
Как и обещали публикуем обзоры по следам НР Education Day. Это стенограмма очень толкового доклада. Первая часть — это об энтерпрайз виртуализации вообще, о разных ее вариантах, что нового и интересного появилось в виртуализации в корпоративной сети, об обновлениях в VMware 6 и т.д. Вторая часть — как этой виртуальной структурой мы будем управлять, об облаке на базе OpenStack, решение HP Helion, и многих других интересных моментах в корпоративной виртуализации.
Вступление
Свой доклад я подбирал довольно долго. Всё-таки всё, что я предлагал рассказать, кто-то уже чуть раньше меня захватывал. Потому я решил раскрыть ещё тему с другой стороны. Я надеюсь, она будет вам интересна. О чём я хочу рассказать? Первое — это как вообще, что нового и интересного есть в виртуализации в корпоративной сети. А второе — как этой виртуальной структурой мы будем управлять.
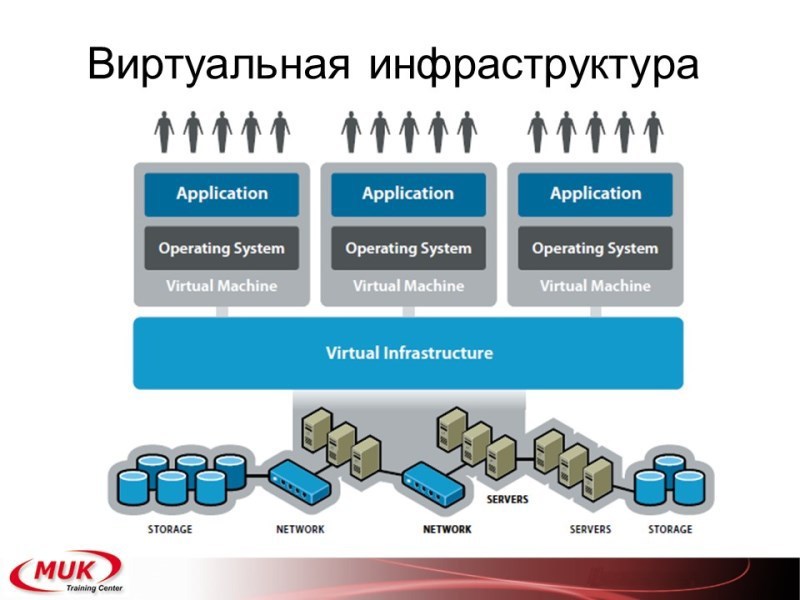
Вот с этого и начну. В самом начале несколько кратких слов о том, что такое виртуализация в смысле использования её в корпорациях. Если мы начинаем говорить о виртуализации, то это распределение ресурсов. И только. Каким образом оно достигается — это уже никого не интересует. Но на сегодня задача виртуализации пошла ещё дальше. Мы теперь делим не только ресурсы, мы теперь ещё делим и функциональные обязанности. Если раньше мы говорили: сформировали блок систем хранения данных, сформировали блок вычислительной мощности, сформировали виртуальную сеть, — то теперь у нас ещё отдельная структура для управления самой аппаратной частью виртуализации, отдельная уже для работы с пользователем, отдельная для мониторинга, отдельная для анализа.
Несколько слов по поводу анализа возможностей инфраструктуры: вам уже рассказывали и BSM, рассказывали и аналитику. Я говорю немного о других вещах.

Если мы говорим о виртуальной инфраструктуре, то у нас появляются довольно большие проблемы. Какие? Во-первых, если мы используем разделение ресурсов, разделение обязанностей, у нас появляется более сложная структура. Чем больше у нас наших компонент, тем сложнее получается структура. Система быстро меняется. Вам нужно машинку — вы её создали, вам она не нужна — вы её уничтожили, вы перенесли машину из одного дата-центра в другой — у вас появились новые программы, у вас исчезли старые. У вас теперь появляется довольно много оборудования, которое находится в общей ответственности, где есть несколько администраторов, которые в общем-то в разных отделах. Если вы начинаете делить зоны ответственности и делить ресурсы, у вас появляется необходимость использовать политику обеспечения качества (quality of service).

