Принципиальная разница между адресным и семантическим поисками состоит в том, что при адресном поиске документ рассматривается как объект с точки зрения формы, а при семантическом поиске – с точки зрения содержания. (с) ВикипедияЯ тебя нашел на свою беду. (с) Т. Темиров
Нововведение Google под названием The Knowledge Graph уже назвали одним из лучших за последние несколько месяцев. На разработку сего детища у компании ушло примерно два года. Повторяться не будем, предлагаем (наверняка не впервые) посмотреть видео и насладиться позитивом и вселенским счастьем.
Что нового?
На некоторые из запросов пользователя Google умеет давать «умные» ответы уже сейчас. На странице с результатами выдачи могут появляться котировки акций, прогноз погоды, информация об авиарейсах или заголовки новостей, в которых упоминаются искомые объект или лицо. Помимо этого, Google умеет осуществлять перевод величин, заменять калькулятор, конвертировать валюту и строить графики функций.
Перед началом основной работы по данному проекту в 2010 году Google приобрел компанию Metaweb Technologies, которая создала базу данных Freebase. На тот момент база насчитывала около 12 млн. сущностей (данные о компаниях, различных объектах, фильмах, телешоу, актерах, книгах и т.д.). Все это время сотрудники компании (около 50 человек) вели работы по расширению и улучшению этой базы данных. На данный момент база содержит около 500 миллионов объектов и около трех с половиной миллиардов связей между ними. Предполагается, что Google будет также использовать MQL (Metaweb Query Language) – API для создания программируемых запросов к Freebase.
Ранее в анонсах сообщалось, что блок с The Knowledge Graph будет размещаться под строкой поиска и над выдачей. Это вызывало определенную критику со стороны пользователей, поскольку таким образом результаты семантического поиска визуально воспринимались бы как более важные, а первые позиции поисковой выдачи потеряли бы лидирующие позиции на странице. Однако на данный момент мы видим, что этот блок будет размещаться справа от поисковой выдачи. Пока не сообщается, можно ли будет включать и выключать показ блока The Knowledge Graph.
Google подчеркивает, что персонализация поиска в сочетании с семантическим поиском дадут новый вариант релевантности выдачи. Если человек хочет узнать длину реки Миссисипи, ему больше не надо самому рыскать по ссылкам и вчитываться в статью на Википедии, чтобы узнать конкретный факт.
Правда, совершенно не факт, что мы, уже привыкшие разговаривать с поисковиком на определенном языке, поменяем свою стратегию. Мы думаем фразами «купить гарнитуру "овраг" в минске», а более или менее знакомые с поисковиками знают, что «гарнитура "овраг" отзывы» или «гарнитура "овраг" форум» лучше, чем «какая гарнитура самая лучшая» или «где купить лучшую гарнитуру», поскольку два последних запроса с большой вероятностью выдадут рекламные тексты. Семантический же поиск в перспективе сможет сравнивать характеристики техники и на этой основе выдавать пользователю ответ на вопрос.
На данный момент презентационный ролик делает акцент именно на поиске по личностям и фактам. Это область, в которой проще применять семантический поиск, чем в остальных, поскольку она наименее абстрактна. Как подчеркивают представители Google, новый проект – это на данный момент не столько анализ текста, сколько показ релевантной информации. Следующим шагом в улучшении поиска будет корректное удовлетворение сложных запросов на нормальном человеческом языке, например: «Где я могу купить горячие пирожки с грибами с доставкой в Минске в полночь».
Однако неизвестно, какую политику применит Google в случаях, когда ответы будут различаться в зависимости от местоположения пользователя, языка, на котором он говорит, а также времени года, например. Также неясно, будет ли поисковик уточнять (и если да, то как) выдачу для вопросов, на которые не может быть однозначного ответа.
Обычной поисковой строки становится мало для работы со сложными, логически структурированными запросами. Как и Wolfram Alpha, Google предложит пользователю уточнить область поиска в специальном блоке. К примеру, если набрать запрос «Da Vinci», поисковик попросит вас уточнить, имели ли вы в виду художника и изобретателя, одноименную компанию или музыкальную группу (и даже не спросит, действительно ли вы работаете на ее пиар-поддержку), а после обновит страницу выдачи согласно выбранному варианту.
Технологии
Что мы имеем на рынке семантического поиска сейчас? Безусловно, Wolfram Alpha, запущенный в 2009 году. Данные, предоставляемые этой системой, используются как в Siri, так и в поисковике Bing (последний, к примеру, имеет полезную функцию – рассчитывает сложные математические функции). Кстати говоря, сам Wolfram Alpha не является прямым конкурентом Google, поскольку не является поисковиком и ссылки на релевантные документы не возвращает, а лишь вычисляет ответ по собственной базе знаний. Кроме того, этот сервис понимает только английский язык. Какие языки на первом этапе будет понимать The Knowledge Graph, пока не сообщается.
Далее, у ABBYY есть алгоритм анализа ABBYY Compreno, построенный на универсальном семантическом дереве с применением полного синтаксического анализа. Суть этого алгоритма в том, что люди, несмотря на различия языков, используют похожие семантические объекты. Например, все люди спят, едят, большинство людей ходит на работу, тратит деньги, эти понятия есть почти во всех языках.
