.
Дэдуплікацыя
З гэтым трэба разабрацца каб ісці далей. Прыкладна кажучы – гэта сціск. У чым іста сціску – зменшыць аб'ём дадзеных. Толькі калі кажуць «сціск» у агульным выпадку, то маюць на ўвазе, што мы шукаем паўторныя наборы дадзеных і замяняем іх на нейкія спасылкі, у нейкім лакальным наборы дадзеных. Калі мы кажам «дэдуплікацыя» — то гаворка ідзе пра глабальны сціск, я шукаю не толькі паўторныя дадзеныя на гэтай крыніцы рэзервовых копій, а ўвогуле ўсюды, на ўсіх ўвогуле крыніцах рэзервовых копій.
Адпаведна ў нас дэдуплікацыя можа выконвацца на розных роўнях абстракцыі. Тое, што я расказваю не новае, але гэта трэба, каб казаць у адным і тым жа слоўніку.
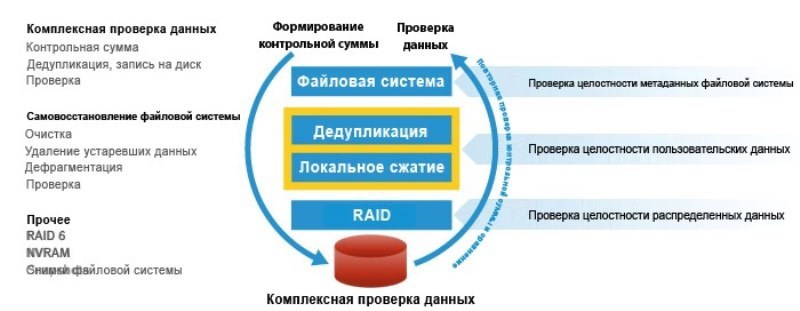
1) Filebased. На ўзроўні файлаў. Вы ўсе бэкапіце на мяне нейкія дадзеныя, а я шукаю нейкія паўтаральныя файлы. Прыйшоў нейкі файл ад некага, высветлілася, што ён мне ніколі не сустракаўся, ён унікальны – я паклаў яго ў сховішча. Выдаткаваў нейкія рэсурсы, месца ў сховішча, каб цела гэтага файла там змесцаваць. Ад некага прыйшоў яшчэ адзін асобнік гэтага ж файла, я нейкім чынам у гэтым пераканаўся. І заміж таго каб марнаваць рэсурсы, я захоўваю метаінфармацыю што такі файлік сустракаецца вось там і вось там. І стратныя выдаткі будуць на 2 парадку менш, заміж таго каб захоўваць цела файла ў сховішча.
А як спраўджваць файлы? Самы просты спосаб – гэта пабітавае спраўджанне, яго няможна скідаць з рахункаў, у вызначаных выпадках ён эфектыўнейшы за разлік эталоннай характарыстыкі, хэшы і г.д. Таму ніколі гэта не выпускайце, я пра гэта раскажу крыху пазней. У большасці сістэм рэзервовага капіявання выкарыстоўваецца такі падыход: давайце мы вось гэты набор дадзеных прагонім праз нейкую функцыю, і незалежна ад таго, які памер выточнага набору дадзеных, мы атрымаем нейкі хэш, эталонную характарыстыку фіксаванага памеру. І ў рамках вось гэтай матэматычнай залежнасці ў нас будзе вызначаная гарантыя таго, што калі ў выточным наборы памяняецца адзін біт, вынік хэшавання будзе абсалютна іншай. Я адмыслова ўздымаю гэта пытанне, у навучальных матэрыялах курса вы гэтага не ўбачыце, каб вам сказаць наступнае: так, функцыя хэшавання мае прамое дачыненне да сіметрычнай крыптаграфіі, гэта асобны клас матэматычных функцый. І для іх актуальная праблема калізій. Імавернасць таго, што ў розных набораў дадзеных будзе адзін і той хэш – не нулявая. Але яе можна звесці да прымальнага мінімуму. І для тых выпадкаў, калі гэтыя калізіі здараюцца нейкімі кампенсавальнымі мерамі гарантаваць, што цэласць дадзеных не будзе парушана. Я адмыслова гэта агучваю, таму што, у прыватнасці, у Data Domain, распрацоўнікі гэтаму пытанню надалі ўвагу, і даюць матэматычную гарантыю, довад таго, што гэтыя калізіі не праблема, і з імі спраўляюцца з дапамогай кампенсавальных сродкаў.