Как правильно управлять этой структурой? А нужно взять и поделить её на уровни. Ничего лучше не придумали, лет 50 или 60 назад, когда начиналась только IT-инфраструктура, начали именно с этого: а давайте мы сложную структуру поделим на уровни, и каждый уровень мы будем предоставлять отдельно, и каждый уровень — мы будем с ним заниматься совершенно отдельно. Давайте рассмотрим немножко вот эти уровни, а потом перейдём к общей структуре.

Первый уровень — это, конечно, ресурсы вычисления. Сюда входит ЦПУ, сюда входит память, сюда входит какая-то шина передачи данных, хост-бас адаптеры. Что у нас тут интересного? Тут интересные пулы. Мы создаём ресурсные пулы, мы создаём кластера как высокой доступности, так и управления ресурсами. Сюда же мы добавляем правила совместного замещения машин (affinity, anti-affinity, включаем резервирование, включаем задачи). Плюсы: аппаратная виртуализация. Какая? Во-первых, ЦПУ. Плюсы аппаратной виртуализации в том, что мы получаем возможность больше времени отдать на задачи пользователя, а меньше — на служебную работу по самой виртуализации. Есть аппаратная виртуализация ЦПУ, есть аппаратная виртуализация шины.
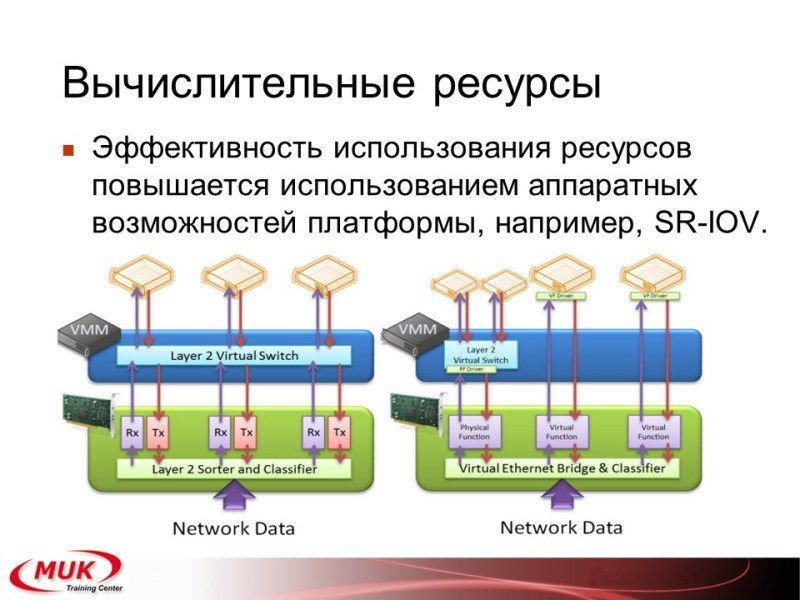
Аппаратная виртуализация шины, например, SR-IOV, позволяет вам передать почти прямое управление нашим виртуальным машинам в прямой доступ к аппаратной платформе. Если обычная, даже довольно хорошо структурированная, система работала с виртуальной софтварной прослойкой, то, используя виртуализацию шины, мы можем обращаться напрямую к аппаратным функциям наших хост бас адаптеров. Плюс в том, что ЦПУ хоста уже не занимается обработкой этих задач.