Однако для более точного поиска системе все равно нужно «знать» языки. И для каждого из них в итоге алгоритм семантической разработки будет свой.
А вот Ask.com выделяет те куски текста, которые содержат прямой ответ на заданный вопрос. Для этого используется три основные семантические технологии:
вывод прямого ответа из базы данных (direct answer from database,
DADS);
вывод прямого ответа из результатов поиска (direct answer from search,
DAFS);
поисковый робот AnswerFarm, который индексирует пары «вопрос–ответ» (Q&A) из веб-сети. Найденные в интернете пары Q&A сохраняются в базе данных для выдачи ответа на вопросы пользователей.
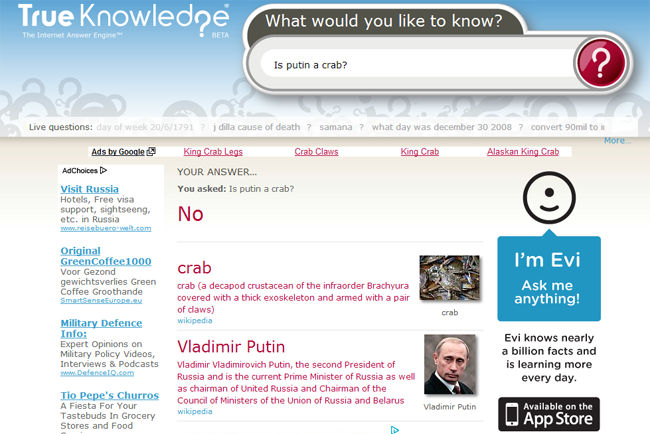
Следующая в нашем списке TrueKnowledge.com, как и Ask.com, является системой ответов на вопросы, но использует другой подход к выдаче прямых ответов. Ответ производится на основе сохраненных фактов (триплеты в формате субъект–предикат–объект) и правила логического вывода. Данная база дискретных фактов заполняется двумя способами: путем импорта из внешних баз данных и путем ручного занесения данных пользователями системы.
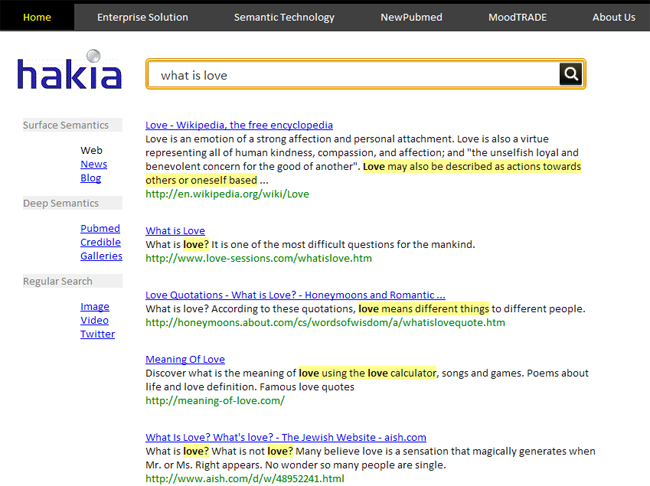
И, наконец, система Hakia базируется на трех технологиях: OntoSem – хранилище семантической информации, QDEX – технология индексации документов и SemanticRank – компонент ранжирования текстов по смыслу.
Также стоит снова упомянуть бесплатную всемирную базу знаний FreeBase, которую можно подключить к своему ресурсу через API.
Похожие функции есть и у других поисковиков (Yahoo, Yandex, Mail.Ru и др). Также на рынке существует еще много сервисов, предоставляющих сервис семантического поиска.
Что такое семантический поиск?
В новом поиске релевантность документов запросу определяется не только синтаксически, но и семантически.
Пример: У нас есть предложение «А, несмотря на неполадки с болидом, обогнал Б на финише Кубка мира и пришел первым», описывающее определенное событие. Положим это предложение на страничку сайта и скормим ее поисковику. После того, как она будет проиндексирована, спросим поисковик: «победитель заезда на Ибице», «чемпион мира гонщик имя». В выдачу наше предложение не попадает, хоть и содержит нужную информацию. Семантический поиск не просто сравнивает объекты, он «понимает» их смысл, и с помощью него мы бы смогли получить ответ на свой запрос, даже если он не содержал ключевых слов.
Данный вид поиска использует сложную многомерную математическую модель и оперирует такими понятиями, как семантическая сеть, семантическая паутина и онтология. Онтология – это формализация знаний с помощью определенной схемы, иными словами, это форма представления знаний. Тут уместно вспомнить господина Вольфрама, который очень любит все измерять, класисфицировать, считать и выводить статистику. Онтологии в информатике выражаются с помощью языков логической базы, таких, как ALF, Alma-0, CLACL, Curry, Fril, Janus, Leda, Oz.
Уникальность всей этой красоты в том, что здесь работает математика, когнитивная психология, лингвистика, семиотика, программирование, библиотечное дело и еще несколько наук. Трудно себе представить себе более распределенный между дисциплинами проект.
Первые вопросно-ответные системы, прабабушки семантического поиска, появились еще в 1960-х годах и использовались как языковые оболочки для узкоспециализированных экспертных систем.