У гэтым выпадку ўсе ўнікальныя наборы дадзеных маюць унікальныя хэшы. Калі адбываюцца калізіі – гэтым можна пагрэбаваць. Гэта даказана, гаворка ідзе пра запатэнтаваную тэхналогію, не са столі гэта ўзята. Які алгарытм, што правяраць ці не правяраць – мы не ведаем. Я адмыслова паўтаруся, алгарытм дэдуплікацыі (ён вялікі, калі намаляваць схему – пакоя не хопіць) гэта ўлічвае. І пра гэта кажуць распрацоўнікі.
Гэта тэхналогія, так бы мовіць «тупая», але дай бог калі можна атрымаць каэфіцыент сціску ў 1,5-2 разу. Гэта сярэдні паказнік, але чакаць тут хоць чагосьці – вельмі складана. Нават калі ў вас у якасці крыніцы рэзервовых копій нейкая файлавая «памыйніца», шмат паўтаральных файлікаў.
2) Калі ў мяне ў прыёрыцеце каэфіцыент сціску, то давайце шукаць не файлы, а блокі дадзеных фіксаванай даўжыні. Давайце ўсе дадзеныя, што нам валяцца крышыць на фіксаваны кавалачкі, звычайна ў кілабайтах. Для кожнага кавалачка вылічваем хэш, і спраўджваем з хэшамі тых кавалачкаў, чые целы ляжаць у нашым сховішчы. Ёсць трапленне – ок, ён захаваўся, не будзем яго захоўваць, няма траплення – гэта кавалачак унікальны, пара яго змясціць у сховішча.
Гэты падыход добры чым: што мазгоў не патрэбна шмат улучаць. Але ён найлепей працуе для крыніц рэзервовых копій, дзе дадзеныя ўжо структураваныя. Калі той набор дадзеных, дзе мы шукаем змененыя блокі, ужо спрадвечна ў яго ўносяцца змены фіксаванымі транзакцыямі, фіксаванага памеру, то гэта вельмі зручна. Панядзелкам былі адны блокі, то аўторкам блок вось такой і вось такой памяняўся. Калі аўторкам сродак рэзервовага капіявання пакрышыць гэты файлік на кавалачкі фіксаванага памеру, ён строга лакалізуе змены.
Каэфіцыенты сціску, якія можна дасягнуць пры гэтым падыходзе ўжо больш. У сярэднім гэта можа быць 2-5 разоў. Але тут важна, каб крыніца задавальняла вызначаным вымогам, дзе дадзеныя ўжо структураваны і змены робяцца фіксаванымі трансакцыямі вызначанага памеру. Найчасцей гэта СКБД. Для такіх дадзеных выдаюцца добрыя паказнікі. А калі неструктураваны вінегрэт? Алгарытм не зможа лакалізаваць гэтыя змены, таму што там усё зрушваецца.
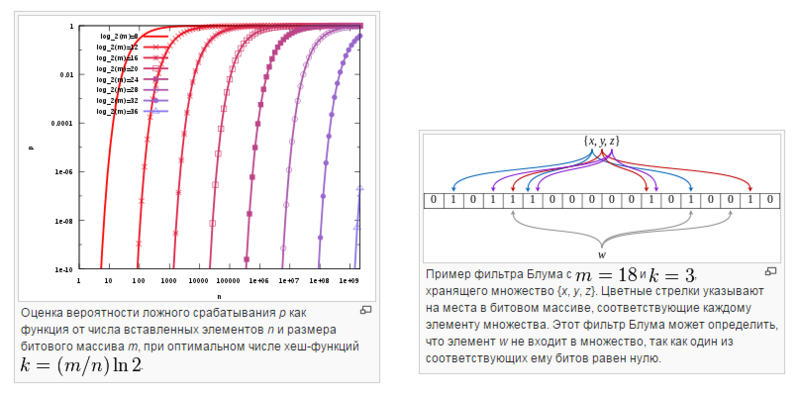
3) Таму ёсць алгарытм дэдуплікацыі на блокі дадзеных варыятыўнага памеру. Іста гэтага алгарытму — лакалізаваць змены. Нават калі спачатку ці ў сярэдзіне файлік памяняўся, сістэма зразумее, што гэта толькі гэтыя блокі памяняліся, а астатнія засталіся ранейшымі. Звычайна такія алгарытмы скарыстаюць дадзеныя, блокі якіх вар'іруюцца 4к-32к. Ёсць гарантыя таго, што калі выточны набор дадзеных не памяняўся, то вынік яго «крышылава» будзе адным і тым жа. І ён зможа лакалізаваць толькі змененую частку дадзеных. Усе алгарытмы падобнага роду – запатэнтаваны. Яны ўсе трымацца ў сакрэце. З грунту, гэта ўсё варыяцыі таго, што завецца фільтр Блуму – калі захочаце свой матэматычны апарат напружыць. Таму частка патэнтаў у Санта-Клары, яны пра гэта. Пра запатэнтаваную рэалізацыю сістэмы тэарэм. Нехта рэальна напружыў свой мозг.
