
 В 2012 году социальная сеть Facebook преодолела серьезный рубеж, охватив 1 миллиард пользователей, при этом количество просмотров страниц достигло не менее круглого числа — 1 триллион в месяц. На данный момент хранилище компании составляет около 40 петабайт, ежедневно пользователями генерируется около 90 терабайт новой информации. Сказать, глядя на эти цифры, что Facebook — просто высоконагруженный проект, — значит, ничего не сказать.
В 2012 году социальная сеть Facebook преодолела серьезный рубеж, охватив 1 миллиард пользователей, при этом количество просмотров страниц достигло не менее круглого числа — 1 триллион в месяц. На данный момент хранилище компании составляет около 40 петабайт, ежедневно пользователями генерируется около 90 терабайт новой информации. Сказать, глядя на эти цифры, что Facebook — просто высоконагруженный проект, — значит, ничего не сказать.
Архитектура Facebook представляет собой уникальное решение, которое совмещает целую плеяду известных технологий. Предлагаю рассмотреть общее программное устройство крупнейшей социальной сети мира, а также использовать это как повод для практического знакомства с ее ключевыми технологиями. Надеюсь, практические примеры инсталляций, приводимые синхронно с изложением сухой теории и статистики, помогут сократить вечный диалектический разрыв между теорией и практикой и в очередной раз подтвердить поговорку «не боги горшки обжигают».
Удивительная масштабируемость применяемых в Facebook решений заключается прежде всего в том, что они одинаково успешно могут быть использованы как в крупных социальных сетях, так и в обыденных проектах средней величины — везде, где требуется повышенная гибкость и скорость реакции системы.
Кто есть кто: действующие лица
Прежде чем начать, хотелось бы поверхностно перечислить (представить) главные действующие лица, имена которых будут упоминаться по всей статье далее.
Hadoop — это открытая платформа для распределенных вычислений, хранения и обработки «больших данных». Это кросс-платформенный проект фонда Apache Software Foundation, написанный на языке Java, активное участие в разработке которого принимала, в том числе, и Facebook. В последнее время Hadoop стал широко использоваться в высоконагруженных интернет-проектах, для которых требуется масштабируемая и эффективная платформа для массово-параллельной обработки гигантских объемов данных.
Hadoop Project состоит из четырех самостоятельных компонент. Во-первых, это распределенная файловая система HDFS, которая отвечает за хранение «больших данных» на кластере Hadoop. Во-вторых — программная модель (фреймворк), построенная на принципах MapReduce, предназначенная для вычислений и обработки данных на кластере. В качестве третьей составляющей выделяют набор инфраструктурных программных библиотек и утилит для обслуживания Hadoop и смежных проектов. HBase — это заключительная, четвертая часть комплекса, которая представляет из себя нереляционную распределенную базу данных. Это решение — отказоустойчивый способ хранения больших объемов разреженных данных (созданное, кстати, по полной аналогии с BigTable от Google).
Как первая, так и вторая составляющая реализованы на базе ставшей уже стандартной архитектуры ведущий/ведомый (master/slave). В частности, в случае с HDFS ведущий (управляющий метаданными всей файловой системы) сервер называется NameNode, а множество ведомых серверов, физически хранящих данные, — DataNode. Вторая составляющая (MapReduce) аналогично двулика: она состоит из ведущего планировщика задач JobTracker, который распределяет их по множеству подчиненных ему узлов кластера, каждый из которых называется TaskTracker. Все упомянутые функциональные единицы кластера Hadoop реализованы как независимые демоны.
Замыкает Hadoop-архитектуру Facebook программа Hive. Это надстройка для облегчения программирования типичных аналитических задач на кластере (например, она позволяет использовать непрограммируемые запросы, такие как SQL). Для связывания множества разнородных интерфейсов и унификации разнообразных сервисов и языков программирования используется Thrift — универсальный язык описания интерфейсов. Это высокопроизводительный фреймворк для работы с RPC.