Та же Википедия, ссылаясь на авторитетные сайты, относит семантическую паутину и вопросно-ответную систему к списку «новых перспективных технологий».
Такие проекты, как The Knowledge Graph и Wolfram Alpha, предусматривают необходимость использования огромного количества серверов и дата-центров, а также разработку крайне сложного ПО. В частности, этот метод является областью применения нейронных сетей. Именно самообучающиеся нейронные сети на данный момент являются лучшим средством для семантической обработки и анализа текста в силу таких особенностей человеческого языка, как многозначность, взаимозаменяемость, свободная структура. Кстати, Siri — это разработка Международного центра искусственного интеллекта SRI, который на данный момент занимается крупнейшими проектами в области нейронных сетей и искусственного интеллекта.
Критика
Практически все глобальные источники информации сталкиваются с проблемой проверки предоставляемых фактов. ЖЖ-юзер kelijah приводит интересный пример в этой связи:
«Допустим, что должен делать "семантический поиск" при запросе "лучший амулет для укрепления семьи"? Сказать пользователю, что амулеты и прочая магия – это ненаучный и неподтверждаемый бред, чему есть множество хороших доказательств? Или дать ссылки на сайты с описанием таких амулетов? Исходя просто из формальной логики вывода ответа, и тот и другой вариант одинаково обоснованы.»
По сути, Google столкнется с теми же проблемами, которые есть в Википедии. Полученные с помощью алгоритма данные все равно должны будут регулироваться людьми. Различие с Википедией здесь в том, что в ней это в основном делают сами пользователи, в Google же это будут специально нанятые сотрудники. Это нужно хотя бы потому, что для анализа будут использоваться совершенно различные источники, на которых с большой вероятностью может быть размещена неверная информация. Без человеческого контроля даже злоумышленники наверняка смогут найти способ мошенничества и подтасовки результатов семантического поиска через внешние источники. Тем более что самую основную информацию (например, место и год рождения персонажа) Google будет показывать из собственной базы, а вот остальное уже будет подтягиваться с сайтов вроде Википедии.
Выводы
Семантический поиск, безусловно, улучшит релевантность выдачи. Специалисты считают, что наиболее выгодный вариант – это использовать средства синтаксического анализа вкупе с семантическим, это позволит использовать преимущества как одного, так и другого метода одновременно.
Использование The Knowledge Graph вызывает серьезные опасения у владельцев сайтов. Если пользователь будет получать информацию прямо на странице поисковика, у него не будет нужды переходить по ссылке на сайт. Так как до сих пор основным средством финансирования большинства ресурсов является реклама, то многие веб-сайты, предоставляющие информацию пользователю, могут частично потерять свое финансирование, что теоретически может привести к выборочному ухудшению качества контента.
Семантический поиск в Google – вовсе не первый и уж точно не единственный проект в этой сфере. Но уникальность The Knowledge Graph состоит именно в том, что он несет семантический поиск в массы. Несмотря на определенную популярность Wolfram Alpha, скептики высказывали мнение, что этот поисковик очень специфичен и может использоваться лишь в узких прикладных целях. Например, кому понадобится анализатор текстов книг в том виде, в каком он есть в Wolfram Alpha? Google же предлагает использовать семантику в полном объеме каждый день.
Новым сервисом Google также обостряет конкуренцию с социальными сетями. Чем больше человек остается на страницах Google, тем больше последний может заработать на каждом конкретном пользователе. Пока же мы, простые смертные, ожидаем от The Knowledge Graph жесточайших интернет-мемов, да поэпичнее.
«Наем в польском Google сломан». Прошел собесы — и застрял (похоже, навсегда)
Уже почти год как Михаил пытается попасть в варшавский офис Google. Он прошел все этапы и встал «в очередь» из успешных кандидатов. Осталось дождаться подходящей вакансии и понравиться менеджеру на 30-минутном звонке. И тут оказалось, что не все так просто.

 Принципиальная разница между адресным и семантическим поисками состоит в том, что при адресном поиске документ рассматривается как объект с точки зрения формы, а при семантическом поиске – с точки зрения содержания. (с) Википедия
Я тебя нашел на свою беду. (с) Т. Темиров
Нововведение Google под названием The Knowledge Graph уже назвали одним из лучших за последние несколько месяцев. На разработку сего детища у компании ушло примерно два года. Повторяться не будем, предлагаем (наверняка не впервые) посмотреть видео и насладиться позитивом и вселенским счастьем.
Принципиальная разница между адресным и семантическим поисками состоит в том, что при адресном поиске документ рассматривается как объект с точки зрения формы, а при семантическом поиске – с точки зрения содержания. (с) Википедия
Я тебя нашел на свою беду. (с) Т. Темиров
Нововведение Google под названием The Knowledge Graph уже назвали одним из лучших за последние несколько месяцев. На разработку сего детища у компании ушло примерно два года. Повторяться не будем, предлагаем (наверняка не впервые) посмотреть видео и насладиться позитивом и вселенским счастьем.