Зараз, калі казаць зусім пра дэдуплікацыю, на якім ўзроўні абстракцыі яе лепш выконваць? 1-ы, 2-і, 3-і спосаб… не, няслушна, няма «слушнага» адказу. Прыкладны слушны адказ гучыць так: ідэальны сродак рэзервовага капіявання павінен умець выконваць дэдуплікацыю на ўсіх роўнях абстракцыі, падладжваючыся пад асаблівасці крыніц рэзервовых копій.
Па-простаму: у мяне файлавая «памыйніца», неструктураваная інфармацыя бэкапіцца? Давайце я спачатку хутка, нікога не напружваючы: знайду паўтаральныя файлікі і іх выкіну, тыя якія ўнікальныя – добра, пачну крышыць. Калі гэта файлік – цела БД, то я яго буду на структураваныя файлікі крышыць вызначанага памеру, калі неструктураваныя блокі – тое на блокі дадзеных варыятыўнага памеру. Таму што заўсёды даводзіцца шукаць кампраміс паміж каэфіцыентам сціску і стратнымі выдаткамі, нагрузкай на гэты сціск.
Трэба вылічваць гэтыя хэшы, трэба іх спраўджваць, а гэта напружвае некага, мы пакуль не ўдакладняем каго. І чым больш нагрузка, тым больш паказнік акна рэзервовага капіявання. Даводзіцца шукаць нейкі кампраміс. Чым лепш сціснулася, тым павольней будзе нейкі RTO і г.д. Таму кампаніі шукаюць нейкі кампраміс паміж гэтымі параметрамі. І вельмі хацелася б, каб сродак рэзервовага капіявання, з аднаго боку, яму можна было сказаць: ты сам інтэлектуальна разбірайся якую дэдуплікацыю, на якім ўзроўні абстракцыі, для якой крыніцы выконваць. А з іншага боку казаць яму: вось табе такія рамкі.
Прыкладам, для гэтых дадзеных – мне іх трэба максімальна сціснуць, я для гэтага важна каб пры сціску гэта ўкладвалася ў акно рэзервовага капіявання, а для гэтага важны час аднаўлення. Дык вось, Networker у спалучэнні з Data Domain і Avamar і ўяўляе такую інтэлектуальную сістэму рэзервовага капіявання.
Было пытанне наконт Мicrosoft
У Microsoft, у АС, 2012 версіі ў выпадку ўсталёўкі ў ролі файлавага сервера ёсць опцыя, якая рэалізуе дэдуплікацыю блокаў дадзеных якая вар'іруецца доўгія на ўзроўні тома. І там каэфіцыенты 1,5-2%. Калі мы кажам пра Avamar, то ён выконвае дэдуплікацыю на ўсіх 3 роўнях абстракцыі, калі пра Data Domain, тое ён выконвае дэдуплікацыю заўсёды на 3-м роўні блокаў дадзеных варыятыўнай даўжыні. Алгарытм хэшавання, які выкарыстоўваецца – прамысловы – Secure Hash Algoritm, і памер эталоннай характарыстыкі 160 біт.
Ідзём далей. У нас ужо была візуалізавана архітэктура класічнага сучаснага сродку рэзервовага капіявання карпарацыйнага класа – кліент-сервернае, шматзвёнавае. Ёсць мноства крыніц – кліентаў, ёсць нейкае асяроддзе перадачы дадзеных, што злучае гэтыя крыніцы з тым, што завецца медыясерверам, вузлы захоўвання, якія падлучаны да сховішчаў. І есці нейкі бэкап-каталог, які ўсім гэтым дырыжуе.
Дык вось, у часткі датычнай дэдуплікацыі. Яна можа выконвацца кім? Хто гэты герой? Ёсць варыянт postbased. Вось ёсць тэрабайт дадзеных, ён перадаўся праз нейкае асяроддзе на сховішча, у адведзенае бэкап-акно, яно з'ела тэрабайты дадзеных, для гэтага яму трэба шмат шпіндэляў, выдаткавалася месца тэрабайт, а потым ужо пэўна што па-за акном рэзервовага капіявання пачынаецца гэтае сцісканне: на роўні файлаў, блокаў дадзеных фіксаваных і г.д. – але гэтым напружана само сховішча. І вось яно ўціснулася ў 10 раз, 100 гігаў ёсць. Добра гэта ці дрэнна – я не кажу. Прыкладам Windows Server 2012 менавіта так і працуе. VNX працуе падобна, але апошнія мадэлі могуць рабіць дэдуплікацыю, не толькі на роўні файлавых блокаў, але і на роўні лунаў – і ён па сваім раскладзе гэта робіць, і мы эканомім наша дарагое месца.