Тесно связана с этим инструментом еще одна часть архитектуры — Scribe, сервер для масштабированного и распределенного ведения логов; также как и Thrift, он был создан компанией Facebook и предназначен для агрегации огромного объема разнородных сообщений, достигающих в случае Facebook нескольких десятков миллиардов в день. Он может как распределять сообщения между разными хранилищами (случайно или в зависимости от хеша), так и дублировать сообщения сразу в несколько хранилищ.
Обработка входящих данных
Ниже изображены все этапы обработки входящих запросов социальной сети, вплоть до конечного попадания данных в соответствующие хранилища. Как видно по схеме ниже, критическую роль в этой архитектуре играет технология Hadoop. На текущий момент кластер Facebook Hadoop (Hadoop storage cluster) является самым большим в мире хранилищем данных, построенным на базе этой распределенной технологии.
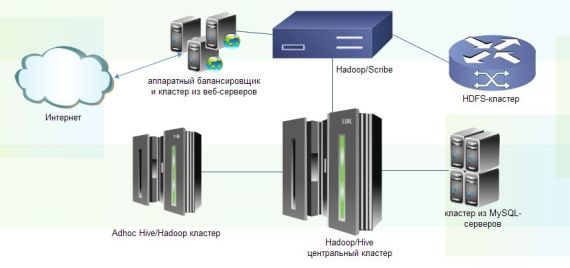 Инфраструктура Facebook для обработки входящих данных на базе Hadoop
Инфраструктура Facebook для обработки входящих данных на базе Hadoop
Вот лишь некоторые актуальные для Facebook цифры, чтобы было понятно, о какой махине далее пойдет речь:
- 29 петабайт данных сосредоточено в единственном HDFS-кластере;
- всего в этом кластере задействовано около 2600 серверов;
- в среднем на один сервер приходится около 15—20 терабайт обслуживаемых данных;
- большинство серверов используют новейшие 16-ядерные процессоры;
- у каждого сервера установлено 32 GB RAM;
- в среднем на одном сервере одновременно запущено 15—20 задач map-reduce.
Львиная часть этих данных поступает в кластер через Scribe, который у Facebook реализован не как полностью самостоятельный сервер, а будучи интегрированным в HDFS. Технически это сделано посредством библиотеки libhdfs, которая, по сути, является C-интерфейсом для собственного HDFS-клиента. Такая жесткая монолитная интеграция приводит к переключению работы файловой системы HDFS в режим, близкий к реальному времени.
На самом деле подобный симбиоз не настолько тривиален, как может показаться из этого краткого описания: изначально libhdfs, а также интерфейс FileSystem API содержали огромное количество откровенных ошибок, особенно в многопоточном режиме работы, которые всплыли еще на этапе внедрения в Facebook при тестировании под нагрузкой. Для Scribe многопоточный режим и вовсе используется по умолчанию, из-за чего инженерам Facebook пришлось самостоятельно переработать библиотеку libhdfs, попутно добавив новые вызовы в интерфейсы HDFS (например, важный API-вызов FileSystem.newInstance(), который привнес новый режим подключений к этой файловой системе).
В итоге все данные, оказавшиеся в Hadoop, становятся доступными для обработки через Hive. О важной роли последнего говорит хотя бы тот факт, что примерно 90% всех аналитических задач к кластеру у Facebook генерируется именно фронт-эндом системы Hive.

Хочется упомянуть и стиль сервисного обслуживания подобных монстроидальных информационных систем. В Facebook относительно технического персонала исповедуется принцип «сильной специализации»: над всем программным комплексом работает множество небольших и узкоспециализированных команд, находящихся в двухуровневом подчинении (непосредственный координатор нескольких смежных групп, а также общий для всех комитет развития). Упомянутый кластер на базе Hadoop/Hive, на хребте которого зиждется работа большинства служб Facebook, в настоящий момент обслуживает всего три человека.