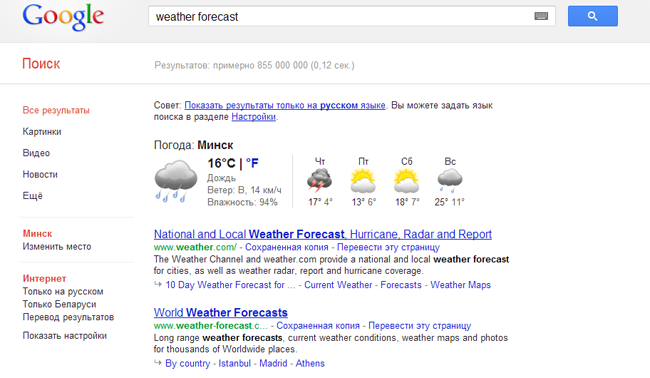 Перед началом основной работы по данному проекту в 2010 году Google приобрел компанию Metaweb Technologies, которая создала базу данных Freebase. На тот момент база насчитывала около 12 млн. сущностей (данные о компаниях, различных объектах, фильмах, телешоу, актерах, книгах и т.д.). Все это время сотрудники компании (около 50 человек) вели работы по расширению и улучшению этой базы данных. На данный момент база содержит около 500 миллионов объектов и около трех с половиной миллиардов связей между ними. Предполагается, что Google будет также использовать MQL (Metaweb Query Language) – API для создания программируемых запросов к Freebase.
Ранее в анонсах сообщалось, что блок с The Knowledge Graph будет размещаться под строкой поиска и над выдачей. Это вызывало определенную критику со стороны пользователей, поскольку таким образом результаты семантического поиска визуально воспринимались бы как более важные, а первые позиции поисковой выдачи потеряли бы лидирующие позиции на странице. Однако на данный момент мы видим, что этот блок будет размещаться справа от поисковой выдачи. Пока не сообщается, можно ли будет включать и выключать показ блока The Knowledge Graph.
Перед началом основной работы по данному проекту в 2010 году Google приобрел компанию Metaweb Technologies, которая создала базу данных Freebase. На тот момент база насчитывала около 12 млн. сущностей (данные о компаниях, различных объектах, фильмах, телешоу, актерах, книгах и т.д.). Все это время сотрудники компании (около 50 человек) вели работы по расширению и улучшению этой базы данных. На данный момент база содержит около 500 миллионов объектов и около трех с половиной миллиардов связей между ними. Предполагается, что Google будет также использовать MQL (Metaweb Query Language) – API для создания программируемых запросов к Freebase.
Ранее в анонсах сообщалось, что блок с The Knowledge Graph будет размещаться под строкой поиска и над выдачей. Это вызывало определенную критику со стороны пользователей, поскольку таким образом результаты семантического поиска визуально воспринимались бы как более важные, а первые позиции поисковой выдачи потеряли бы лидирующие позиции на странице. Однако на данный момент мы видим, что этот блок будет размещаться справа от поисковой выдачи. Пока не сообщается, можно ли будет включать и выключать показ блока The Knowledge Graph.
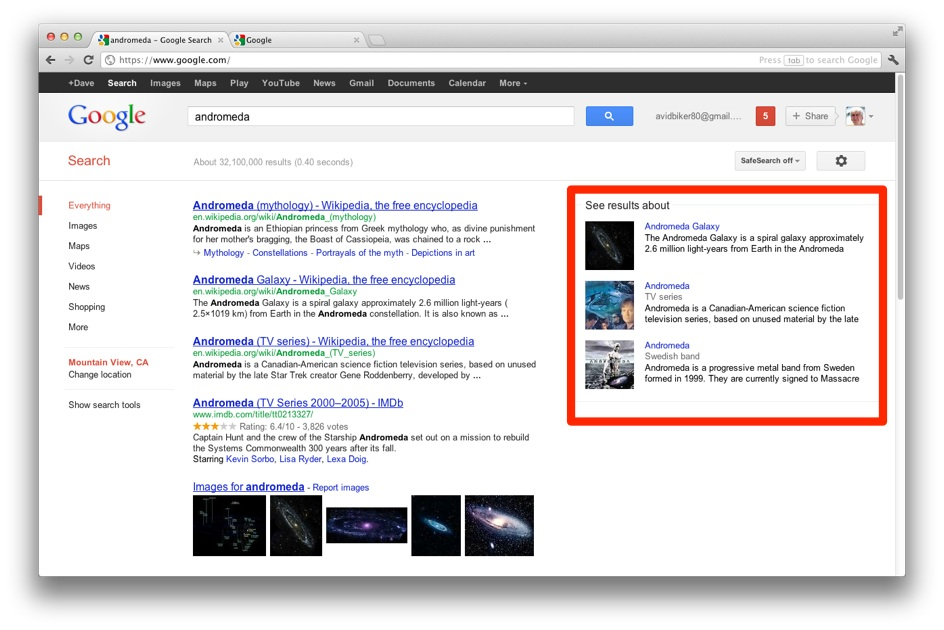 Google подчеркивает, что персонализация поиска в сочетании с семантическим поиском дадут новый вариант релевантности выдачи. Если человек хочет узнать длину реки Миссисипи, ему больше не надо самому рыскать по ссылкам и вчитываться в статью на Википедии, чтобы узнать конкретный факт.