Ёсць дэдуплікацыя «на ходзе». Тэрабайт прачыталі, перадалі праз асяроддзе перадачы, ніякай эканоміі няма, але перад тым як трапіць у дыскавую падсістэму сховішча, гэты тэрабайт, з дапамогай працэсара, аператыўкі, уціскаецца, і мы прыбіраем гэту вар'яцкую колькасць iops, і атрымваем нейкую іх адэкватную колькасць, якую можна пісаць на дыскавую падсістэму. Не патрэбна шмат шпіндэляў, не патрэбна куча месца. Вось гэта ў нас – Data Domain. Ён гэта можа рабіць праз любыя праграмныя інтэрфейсы.
Трэці варыянт. Дэдуплікацыя на крыніцы. Тэрабайт я прачытаў і тут жа напружыў крыніцу. Яна і так напружаная чытаннем вялікага масіву дадзеных, перадачы іх кудысьці, а тут іх яшчэ трэба сціскаць. Вось даціснула яна гэта да 100 гігаў і ўжо няшчасныя 100 гігаў перадала па сістэме перадачы дадзеных у сховішча. Гэта ўмее рабіць Avamar і Data Domain у выпадку выкарыстання інтэрфейсу DDboost з улучаным функцыяналам DCP. То бок Data Domain ведае, што такое дэдуплікацыя на крыніцы. Самае цікавае, што ён ведае і што такое пост дэдуплікацыя, першы тып, пра які мы казалі. У Data Domain ёсць час, калі ён сам з сабой разбіраецца, і вось гэта таксама мяркуе postbased дэдуплікацыю.
Тое мноства струменяў, якія валяцца на Data Domain, ён іх крышыць, на кавалачкі варыятыўнага памеру, вылічвае іх на хэшы, спраўджвае іх масівы. Але ёсць матэматычная гарантыя таго, што для 99% гэтых кавалачкаў, ён зможа зразумець, ўнікальныя яны ці не. А для 1% ён гэтага не зможа зрабіць у час. Лічыце, што ён гэтыя кавалачкі кудысьці пакладзе, каб паспець, а потым іх яшчэ пастфактум дацісне. Як і чаму гэта здараецца я вытлумачу потым. У гэтым няма нічога дрэннага, гэта ніхто не дэкларуе, але ніхто ад гэтага і не адмаўляецца. Тыя сведчанні прадукцыйнасці для кожнай мадэлі Data Domain, якія выкладзены на сайце СМС – гэта не чыстай вады маркетынг. Яны зрабілі лабараторыю, праграму методыкі выпрабаванняў, жывой Data Domain паставілі, і сталі на яго штосьці бэкапіць і дасягнулі гэтых вынікаў, строга іх памералі. Зразумела, што пры выкананні вызначаных умоў, магчыма нават ідэальных, але ніхто не абяцае манну нябесную. Усё кажуць: праводзьце даследаванні, абгрунтоўвайце, давядзіце заказцу, што менавіта такі каэфіцыент будзе атрыманы, такая хуткасць паглынання будзе атрымана ў яго сітуацыі – і вось гэта прадавайце.

Тое, што я расказваў – гэта які-ніякі лікбез па сродках рэзервовага капіявання. education.emc.com – партал навучання, вы пэўна пра яго ведаеце, добра туды заходзіць часцей. Ёсць выдатны курс Backup Recovery Systems and Architecture, займае 40 гадзін. Курс па асновах рэзервовага капіявання і архівавання, там пра вось гэту шматзвёнавасць, пра serverless проксі бэкапы, дэдуплікацыю, там шмат чаго напісана. Курс насамрэч універсітэцкі, чытаецца на старэйшых курсах тэхнічных вну, партнёраў акадэмічнай праграмы СМС, магістрам выкладаецца, у рамках другога вышэйшага. У піцерскім палітэху, у маскоўскіх вну я такі курс чытаў. Курс сам сабою вельмі цікавы, я адмыслова пра яго кажу, таму што было б пажадана, каб кожны з вас хоць бы яго прагартаў і паглядзеў. Таму што белыя плямы ў адукацыі ёсць ва ўсіх. Займаючыся больш 10 гадоў сістэмамі абароны, я думаў, што на гэтым сабаку з'еў, што мяне ўжо нічым не здзівіць – але ж не. 5 дзён – 40 гадзін, толькі пра вось гэтыя асновы.