Собираем систему на базе Hadoop
Как и было обещано в начале статьи, будем стараться в качестве познавательного упражнения самостоятельно развертывать описываемые нами системы, и начнем наши практические опыты с компиляции Scribe. Этот инструмент позволяет агрегировать в одном месте-приемнике огромное количество сообщений из самых разных источников: из текстовых файлов, сетевого потока, веб-протоколов, специализированных форматов.
Благодаря стараниям Facebook, отныне доступен режим прямой интеграции с HDFS. Далее мы рассмотрим именно такой вариант, и, в качестве предварительной подсказки, для успешной сборки всех составляющих воедино очень важно правильно подобрать совместимые версии основных пакетов и их зависимостей: boost, libevent, Thrift, fb303 и Hadoop. Наиболее чувствительными компонентами здесь являются boost, который должен иметь версию v2, и Thrift, где подходят любые версии ниже v0.5.0. Конечно, можно выбрать и более свежие версии упомянутого ПО, но при этом нужно быть готовым к сложностям в сборке, решение которых потребует создание собственных патчей (более подробно о специфике этого пути читайте здесь).
Я опускаю тривиальную установку перечисленных выше зависимостей, переходим сразу к сердцу системы — Hadoop/HDFS. Для начала скачиваем и распаковываем последнюю версию Apache Hadoop:
$ wget http://www.us.apache.org/dist/hadoop/common/hadoop-1.1.0/hadoop-1.1.0.tar.gz $ tar xfz hadoop-1.1.0.tar.gz $ cd hadoop-1.1.0/
Перед запуском соблюдаем две важные формальности — указываемым в переменных окружения путь к Java и каталогу для установки Hadoop:
export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/Home export HADOOP_INSTALL=/home/savgor/hadoop-1.1.0 export PATH=$PATH:$HADOOP_INSTALL/bin
Запускаем и проверяем правильность работы Hadoop. Получив ожидаемый отклик, переходим к самому интересному — нестандартному «прикручиванию» Scribe. Для начала указываем необходимые пути в переменных окружения LDFLAGS и CPPFLAGS, где должны быть заранее перечислены дополнительные библиотеки. В моем случае эта команда выглядит так:
export LDFLAGS="-L/usr/local/cdh/hadoop/c++/lib \ -L/usr/java/default/jre/lib/amd64/server" export CPPFLAGS="-I/usr/java/default/include \ -I/usr/local/cdh/hadoop/src/c++/libhdfs \ -I/usr/java/default/include/linux"
Стандартным образом скачиваем и устанавливаем Scribe, после чего собираем его с ключом --enable-hdfs, последовательно перечисляя локальные пути ко всем зависимостям:
cd scribe-2.2 ./bootstrap.sh --enable-hdfs \ --with-boost=/my_server/boost-1.41.0 \ --with-thriftpath=/my_server/thrift-0.4.0 \ --with-fb303path=/my_server/fb303 \ --prefix=/my_server/scribe-2.2 \ --with-hadooppath=/usr/local/cdh/hadoop make make install
Теперь можно запустить и сам сервер:
bin/scribed -c scribe.conf
Советую сразу же протестировать правильность интеграции Scribe в файловую систему HDFS, для чего можно использовать следующую команду (предварительно нужно установить Scribe-клиент для Python):
python client.py "Igor test string" 100
Альтернативный способ сделать это же — воспользоваться стандартной утилитой пакета Scribe (впрочем, также написанной на Python) scribe_cat так, как показано ниже:
echo “Igor test string” | ./scribe_cat default
Подключиться хранилищу HDFS можно и из других языков, например, Ruby. Более общая информация о тестировании связки Scribe/HDFS доступна здесь, а универсальное решение для связывания хранилища с любыми языками программирования в виде Thrift будет рассмотрено далее во втором примере.