Правда, совершенно не факт, что мы, уже привыкшие разговаривать с поисковиком на определенном языке, поменяем свою стратегию. Мы думаем фразами «купить гарнитуру "овраг" в минске», а более или менее знакомые с поисковиками знают, что «гарнитура "овраг" отзывы» или «гарнитура "овраг" форум» лучше, чем «какая гарнитура самая лучшая» или «где купить лучшую гарнитуру», поскольку два последних запроса с большой вероятностью выдадут рекламные тексты. Семантический же поиск в перспективе сможет сравнивать характеристики техники и на этой основе выдавать пользователю ответ на вопрос.
На данный момент презентационный ролик делает акцент именно на поиске по личностям и фактам. Это область, в которой проще применять семантический поиск, чем в остальных, поскольку она наименее абстрактна. Как подчеркивают представители Google, новый проект – это на данный момент не столько анализ текста, сколько показ релевантной информации. Следующим шагом в улучшении поиска будет корректное удовлетворение сложных запросов на нормальном человеческом языке, например: «Где я могу купить горячие пирожки с грибами с доставкой в Минске в полночь».
Однако неизвестно, какую политику применит Google в случаях, когда ответы будут различаться в зависимости от местоположения пользователя, языка, на котором он говорит, а также времени года, например. Также неясно, будет ли поисковик уточнять (и если да, то как) выдачу для вопросов, на которые не может быть однозначного ответа.
Обычной поисковой строки становится мало для работы со сложными, логически структурированными запросами. Как и Wolfram Alpha, Google предложит пользователю уточнить область поиска в специальном блоке. К примеру, если набрать запрос «Da Vinci», поисковик попросит вас уточнить, имели ли вы в виду художника и изобретателя, одноименную компанию или музыкальную группу (и даже не спросит, действительно ли вы работаете на ее пиар-поддержку), а после обновит страницу выдачи согласно выбранному варианту.
Технологии
Что мы имеем на рынке семантического поиска сейчас? Безусловно, Wolfram Alpha, запущенный в 2009 году. Данные, предоставляемые этой системой, используются как в Siri, так и в поисковике Bing (последний, к примеру, имеет полезную функцию – рассчитывает сложные математические функции). Кстати говоря, сам Wolfram Alpha не является прямым конкурентом Google, поскольку не является поисковиком и ссылки на релевантные документы не возвращает, а лишь вычисляет ответ по собственной базе знаний. Кроме того, этот сервис понимает только английский язык. Какие языки на первом этапе будет понимать The Knowledge Graph, пока не сообщается.
Google подчеркивает, что персонализация поиска в сочетании с семантическим поиском дадут новый вариант релевантности выдачи. Если человек хочет узнать длину реки Миссисипи, ему больше не надо самому рыскать по ссылкам и вчитываться в статью на Википедии, чтобы узнать конкретный факт.
Правда, совершенно не факт, что мы, уже привыкшие разговаривать с поисковиком на определенном языке, поменяем свою стратегию. Мы думаем фразами «купить гарнитуру "овраг" в минске», а более или менее знакомые с поисковиками знают, что «гарнитура "овраг" отзывы» или «гарнитура "овраг" форум» лучше, чем «какая гарнитура самая лучшая» или «где купить лучшую гарнитуру», поскольку два последних запроса с большой вероятностью выдадут рекламные тексты. Семантический же поиск в перспективе сможет сравнивать характеристики техники и на этой основе выдавать пользователю ответ на вопрос.
На данный момент презентационный ролик делает акцент именно на поиске по личностям и фактам. Это область, в которой проще применять семантический поиск, чем в остальных, поскольку она наименее абстрактна. Как подчеркивают представители Google, новый проект – это на данный момент не столько анализ текста, сколько показ релевантной информации. Следующим шагом в улучшении поиска будет корректное удовлетворение сложных запросов на нормальном человеческом языке, например: «Где я могу купить горячие пирожки с грибами с доставкой в Минске в полночь».
Однако неизвестно, какую политику применит Google в случаях, когда ответы будут различаться в зависимости от местоположения пользователя, языка, на котором он говорит, а также времени года, например. Также неясно, будет ли поисковик уточнять (и если да, то как) выдачу для вопросов, на которые не может быть однозначного ответа.
Обычной поисковой строки становится мало для работы со сложными, логически структурированными запросами. Как и Wolfram Alpha, Google предложит пользователю уточнить область поиска в специальном блоке. К примеру, если набрать запрос «Da Vinci», поисковик попросит вас уточнить, имели ли вы в виду художника и изобретателя, одноименную компанию или музыкальную группу (и даже не спросит, действительно ли вы работаете на ее пиар-поддержку), а после обновит страницу выдачи согласно выбранному варианту.
Технологии
Что мы имеем на рынке семантического поиска сейчас? Безусловно, Wolfram Alpha, запущенный в 2009 году. Данные, предоставляемые этой системой, используются как в Siri, так и в поисковике Bing (последний, к примеру, имеет полезную функцию – рассчитывает сложные математические функции). Кстати говоря, сам Wolfram Alpha не является прямым конкурентом Google, поскольку не является поисковиком и ссылки на релевантные документы не возвращает, а лишь вычисляет ответ по собственной базе знаний. Кроме того, этот сервис понимает только английский язык. Какие языки на первом этапе будет понимать The Knowledge Graph, пока не сообщается.