Ідзём далей. На сайце СМС у падзеле абароны дадзеных я гляджу наменклатуру прадуктаў. Пад абаронай дадзеных маецца на ўвазе іх цэласць і даступнасць перадусім. Не прыватнасць! Калі гаворыцца пра кожныя сакрэты гэта сыходзім у RSASecurity. У мяне тут ёсць тузін прадуктаў і ў падзеле backup recovery у мяне ёсць СМС Data Protection Suite – гэта і ёсць адзіны праграмна-апаратны комплекс для абароны ўсіх катэгорый дадзеных.
Я хачу паглядзець на мадэлі Data Domain і паглядзець на іх характарыстыкі. Мадэляў вельмі шмат, на кожны густ і каліту. Хачу паглядзець самую слабую мадэль — Data Domain DD160. У ёй ёсць 7 дыскаў па змаўчанні, або можна пашырыць да 12. Архітэктура ва ўсіх мадэляў Data Domain аднолькавая, але ў тых, што танней ёсць вызначаныя абмежаванні. Прыкладам, паліцу не дадасі – абмежавана магчымасць маштабавання, шмат сеткавых інтэрфейсаў там не паставіш, hostbased адаптараў. І вось configuration maximum – 160 мадэль гатова сумарна паглынаць струмені рэзервовых копій з хуткасцю да 1 тэрабайт/гадзіна. Як інтэрпрэтаваць гэты паказнік? Пры ўмове, што струмень ідзе праз ethernet і DDboost, DCP улучаны, з дэдуплікацыяй на крыніцы. Калі няма DDboost, то можаце адважна дзяліць на 2: уваходны і выходны. DDboost ужо працуе шмат з кім, нават HP Data Protector умее з ім працаваць, Netbackup даўно ведае, Backup Exec даўно ведае – гэта прамысловы стандарт, таму што іншых альтэрнатыў не прыдумалі.
Што такое 195 тб Logical capacity? Як гэта інтэрпрэтаваць? То бок да сціску амаль 200 тб, а ёмістасць у яго 1,7. Які патрэбен каэфіцыент сціску? Калі груба акругліць – у 20 раз? У мяне ёсць заказцы, у якіх: у 3 разу паціснулася – крута!
Супрацьпаказання
Чаму я на гэта зважаю – яшчэ раз кажу – усё залежыць ад дадзеных. Калі казалі пра дэдуплікацыю, я адмыслова не памянуў пра супрацьпаказанні. Калі, прыкладам, у мяне дадзеныя зашыфраваны, спрадвечна пададзены ў выглядзе крыптаграмы, а я іх бэкаплю. Якія мы атрымаем каэфіцыенты сціску? Алгарытмы шыфравання і алгарытмы кампрэсіі – з адной катэгорыі матэматычных функцый. Яны робяць прыкладна адно і таксама, але мэты ў іх розныя. У адных забяспечыць прыватнасць, а ў іншых зменшыць іх аб'ём. Усё што зашыфравана – супрацьпаказана для сціску, бо пасля яго дадзеныя зоймуць яшчэ больш месца.
Добра, калі дадзеныя сціснуты ўжо. Медыядадзеныя, усё што заўгодна. Якіх каэфіцыентаў можна чакаць? Можна чакаць, але тут усё залежыць ад схемы рэзервовага капіявання. Калі ў мяне ёсць медыя-архіў, аб'ёмам 10 тб, які не ціснецца, але я кожны дзень раблю фул-бэкап, гэта не варыянт – гэтага ніхто не робіць.
Таму трэба выяўляць супрацьпаказанні, там дзе іх няма – праводзіць абследаванні. І вылічаць вось гэты дасяжны каэфіцыент сціску. У нейкай меры яго можна вылічыць эмпірычным шляхам, паглядзець на дадзеныя, у СМС есці статыстыка і сказаць: у 5 раз паціснецца. Ад гэтага можна адштурхвацца. У вас там SQL і Exchange, гэтулькі паштовых скрынак вось такога памеру? Ёсць формула, куды гэта ўбіваеш і атрымваеш вынік.
Усё чапалі Backup System Sizer? Ён дае прыблізную прыкідку. Мае заказцы падзяляюцца на 2 катэгорыі, адны кажуць: напішы нам падрабязна на дакументах, абгрунтуй, тэхнічнае абгрунтаванне і г.д. А іншыя кажуць: нам нічога не патрэбна з дакументаў, але ты асабіста адказваеш за тое, што паабяцаў? У ідэале, вядома, каб адказваць за свае словы, трэба дакладна самаму пераканаецца, што атрымаецца менавіта той каэфіцыент сціску.