Каким бы способом взаимодействия вы ни воспользовались в итоге, обращаю ваше внимание: Scribe сбрасывает из оперативной памяти данные в HDFS только при накоплении их в объеме, эквивалентном блоку этой файловой системы. Размер нашего тестового сообщения из примера заведомо намного ниже этого значения. Чтобы увидеть результирующий файл, принудительно сбросим данные из буферов сервера, работающего на стандартном порту, следующей командой:
./scribe_ctrl reload 1463
Миграция в сторону HBase
Интересно, что модель, схематично описанная выше, продержалась в Facebook примерно два года. Из-за постоянного роста нагрузки социальный гигант в данный момент осуществляет миграцию на связку Hbase/HDFS/ZooKepeer тем не менее по-прежнему оставаясь в рамках Hadoop Project. Все сообщения, генерируемые пользователями (приватные сообщения, лайки, чаты, входящие e-mail, SMS и т.д.), — все это агрегируется и накапливается в гигантском хранилище HBase. На рисунке ниже можно увидеть иерархическую структуру нового трехуровневого кластера HBase/HDFS, к которому в результате вынужденной эволюции пришел Facebook.
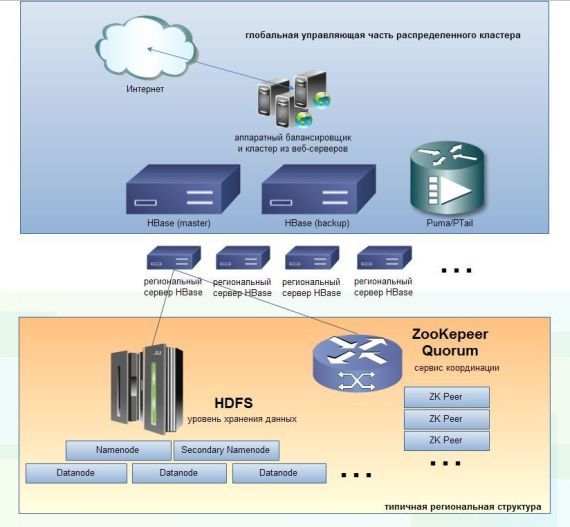 Трехуровневая инфраструктура Facebook для обработки данных на базе HBase
Трехуровневая инфраструктура Facebook для обработки данных на базе HBase
По состоянию на лето 2012 года кластер HBase/HDFS демонстрировал следующие показатели:
- обрабатывается около 8—10 миллиардов сообщений в день;
- более 80 миллиардов операций чтения/записи HDFS в день;
- в пике частота операций чтения/записи HDFS достигает 1,5 миллиона в секунду;
- из них примерно 60% чтение, 40% — запись;
- в HBase сейчас хранится около 6 петабайтов банных (сюда входят не только сами сообщения, но и их поисковый индекс, метаданные);
- все сообщения хранятся в заархивированном виде (LZO-компрессия);
- рост базы в среднем идет на 250 терабайт в месяц.
Система испытывает чрезвычайную интенсивность ввода/вывода, на этом фоне уже неудивительно смотрится факт, что в дата-центрах Facebook ежемесячно выходят из строя более 1000 винчестеров (есть даже собственный цех для их утилизации).

На фоне этой экстремальной нагрузки очень важно понять причины, по которым именно HBase выбран следующей целью миграции для всей инфраструктуры социального гиганта с Hadoop.
