
Ответ на этот вопрос в своём блоге даёт графический программист Себастьян Сильван (Sebastian Sylvan), который работает в офисе Microsoft в Сиэтле.
Причин, по которым большинство высокоуровневых языков программирования медленно работают, обычно две:
- они плохо работают с кэшем;
- сборка мусора отнимает много ресурсов.
На самом деле, обе причины сводятся к одной — в таких языках происходит большое количество выделений памяти.
Следует уточнить, что я говорю в первую очередь о клиентских приложениях, где важна локальная скорость выполнения. Если приложение тратит 99,9% времени на ожидание ответа по сети, вряд ли важно, насколько медленным является язык, проблема оптимизации сетевого взаимодействия будет важнее.
Я возьму в качестве примера C# по двум причинам: во-первых, это высокоуровневый язык, который я часто использую последнее время, и во-вторых, если бы я взял Java, фанаты C# могли бы возразить, что использование value-типов в C# избавляет от большинства проблем (это не так).
Кроме того, я буду исходить из предположения, что пишется идиоматичный код, в одном стиле со стандартными библиотеками и с учетом принятых соглашений. Я не буду рассматривать уродливые костыли в качестве «решения» проблемы. Да, в некоторых случаях это позволяет обойти особенности языка, но не устраняет изначальную проблему.
Работа с кэшем
Для начала, давайте посмотрим, почему важно правильно использовать кэш. Вот график задержек памяти в процессорах Haswell, основанный на этих данных.
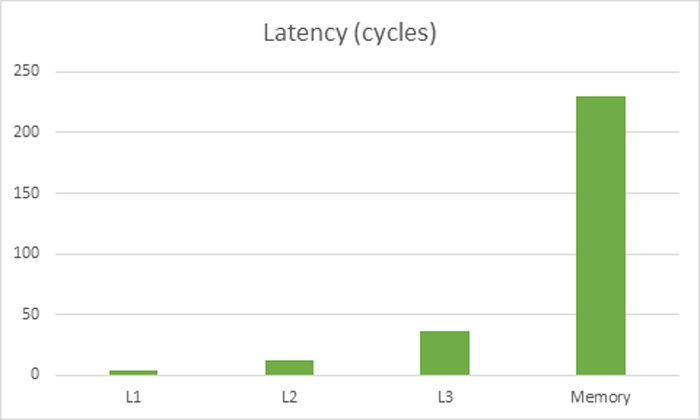
Задержка при чтении из кучи составляет примерно 230 тактов, в то время, как чтение из L1 кэша — 4 такта. Получается, что неправильная работа с кэшем может сделать код почти в 50 раз медленнее. Более того, благодаря многозадачности современных процессоров, чтение из кэша может происходить одновременно с работой с регистрами, поэтому задержку при чтении из L1 можно вообще не учитывать.
Проще говоря, кроме разработки алгоритма, промахи кэша — основная проблема производительности. Как только вы решите проблему эффективного доступа к данным, останутся только небольшие оптимизации, которые, в сравнении с промахами кэша, не так сильно влияют на производительность.
Хорошие новости для разработчиков языка: вам нет необходимости разрабатывать самый эффективный компилятор и вы можете сэкономить свое время с помощью некоторых абстракций. Все, что вам нужно — организовать эффективный доступ к данным, и программы на вашем языке смогут посоревноваться в скорости исполнения с C.
Почему использование C# приводит к частым промахам кэша
Проще говоря, C# разработан так, что не учитывает современных реалий работы с кэшем. Ещё раз, я не говорю об ограничениях, накладываемых языком и «давлении», которое они оказывают на программиста, заставляя писать не самый эффективный код. Теоретически, для многих из этих вещей есть обходные пути, хотя и не самые удобные. Я говорю о том коде, к написанию которого нас побуждает язык как таковой.
Основная проблема C# в том, что он очень скудно поддерживает value-типы. Да, в нём есть структуры, которые представляют из себя значения, хранящиеся там же, где и объявлены (например, на стеке или внутри других объектов). Но есть несколько довольно серьезных проблем, из-за которых эти структуры являются скорее костылями, чем решениями.