Второй блок. Система хранения данных. В чём состоит её виртуализация? Виртуализация состоит в том, что мы эту систему хранения данных делим на маленькие кусочки и начинаем распределять между всеми виртуальными машинами. Плюс такого подхода очевиден. Ну, во-первых его начали использовать абсолютно все аппаратные решения.
А в чём же очевидная польза? Мы получаем гибкость. Разделённый на кусочки и собранный в виртуальные разделы диск гораздо легче увеличить, уменьшить, передвинуть, оптимизировать, перевести из режима сим в си и вернуть наоборот, сделать резервную копию, сделать снэп-шот, восстановить, одним словом обеспечить нужное качество услуг. Дополнительные возможности, которые нам предоставляет такая виртуальная система хранения данных, — это интеграция с аппаратной платформой через различные методы акселерации. Ну, например, в VMware связь с аппаратными стореджами и передача команд вместо того, чтобы записывать реальные данные. Wrightsame, wrightzero, то, что уже упоминали сегодня, что используется в thin provision. Эти же технологии, например, используются при создании резервных копий при сторедж в емоушн, при миграции, их же можно использовать и при построении кластеров высокой доступности. Когда вы реально переключаете виртуальную машину с одного хоста на хост и при этом прозрачно переходите с одной системы хранения данных в другую систему хранения данных.

Виртуальная сеть. Если мы начинаем говорить о виртуальной сети — это анализ пакетов, которые передаются между нашими виртуальными машинами. Тут для нас очень важно:
Первое. Обеспечить все те протоколы, которые нам необходимы в обычной сети.
Второе. Обеспечить связь с аппаратными компонентами сети, с теми же свичами, которые вы устанавливаете в обычной сети.
И третье. Как можно сильнее разгрузить работу центрального процессора.
Как это можно сделать? А это можно сделать точно тем же подходом, который делают обычные коммутаторы и обычные роутеры уже довольно давно. А именно: например, cisco express forwarding. Мы используем две таблицы. Одна таблица, которая отвечает за коммутацию пакетов, а вторая таблица, которая отслеживает топологию и при изменении топологии меняет таблицу коммутации. Вот такой вот вариант, например, строится уже в технологии OpenFlow, который на сегодня внедряется во все варианты виртуализации, в том числе используемые и реально предлагаемые компанией HP.

К чему всё это приводит? А всё это приводит к тому, что большинство дата-центров идут в сторону облачных технологий. Тут естественно возникает вопрос простой: а нужно ли это вам? Вопрос непраздный, потому что всё зависит от того, какая сеть у вас реально есть. То есть, если у вас три ESX-а, то облачная сеть вам пока ещё не нужна. Если у вас 30 уже можно подумать. Если у вас 300, то, наверное, уже стоит как бы переходить. В чём плюсы облака? Плюсы облака в том, что вы отделяете систему управления машинами, аппаратными машинами по виртуализации, и систему в создании новых операционных систем новых приложений. У вас получается два администратора. Один вам обеспечивает работу железа, а другой предоставляет интерфейс уже для пользователей. Пользователь, создавая новую виртуальную машину, вообще не представляет, а что реально у вас находится там на аппаратном уровне.
Более того, на сегодня мы идём к следующему этапу (как бы кто-то уже пришёл, кто-то ещё думает, кто-то как раз на сегодня работает), когда мы создаем не операционную систему виртуальной машины, а готовое приложение. Вам нужно веб-сервер как фронт-енд, вы его создаёте. Вам нужен веб-сервер как бэк-енд с джавой, вы его создаёте. И вас уже даже не интересует, какая там операционная система. Вас интересует, что там будет контейнер, на котором будет работать ваше приложение. Вот примерно так же и работает, нужно ли это вам сейчас, думайте. Почему? Потому что такая гибкость и такая простота, она оборачивается бОльшим потреблением ресурсов и бОльшей сложностью настройки. То есть да, если вы это делаете постоянно, лучше сделать один раз, после чего всё будет работать. Если вам нужно создавать новые машины раз в две-три недели или раз в месяц, понятно, что пока овчинка не будет стоить выделки. Но смотреть на эту технологию, опять же, тоже надо.