Тады лепш зрабіць тое, што не вельмі любяць рабіць інтэгратары: дайце заказцу ў дасведчаную эксплуатацыю хоць слабенькі, хоць б/к, Data Domain. Хай ён там пакруціцца нейкі час, і мы па факце паглядзім, які атрымаўся каэфіцыент. І ўжо ад гэтага будзем адштурхвацца, распрацоўваць тэхніка-камерцыйную прапанову.
Дакументацыя і навучанне
Навошта гэта ўсё. Без этапу праектаванні – не абыйсціся. Нехта павінен правесці абследаванне ў рамках нейкай распрацаванай методыкі, напісаць тэхнічнае заданне на сістэму абароны. План абароны, становішча і катэгараванне інфармацыйных рэсурсаў. План забеспячэння работы, аднаўлення пасля збояў. Усе гэтыя дакументы павінны быць. Нехта павінен ацаніць, сказаць, прыкладам, што вось гэта катэгорыя – там дэдуплікацыя не патрэбна, тут можна – але не нагружаць крыніцу, тут можна, тут такі каэфіцыент, тут такі.
Гэту работу робіць інтэгратар або партнёр, як іх заве ЕМС. У СМС ёсць адмысловая навучальная праграма для архітэктараў, для тых праектуе, для інжынераў-канструктараў. Дзе ўсяму гэтаму вучаць: абследаванню і складанню тэхнічнай дакументацыі. СМС працуе на ўзроўні планеты – у іх усё стандартызавана. Інжынер і ў ЗША і ува Ўкраіне працуе па аднолькавых узорах. Нічога не трэба прыдумляць.
Але, не кожны заказца гэта просіць. Таму калі вы заказца, вы павінны ў інтэгратара прасіць гэты пакет дакументаў. Не даведкавую інфу з сайта, а апісанні тэхналогіі вырабу і абслугоўвання гэтага выраба. Калі вы працуеце ў інтэгратару – усё ёсць, толькі трэба спытаць.
Для пуска-наладчыкаў, тых, хто па дакументацыі вырабляе выраб – ёсць свае курсы навучання, мы на адным з іх знаходзімся. Гэта звычайнае інжынеры з партнёраў і з самога ЕМС.
Доўжачы кастамараў, тых, хто пасля здачы з гэтым працуе і абслугоўвае, ёсць свае курсы – для адмінаў, наш курс таксама можна назваць для адмінаў.
Усё гэта распісана на партале навучанні ЕМС. Нават калі вы кастамер, вам даступна там шмат чаго. Асабіста я магу падзеліцца прыкладамі канструктарскай дакументацыі, таму што з чыстага ліста іх напісаць складана. Таму даводзіцца падтрымваць інжынерную інтэлігенцыю, таму што гаспадары не любяць за гэта плаціць грошы, але гэта патрэбна, таму што гэта асобны выгляд дзейнасці.
Па ўсіх этапах жыццёвага цыкла аўтаматызаванай сістэмы ў частцы яе сістэмы абароны – у СМС ёсць праграма навучання і сертыфікацыі па ўсіх іх прадуктах. Ці будзеце вы іншыя курсы разглядаць – гэта ўжо трэба глядзець.
Адміністраванне СМС Data Domain: уводзіны ў курс
Уводзіны ў нас датычылі асноў сістэм сістэмнага капіявання і архівавання. Мы, фактычна хутка прабеглі ўтрыманне ўніверсітэцкага курса, ці навучальнага 5-дзённага курса па архітэктуры гэтых сістэм. Заадно паглядзелі дэдуплікацыю. Строга пазіцыянавалі Data Domain у наменклатуры прадукцыі ЕМС. Зрабілі высновы – чаго ад яго чакаць і чаго ад яго чакаць не варта – што самае важнае.
З назвы нашага курса выяўна, пра што мы будзем казаць. Калі пагледзіце на нашу мадэль жыццёвага цыкла, то гаворка ідзе пра падтрымку, абслугоўванне, ужо, фактычна гатовай чорнай скрыні. Які нехта: спраектаваў, як ён будзе ўбудоўвацца ў наяўнае або новае асяроддзе, распісаў камплект канструктарска-эксплуатацыйнай дакументацыі. Нехта па гэтым камплекце ўжыццявіў зборку, мантаж, пуска-наладку гэтага выраба, хоць бы ў агульнай частцы і далей гэта было перададзена персаналу заказцы разам з дакументацыяй. Заказца ўжыццяўляе адміністраванне, у малой, вузкай ступені, у нейкім калідоры ён ужыццяўляе даналаду. Але асноўнае заданне гэтага персаналу – маніторынг. Мы спраўджваем бягучы стан гэтай скрыні, з эталонным, якое было зафіксавана на этапе здачы ў эксплуатацыю.