- Вы обязаны объявлять типы данных заранее, что означает, если вам когда-либонужно, чтобы объект этого типа существовал в куче, то все объекты этого типавсегда будут выделяться в куче. Конечно, вы можете написать классы-обёртки для нужных типов данных и использовать для каждого случая нужную обёртку, но это довольно болезненный путь. Было бы лучше, если классы и структуры всегда объявлялись одинаково, но использовать их было возможно по-разному и именно так, как нужно в данном конкретном случае. Т. е. когда вам нужно что-либо на стеке, вы объявляете это как значение, а когда в куче — как объект. Именно так работает С++, например. Там вас не заставляют делать всё объектами хотя бы потому, что есть некоторые вещи, которые должны быть в куче (по разным причинам).
- Возможности ссылок сильно ограничены. Вы можете передать что-либо по ссылке в функцию, но на этом всё. Нельзя просто так взять и получить ссылку на элемент в List<int>, например. Для этого нужно хранить в списке и ссылки и значения одновременно. Нельзя получить указатель на что-либо выделенное на стеке или расположенное внутри объекта. Можно только скопировать всё, либо передать в функцию по ссылке. Причины такого поведения, конечно, вполне понятны. Если безопасность типов в приоритете, то довольно затруднительно (если не вообще невозможно) поддерживать гибкую систему ссылок и одновременно гарантировать такую безопасность. Но даже резонность таких ограничений не изменяет того факта, что эти ограничения всё таки есть.
-
Буферы с фиксированным размером не поддерживают пользовательские типы и требуют директивы unsafe.
- Ограниченная функциональность подмассивов. Существует класс ArraySegment, однако он мало кем используется. Если вам надо передать набор элементов из массива, вам придется создавать IEnumerable, а значит выделять память. Даже если API поддерживает ArraySegment, этого все равно недостаточно: вы не сможете использовать его ни для List<T>, ни для массива на стеке, только для обычного массива.
В итоге, язык всегда, кроме самых простых случаев, подталкивает в активному использованию кучи. Если все ваши данные в куче, вероятность промаха становится выше (поскольку вы не можете решать, как именно расположить данные). В то время как при написании программы на C++ программисту приходится думать, как эффективно обеспечить доступ в данным, C# поощряет их расположение в отдельных участках памяти. Программист теряет контроль над расположением данных, что влечет за собой ненужные промахи и, как следствие, падение производительности. Причем тот факт, что вы можете скомпилировать программу на C# в нативный код, не имеет значения. Рост производительности не скомпенсирует плохую локальность кэша.
Кроме того, неэффективно используется место. Каждая ссылка — это 8 байт на 64-битной машине, каждой аллокации сопутствуют метаданные. В куче, которая заполнена крошечными объектами со ссылками на них, остается намного меньше свободного места, чем если бы в них были расположены крупные объекты с содержимым внутри, расположенным на фиксированном смещении. Даже если вас не беспокоит впустую растраченное место, если куча переполнена заголовками и ссылками, весь этот мусор пойдет в кэш, что, опять же, приведет к большому количеству промахов и падению производительности.
Конечно, есть обходные пути. К примеру, вы можете использовать структуры и размещать их в пуле из List<T>. Это позволит, например, обойти список и обновить все объекты на месте. К сожалению, теперь, чтобы получить ссылку на объект, вам надо получить ссылку на пул и индекс элемента, и в дальнейшем пользоваться индексацией по массиву. В отличие от C++, в С# такой трюк выглядит ужасно, язык просто не предназначен для этого. Более того, теперь доступ к одному элементу из пула дороже, чем при использовании просто ссылки — теперь может быть два промаха, поскольку надо будет разыменовывать сам пул. Вы можете, конечно, продублировать функционалList<T> в структуре, чтобы избежать этого. Я написал много подобного кода за свою практику: он уродлив, работает на низком уровне и не застрахован от ошибок.
Наконец, я хочу отметить, что это проблема возникает не только в узких местах. В идиоматично написанном коде ссылочные типы будут повсюду. Это значит, что по всему коду постоянно будут происходить задержки в несколько сотен тактов, перекрывая все оптимизации. Если даже оптимизировать ресурсоемкие участки, ваш код будет равномерно медленным. Так что, если вы не хотите писать программы, используя пулы памяти и индексы, работая, возможно, на более низком уровне, чем C++ (зачем тогда использовать C#), вы вряд ли что-то можете сделать, чтобы избежать этой проблемы.