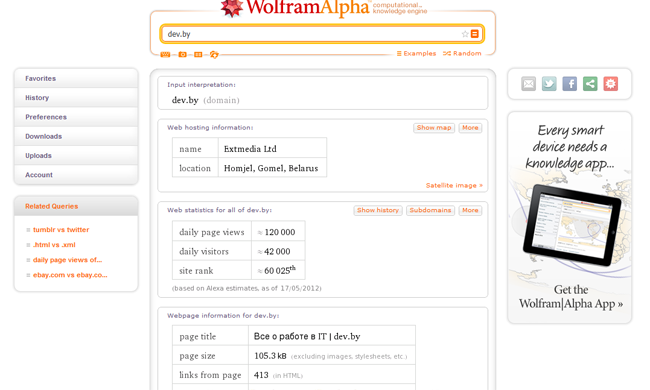 Далее, у ABBYY есть алгоритм анализа ABBYY Compreno, построенный на универсальном семантическом дереве с применением полного синтаксического анализа. Суть этого алгоритма в том, что люди, несмотря на различия языков, используют похожие семантические объекты. Например, все люди спят, едят, большинство людей ходит на работу, тратит деньги, эти понятия есть почти во всех языках.
Однако для более точного поиска системе все равно нужно «знать» языки. И для каждого из них в итоге алгоритм семантической разработки будет свой.
А вот Ask.com выделяет те куски текста, которые содержат прямой ответ на заданный вопрос. Для этого используется три основные семантические технологии:
Далее, у ABBYY есть алгоритм анализа ABBYY Compreno, построенный на универсальном семантическом дереве с применением полного синтаксического анализа. Суть этого алгоритма в том, что люди, несмотря на различия языков, используют похожие семантические объекты. Например, все люди спят, едят, большинство людей ходит на работу, тратит деньги, эти понятия есть почти во всех языках.
Однако для более точного поиска системе все равно нужно «знать» языки. И для каждого из них в итоге алгоритм семантической разработки будет свой.
А вот Ask.com выделяет те куски текста, которые содержат прямой ответ на заданный вопрос. Для этого используется три основные семантические технологии:
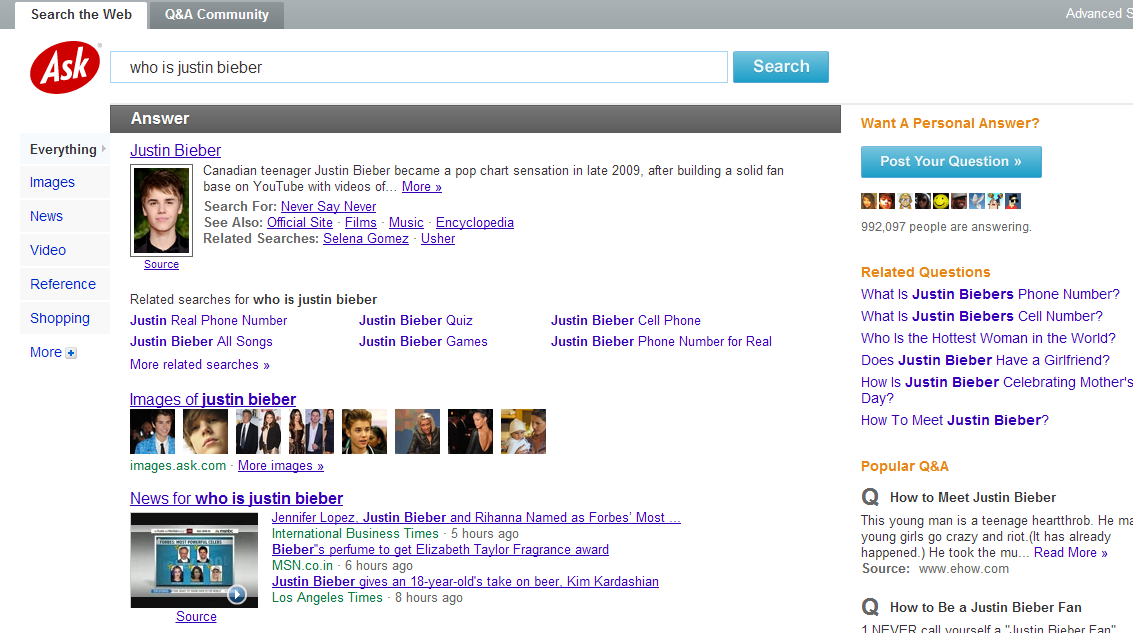
 И, наконец, система Hakia базируется на трех технологиях: OntoSem – хранилище семантической информации, QDEX – технология индексации документов и SemanticRank – компонент ранжирования текстов по смыслу.
И, наконец, система Hakia базируется на трех технологиях: OntoSem – хранилище семантической информации, QDEX – технология индексации документов и SemanticRank – компонент ранжирования текстов по смыслу.
 Также стоит снова упомянуть бесплатную всемирную базу знаний FreeBase, которую можно подключить к своему ресурсу через API.
Похожие функции есть и у других поисковиков (Yahoo, Yandex, Mail.Ru и др). Также на рынке существует еще много сервисов, предоставляющих сервис семантического поиска.
Что такое семантический поиск?
В новом поиске релевантность документов запросу определяется не только синтаксически, но и семантически.