Траблшутынг
Калі бягучы стан не адпавядае эталоннаму – выяўляем прычыну, ухіляем няспраўнасць. І далей усё гэта ідзе па цыкле. Наноў дапрацоўваем ТЗ — версія 2.0. Таму штосьці памянялася, рыскі памяняліся, жыццё памянялася. І па такім цыкле і развіваецца сістэма абароны. Нармальная, спелая кампанія гэты цыкл праходзіць ужо 5-ы ці 7-ы раз, не робячы ўсё з нуля, а развіваючыся. Гэта актуальна для любых іншых вырабаў.
Наш курс – вызначаны праект, ёсць пачатак, ёсць вынік. І таму мне трэба вызначыць межы гэтага праекта: пра што мы будзем казаць, пра што не будзем казаць. Пра праектаванне мы казаць не будзем, бо пра гэта ёсць іншыя курсы. Пра пуск-наладку мы будзем казаць толькі ў частцы, што тычыцца кастамера. Ёсць асобныя курсы для інжынераў СМС і партнёраў-інтэгратараў, дзе распісана: як сабраць вось гэты Data Domain, умантаваць з камплектам паліц у стойку, як адмаркіраваць, далучыць усе гэтыя злучэнні, як ствараць рэйд-масівы, як заліць выяву АС, як ужыццяўляць інжынернае тэхабслугоўванне, якое не дармовае.
Мы, як кастамеры, што гаворыцца, што нам нехта сабраў, прызначыў IP для кіроўнага інтэрфейсу, нехта паставіў пароль убудаванага ўліковіка адміна і перадаў нам гэтыя атрыбуты доступу. І мы ў рамках наяўнай дакументацыі штосьці там дапішам. У нас акцэнт на адміністраванне, у нейкай частцы на наладу.
Раз гэты курс – праект, то помнім, што па выніках гэтага маленькага праекта, у вас павінна быць нейкае разуменне, тэарэтычныя веды, практычныя, зусім пэўныя, навыкі, злучаныя з гэтым вырабам. Гэта значыць, што павінна быць вычэрпнае разуменне пра дэдуплікацыю: якая яна бывае, і як яна пэўна рэалізавана ў пэўным вырабе. Які комплекс запатэнтаваных тэхналогій ёсць, не абавязкова мелы дачыненне да дэдуплікацыі, рэалізаванай у Data Domain, ён стаіць сваіх грошай, каб вы бачылі, што гэта за патэнты.
Як маніторыць гэту чорную скрыню, як ёй кіраваць, праз якія адміністрацыйныя интефейсы да яе можна далучыцца і можна пачаць з ёй штосьці рабіць. Тут і камандны радок і GUI. Як размежаваць доступ да гэтага выраба. Data Domain – гэта шматкарыстальніцкі эплайнс, там шмат людзей павінны мець доступ да яго. Адпаведна трэба размяжоўваць гэты доступ і кантраляваць, няможна дапусціць каб нехта штосьці сапсаваў – гэта дарагое абсталяванне.
Як выканаць initial setup – гэта калі ёсць гатовая чорная скрыня, якую вы канфігуруеце пад сваю структуру. Абапіраючыся на канструктарскую дакументацыю, якую нехта для вас распрацаваў. Прыклад такой дакументацыі ў вас у выглядзе навучальнага дапаможніка для выканання лаб. Той фармат што ў вас для прыкладу – ён ідэальны для такой дакументацыі. Калі вы хочаце для сваіх пуска-наладчыкаў такія дакументы распрацоўваць – рабіце яе ў такім выглядзе, добры прыклад у вас ёсць.
Identify and configure Data Domain data paths – праз якія інтэрфейсы фізічныя, лагічныя, Data Domain можа прымаць струмені рэзервовых архіўных копій – іх вельмі шмат. Давайце іх усё пералічым, і для кожнага іх іх напішам працэдуру налады, правядзём выпрабаванні на стэндзе, каб гэта апісанне адпавядала рэчаіснасці, каб быў нейкі довад. У нас для гэтага ёсць стэнд.
Configure and manage Data Domain network interfaces – наладзім сеткавую падсістэму Data Domain. У самай простай мадэлі надмерная колькасць убудаваных у сістэмную плату сеткавых інтэрфейсаў. Гэта добра, таму што можна забяспечыць, прынамсі, збоеўстойлівасць, інтэрфейсы ломяцца, правады абрываюцца, а яно працуе. А як максімум – агрэгаваць яе прапускную здольнасць, падсумоўваць інтэрфейсы для дасягнення нейкіх вынікаў.