Сборка мусора
Я полагаю, что читатель понимает, почему сборка мусора сама по себе составляет серьезную проблему для производительности. Случайные зависания на время сборки совершенно недопустимы для программ с анимацией. Я не буду останавливаться на этом и перейду к тому, как дизайн самого языка может ухудшить ситуацию.
Из-за ограничений языка в работе с value-типами, разработчику зачастую приходится вместо одной большой структуры данных (которую даже можно положить на стек) использовать много маленьких объектов, которые размещаются в куче. При этом надо помнить, что чем больше объектов размещено в куче, тем больше работы для сборщика мусора.
Есть определенные тесты, в которых C# и Java превосходят C++ в производительности, поскольку выделение памяти в языке со сборкой мусора обходится заметно дешевле. Однако, на практике такое происходит редко. Написать программу на C# c таким же количеством выделений памяти, как в самой наивной реализации на C++, требует намного больше усилий. Мы сравниваем сильно оптимизированную программу на языке с автоматическим управлением памятью, с нативной программой, написанной «в лоб». Если мы потратим такое же количество времени на оптимизацию C++ кода, мы вновь оставим C# далеко позади.
Я знаю, что возможно написать сборщик мусора, обеспечивающий высокую производительность (например, инкрементальный, с фиксированным временем на сбор), но этого недостаточно. Самая большая проблема высокоуровневых языков — то, что они поощряют создание большого количества объектов. Если бы в идиоматичном C# было бы такое же количество выделений памяти, как и в программе на C, сборка мусора представляла бы гораздо меньшую проблему. И если бы вы использовали инкрементальный сборщик мусора, например, для систем мягкого реального времени, вам, скорее всего, понадобился бы барьер записи для него. Но насколько бы он дешево не обходился, в языке, который поощряет активное использование указателей, это означает дополнительную задержку при изменении полей.
Посмотрите на стандартную библиотеку .Net — выделения памяти на каждом шагу. По моим подсчетам .Net Core Framework содержит в 19 раз больше публичных классов, чем структур. Это значит, что при ее использовании вы столкнетесь с большим количеством аллокаций. Даже сами создатели языка не смогли сопротивляться соблазну! Я не знаю, как собрать статистику, но используя библиотеку базовых классов, вы точно заметите, что по всему коду происходит огромное количество выделений памяти. Весь код написан с учетом предположения, что это дешевая операция. Нельзя даже вывести intна экран без создания объекта! Представьте себе: даже используя StringBuilder вы не можете просто передать в него int без аллокации с помощью стандартной библиотеки. Это же глупо.
Это встречается не только в стандартной библиотеке. Даже в API Unity (игровой движок, для которого важна производительность) повсюду методы, которые возвращают ссылки на объекты или массивы ссылочных типов, или заставляют пользователя выделять память для вызова этих методов. К примеру, возвращая массив из GetComponents, разработчики выделяют память для массива только для того, чтобы посмотреть, какие компоненты есть в GameObject. Конечно, есть альтернативные API, однако если следовать стилю языка, лишних выделений памяти не избежать. Ребята из Unity пишут на «хорошем» C#, у которого ужасная производительность.
Заключение
Если вы разрабатываете новый язык, пожалуйcта, учитывайте производительность. Никакой «достаточно умный компилятор» не сможет обеспечить ее пост-фактум, если не заложить эту возможность изначально. Да, сложно обеспечить типобезопасность без сборщика мусора. Да, сложно собирать мусор, если данные представлены неоднородно. Да, сложно разрешать вопросы области видимости, если есть возможность получить указатель на любое место в памяти. Да, здесь много проблем. Но разработка нового языка — это решение именно этих вопросов. Зачем делать новый язык, если он мало отличается от тех, что были созданы в 60-ых?
Даже если вы не сможете решить все проблемы, можно постараться справиться с большинством из них. Можно использовать region types как в Rust для обеспечения безопасности. Можно отказаться от идеи «типобезопасности любой ценой», увеличив количество рантайм-проверок (если они не вызывают дополнительных промахов кэша). Ковариантные массивы в C# — как раз тот случай. По сути, это обход системы типов, который ведет к выбросу исключения во время выполнения.
Подводя итог, могу сказать, что если вы хотите разработать альтернативу C++ для высокопрозводительного кода, вам необходимо задуматься о расположении данных и их локальности.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.