Пример: У нас есть предложение «А, несмотря на неполадки с болидом, обогнал Б на финише Кубка мира и пришел первым», описывающее определенное событие. Положим это предложение на страничку сайта и скормим ее поисковику. После того, как она будет проиндексирована, спросим поисковик: «победитель заезда на Ибице», «чемпион мира гонщик имя». В выдачу наше предложение не попадает, хоть и содержит нужную информацию. Семантический поиск не просто сравнивает объекты, он «понимает» их смысл, и с помощью него мы бы смогли получить ответ на свой запрос, даже если он не содержал ключевых слов.
Данный вид поиска использует сложную многомерную математическую модель и оперирует такими понятиями, как семантическая сеть, семантическая паутина и онтология. Онтология – это формализация знаний с помощью определенной схемы, иными словами, это форма представления знаний. Тут уместно вспомнить господина Вольфрама, который очень любит все измерять, класисфицировать, считать и выводить статистику. Онтологии в информатике выражаются с помощью языков логической базы, таких, как ALF, Alma-0, CLACL, Curry, Fril, Janus, Leda, Oz.
Уникальность всей этой красоты в том, что здесь работает математика, когнитивная психология, лингвистика, семиотика, программирование, библиотечное дело и еще несколько наук. Трудно себе представить себе более распределенный между дисциплинами проект.
Первые вопросно-ответные системы, прабабушки семантического поиска, появились еще в 1960-х годах и использовались как языковые оболочки для узкоспециализированных экспертных систем.
Та же Википедия, ссылаясь на авторитетные сайты, относит семантическую паутину и вопросно-ответную систему к списку «новых перспективных технологий».
Такие проекты, как The Knowledge Graph и Wolfram Alpha, предусматривают необходимость использования огромного количества серверов и дата-центров, а также разработку крайне сложного ПО. В частности, этот метод является областью применения нейронных сетей. Именно самообучающиеся нейронные сети на данный момент являются лучшим средством для семантической обработки и анализа текста в силу таких особенностей человеческого языка, как многозначность, взаимозаменяемость, свободная структура. Кстати, Siri — это разработка Международного центра искусственного интеллекта SRI, который на данный момент занимается крупнейшими проектами в области нейронных сетей и искусственного интеллекта.
Критика
Практически все глобальные источники информации сталкиваются с проблемой проверки предоставляемых фактов. ЖЖ-юзер kelijah приводит интересный пример в этой связи:
«Допустим, что должен делать "семантический поиск" при запросе "лучший амулет для укрепления семьи"? Сказать пользователю, что амулеты и прочая магия – это ненаучный и неподтверждаемый бред, чему есть множество хороших доказательств? Или дать ссылки на сайты с описанием таких амулетов? Исходя просто из формальной логики вывода ответа, и тот и другой вариант одинаково обоснованы.»
По сути, Google столкнется с теми же проблемами, которые есть в Википедии. Полученные с помощью алгоритма данные все равно должны будут регулироваться людьми. Различие с Википедией здесь в том, что в ней это в основном делают сами пользователи, в Google же это будут специально нанятые сотрудники. Это нужно хотя бы потому, что для анализа будут использоваться совершенно различные источники, на которых с большой вероятностью может быть размещена неверная информация. Без человеческого контроля даже злоумышленники наверняка смогут найти способ мошенничества и подтасовки результатов семантического поиска через внешние источники. Тем более что самую основную информацию (например, место и год рождения персонажа) Google будет показывать из собственной базы, а вот остальное уже будет подтягиваться с сайтов вроде Википедии.
Выводы
Семантический поиск, безусловно, улучшит релевантность выдачи. Специалисты считают, что наиболее выгодный вариант – это использовать средства синтаксического анализа вкупе с семантическим, это позволит использовать преимущества как одного, так и другого метода одновременно.
Использование The Knowledge Graph вызывает серьезные опасения у владельцев сайтов. Если пользователь будет получать информацию прямо на странице поисковика, у него не будет нужды переходить по ссылке на сайт. Так как до сих пор основным средством финансирования большинства ресурсов является реклама, то многие веб-сайты, предоставляющие информацию пользователю, могут частично потерять свое финансирование, что теоретически может привести к выборочному ухудшению качества контента.
Семантический поиск в Google – вовсе не первый и уж точно не единственный проект в этой сфере. Но уникальность The Knowledge Graph состоит именно в том, что он несет семантический поиск в массы. Несмотря на определенную популярность Wolfram Alpha, скептики высказывали мнение, что этот поисковик очень специфичен и может использоваться лишь в узких прикладных целях. Например, кому понадобится анализатор текстов книг в том виде, в каком он есть в Wolfram Alpha? Google же предлагает использовать семантику в полном объеме каждый день.
Также стоит снова упомянуть бесплатную всемирную базу знаний FreeBase, которую можно подключить к своему ресурсу через API.
Похожие функции есть и у других поисковиков (Yahoo, Yandex, Mail.Ru и др). Также на рынке существует еще много сервисов, предоставляющих сервис семантического поиска.
Что такое семантический поиск?
В новом поиске релевантность документов запросу определяется не только синтаксически, но и семантически.