Вот лишь некоторые из них:
- эта БД интегрирована с распределенной файловой системой HDFS для хранения больших данных, в которой доступна проверка целостности данных, репликация, автоматическая перебалансировка;
- переход именно на эту систему для Facebook облегчен, так как компания до этого использовала Hadoop с той же файловой системой в основании — HDFS;
- HBase реально способен справиться с очень большой интенсивностью операций запись/чтение – грамотно реализованный и распараллеленный MapReduce позволяет расти пропорционально с увеличивающейся нагрузкой;
- для еще большего ускорения используется Puma — технология пакетной записи данных напрямую в HBase;
- много дополнительных встроенных возможностей, например, поддержка компрессии и операций в памяти. Также эта БД удовлетворяет не только ACID-требованиям самого высокого уровня для любых коммерческих РСУБД, но и уровню «разнообразие, скорость, объем и сложность» (variety, velocity, volume, complexity), до которого реляционные системы пока не дотягивают;
- очень большая гибкость БД. Например, таблицы HBase могут быть извлечены не только через основной интерфейс Java API, но и через API REST, Avro или фирменный для Facebook — Thrift;
- оглядываясь на последние как минимум 3 года, можно констатировать очень быстрый темп развития этого проекта наряду с общей стабилизацией его кода.
Ко всему перечисленному остается добавить, что компания OpenLogic провела исследование тенденций востребованности открытых проектов в 2012 году, и второй год подряд первое место по росту внедрений занимает именно HBase, сразу за ним следует второй наш герой — Hadoop. Можно констатировать, что фактически Hadoop уже стал именем нарицательным в нереляционном мире Big Data, аналогично SQL в мире обычных РСУБД.

Предлагаю для осмысления всех упомянутых моментов лично попробовать в деле HBase, но чтобы эта задача не показалось слишком банальной — зададимся целью создать к этой базе коннектор для PHP. И сделаем мы это «а-ля Facebook» — через язык Thrift, который позволяет связывать воедино самые различные серверы и языки. В качестве отправной точки регистрируем все зависимости (libboost-dev, libboost-test-dev, libboost-program-options-dev, libevent-dev), после чего скачиваем и устанавливаем самую последнюю версию Thrift:
$ wget http://dist.apache.org/repos/dist/release/thrift/0.9.0/thrift-0.9.0.tar.gz $ tar xfz thrift-0.9.0.tar.gz $ cd thrift-0.9.0/ $ ./configure $ make $ sudo make install
После инсталляции стоит обратить внимание на итоговый листинг, он будет иметь примерно следующий вид (дается в сокращенном виде):
thrift 0.9.0 Building C++ Library ......... : yes Building C (GLib) Library .... : no Building Java Library ........ : yes Building C# Library .......... : no Building Python Library ...... : yes Building PHP Library ......... : yes Building Erlang Library ...... : no Building TZlibTransport ...... : yes Building TNonblockingServer .. : yes Using ant .................... : /usr/bin/ant Using Python ................. : /usr/bin/python
Если интересующий вас язык отключен, придется выполнить пересборку с явно заданными ключами.
Скачиваем и распаковываем последний HBase:
$ wget http://www.eu.apache.org/dist/hbase/hbase-0.94.2/hbase-0.94.2.tar.gz $ tar xfz hbase-0.94.2.tar.gz
Проводим минимальную настройку его конфигурационного XML-файла (conf/hbase-site.xml), чтобы указать путь, где будет храниться наша тестовая база:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>HBase.rootdir</name> <value>file:///hbase-0.94.2</value> </property> </configuration>
Вот и все приготовления — теперь можно смело запускать HBase:
$ ./hbase-0.94.2/bin/start-hbase.sh
Последний шаг — нужно сгенерировать PHP-код для подключения нашего тестового PHP-клиента. И конечно, сделаем мы это через ранее установленный Thrift:
$ thrift --gen php hbase-0.94.2/src/main/apache/hadoop/hbase/thrift/hbase.thrift
На выходе мы получим папку gen-php, в которой найдем все необходимое для подключения клиента.
В дополнение к нему следует скопировать родные библиотеки Thrift — теперь вы можете использовать этот готовый код для связывания своего проекта с HBase. При использовании своего приложения на базе этого решения не нужно забывать о том, что предварительно у вас должен быть запущен как HBase, так и сервер Thrift (это можно сделать в любой момент, громко скомандовав: /bin/hbase thrift start).





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.