Адна справа — ініцыялізаваць Data Domain, іншая справа – пачаць кідаць на яго нейкія дадзеныя праз розныя інтэрфейсы. Будзем вынікаць з простай логіцы: ад простага да складанага, ад агульнага да дзелі. Спачатку мы будзем чапаць простыя інтэрфейсы, якія лёгка наладжваюцца і не патрабуюць асобных ліцэнзій. А далей усё гэта будзе прыкра ўскладняць. Прыкладам, возьмем і ўнутраную файлавую сістэму Data Domain і пачнём структураваць. З нейкага вялікага кавалка дадзеных зробім структураваную сістэму, каб ёй было зручна кіраваць.
Адна справа — ініцыялізаваць Data Domain, іншую справу пачаць кідаць на яго нейкія дадзеныя праз розныя інтэрфейсы. Будзем вынікаць простай логіцы: ад простага да складанага, ад агульнага да асобнага. Спачатку мы будзем чапаць простыя інтэрфейсы, якія лёгка наладжваюцца і не патрабуюць асобных ліцэнзій. А далей усё гэта будзе прыкра ўскладняць. Прыкладам, возьмем і ўнутраную файлавую сістэму Data Domain і пачнём структураваць. З нейкага вялікага кавалка дадзеных зробім структураваную сістэму, каб ёй было зручна кіраваць.
Успомнім, што Data Domain у агульным выпадку – катастрофаўстойлівы выраб. Калі пісалі ТЗ распрацоўнікам, то далі заданне, каб Data Domain мог перажыць поўнае знішчэнне. Гэта што значыць? — у час скінуць рэпліку крытычных рэзервовых копій дадзеных на іншы Data Domain. Праўда, гэта рэч, якая ліцэнзуецца.
Пытанні бесперапыннасці забеспячэння бізнесу – вельмі актуальныя, асабліва пасля 9/11. І людзі задумаліся: а што будзе калі ў мяне будзе пажар ці яшчэ што?
Помніце паказнік RTO – што б ні здарылася, страціцца роўна гэтулькі – не больш, і што б ні здарылася, ўсё вярнуць назад можна за гэтулькі часу.
Тут было пытанне пра што, адна з прычын скарыстаць дыскавае сховішча для рэзервовых копій – гэта паляпшэнне паказніка RTO, час аднаўлення. Прыкладам, мы рабілі ўсе бэкапы на стужкавыя бібліятэкі, зараз патрабаванні да бяспекі памяняліся, зараз дадзеныя трэба аднаўляць яшчэ хутчэй, бібліятэкі не працуюць, што рабіць? Давайце падменім бібліятэку Data Domain, які будзе на фронт-эндзе выглядаць як бібліятэка, але з больш лепшым паказнікам RTO. Як з аднаго ці двух Data Domainо’в зрабіць адну ці тры віртуальных рабатызаваных стужкавых бібліятэкі? Як іх прэзентаваць наяўным сродкам рэзервовага капіявання, каб яны мінімальна напружваліся?
Самае важна тут зразумець: як трэба даналадзіць сродкі рэзервовага капіявання, каб яны слушна на такую віртуальную стужкавую бібліятэку штосьці пісалі. Таму што пісаць па даўніне, як яны абвыклі, фізічна, тут ужо ня варта, у звязку з той самай дэдуплікацыяй.

Калі вы не прывязаны да бібліятэк, калі ў вас няма задання падмяніць фізічную бібліятэку віртуальнай, то купляйце Data Domain з ліцэнзійнай функцыяй DDboost. Бо гэта для Data Domain родны інтэрфейс, які раскрывае ўсе яго магчымасці. Гэта самы лепшы варыянт выкарыстання Data Domain. Гэта значыць, што сродак рэзервовага капіявання ведае, што такое DDboost, у горшым выпадку, у лепшым разе гэта ведаюць баявыя бізнес-дадаткі, якія бэкапяцца, гэта круцей усяго.
Па-мойму, самая прадаваная канфігурацыя: гэта Networker з Data Domain праз DDboost, яны глядзяцца вельмі арганічна. Але мы разумеем, што DDboost – адкрыты інтэрфейс. СМС кажа: хай у вас будзе ваш сродак рэзервовага капіявання, але няхай яны ведаюць, што такое DDboost, і для захоўвання рэзервовых архіўных копій скарыстаюць наш аптымізаваны інтэрфейс. Як яго наладзіць – паглядзім.

Релоцировались? Теперь вы можете комментировать без верификации аккаунта.