Пример: У нас есть предложение «А, несмотря на неполадки с болидом, обогнал Б на финише Кубка мира и пришел первым», описывающее определенное событие. Положим это предложение на страничку сайта и скормим ее поисковику. После того, как она будет проиндексирована, спросим поисковик: «победитель заезда на Ибице», «чемпион мира гонщик имя». В выдачу наше предложение не попадает, хоть и содержит нужную информацию. Семантический поиск не просто сравнивает объекты, он «понимает» их смысл, и с помощью него мы бы смогли получить ответ на свой запрос, даже если он не содержал ключевых слов.
Данный вид поиска использует сложную многомерную математическую модель и оперирует такими понятиями, как семантическая сеть, семантическая паутина и онтология. Онтология – это формализация знаний с помощью определенной схемы, иными словами, это форма представления знаний. Тут уместно вспомнить господина Вольфрама, который очень любит все измерять, класисфицировать, считать и выводить статистику. Онтологии в информатике выражаются с помощью языков логической базы, таких, как ALF, Alma-0, CLACL, Curry, Fril, Janus, Leda, Oz.
Уникальность всей этой красоты в том, что здесь работает математика, когнитивная психология, лингвистика, семиотика, программирование, библиотечное дело и еще несколько наук. Трудно себе представить себе более распределенный между дисциплинами проект.
Первые вопросно-ответные системы, прабабушки семантического поиска, появились еще в 1960-х годах и использовались как языковые оболочки для узкоспециализированных экспертных систем.
Та же Википедия, ссылаясь на авторитетные сайты, относит семантическую паутину и вопросно-ответную систему к списку «новых перспективных технологий».
Такие проекты, как The Knowledge Graph и Wolfram Alpha, предусматривают необходимость использования огромного количества серверов и дата-центров, а также разработку крайне сложного ПО. В частности, этот метод является областью применения нейронных сетей. Именно самообучающиеся нейронные сети на данный момент являются лучшим средством для семантической обработки и анализа текста в силу таких особенностей человеческого языка, как многозначность, взаимозаменяемость, свободная структура. Кстати, Siri — это разработка Международного центра искусственного интеллекта SRI, который на данный момент занимается крупнейшими проектами в области нейронных сетей и искусственного интеллекта.
Критика
Практически все глобальные источники информации сталкиваются с проблемой проверки предоставляемых фактов. ЖЖ-юзер kelijah приводит интересный пример в этой связи:
«Допустим, что должен делать "семантический поиск" при запросе "лучший амулет для укрепления семьи"? Сказать пользователю, что амулеты и прочая магия – это ненаучный и неподтверждаемый бред, чему есть множество хороших доказательств? Или дать ссылки на сайты с описанием таких амулетов? Исходя просто из формальной логики вывода ответа, и тот и другой вариант одинаково обоснованы.»
По сути, Google столкнется с теми же проблемами, которые есть в Википедии. Полученные с помощью алгоритма данные все равно должны будут регулироваться людьми. Различие с Википедией здесь в том, что в ней это в основном делают сами пользователи, в Google же это будут специально нанятые сотрудники. Это нужно хотя бы потому, что для анализа будут использоваться совершенно различные источники, на которых с большой вероятностью может быть размещена неверная информация. Без человеческого контроля даже злоумышленники наверняка смогут найти способ мошенничества и подтасовки результатов семантического поиска через внешние источники. Тем более что самую основную информацию (например, место и год рождения персонажа) Google будет показывать из собственной базы, а вот остальное уже будет подтягиваться с сайтов вроде Википедии.
Выводы
Семантический поиск, безусловно, улучшит релевантность выдачи. Специалисты считают, что наиболее выгодный вариант – это использовать средства синтаксического анализа вкупе с семантическим, это позволит использовать преимущества как одного, так и другого метода одновременно.
Использование The Knowledge Graph вызывает серьезные опасения у владельцев сайтов. Если пользователь будет получать информацию прямо на странице поисковика, у него не будет нужды переходить по ссылке на сайт. Так как до сих пор основным средством финансирования большинства ресурсов является реклама, то многие веб-сайты, предоставляющие информацию пользователю, могут частично потерять свое финансирование, что теоретически может привести к выборочному ухудшению качества контента.
Семантический поиск в Google – вовсе не первый и уж точно не единственный проект в этой сфере. Но уникальность The Knowledge Graph состоит именно в том, что он несет семантический поиск в массы. Несмотря на определенную популярность Wolfram Alpha, скептики высказывали мнение, что этот поисковик очень специфичен и может использоваться лишь в узких прикладных целях. Например, кому понадобится анализатор текстов книг в том виде, в каком он есть в Wolfram Alpha? Google же предлагает использовать семантику в полном объеме каждый день.
 Новым сервисом Google также обостряет конкуренцию с социальными сетями. Чем больше человек остается на страницах Google, тем больше последний может заработать на каждом конкретном пользователе. Пока же мы, простые смертные, ожидаем от The Knowledge Graph жесточайших интернет-мемов, да поэпичнее.
Новым сервисом Google также обостряет конкуренцию с социальными сетями. Чем больше человек остается на страницах Google, тем больше последний может заработать на каждом конкретном пользователе. Пока же мы, простые смертные, ожидаем от The Knowledge Graph жесточайших интернет-мемов, да поэпичнее.

")



Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.