Само облако предоставляет три таких этапа (это по стандарту, который идёт по НИС, по американскому институту стандартизации):
Этап номер один. Он самый низкий. Инфраструктура как сервис. Это то, к чему сейчас уже почти все большие дата-центры пришли, и с чем, думаю, что вам тоже придётся работать, — предоставление ресурсов по требованию. Вам нужно знать операционку, вам нужно сделать свич, вам нужно для виртуальной машины дать несколько выходов в Интернет. Вот это — инфраструктура как сервис. Вы ещё не привязываетесь ни к каким приложениям. Вы просто при необходимости создаёте несколько новых операционных систем с заданными параметрами по подключению.

Этап номер два. Платформа. Вы используете её для совместной разработки приложений. Плюс состоит в том, что вас уже не интересует операционная система. Ваша задача — это совместно большой командой (или не очень большой командой) разрабатывать и запускать какие-то приложения в жизнь, с возможностью запуска на обычной машине, внутри вашего личного виртуального дата-центра или переноса в классическое публичное облако, на какой-нибудь Амазон либо HP-хореон, который мы сегодня тоже немножко посмотрим.

Самый верхний уровень, завершение всей пирамиды — это Software per Service. Что тут есть — предоставление просто взаимодействия библиотеки API, которое позволяет вам использовать приложение, когда оно нужно. Вы покупаете приложения на нужный вам период времени. Например, вам нужен офис? Вы его купили. Вас не беспокоят ни патчи, ни обновления, ни отслеживание по времени. Вы получаете полный набор доступа по взаимодействию с этим софтом. Вы можете создать новую машину с офисом, с апачем, с базой данных. Можете её удалить, если она вам уже не нужна. Активировать и деактивировать.
Кто всё это делает? И тут мы переходим к тому вопросу, с которого я начал. У нас есть два уровня:
Уровень номер один — это виртуализация, которая работает на реальной аппаратной платформе. Мы с неё начнём, потом перейдём к уровню номер два.
Что нового появилось
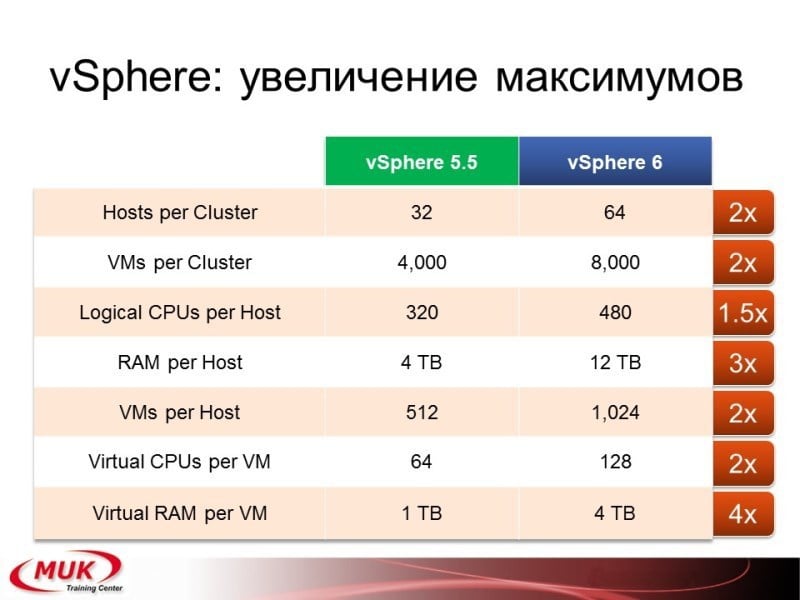
Начнём с VMware. Почему? Ну он самый популярный, как же без него? Наиболее поддерживаемый. Вы знаете, что уже вышла шестая версия гипервизора VMware и системы одновременно. И в шестой версии появилось довольно много интересных возможностей. С чего мы начнём? Увеличение максимумов. Сложно сказать, где были большие проблемы, но в общем-то, максимумы увеличились довольно серьёзно. Из наиболее интересных увеличений максимумов — это Fault Tolerance с машинами. Кто был на курсах VMware, тот знает, что вы рассматривали Fault Tolerance — очень интересное решение, работает всегда на двух машинах. В конце инструктор всегда говорил: «А использовать вы его не будете, потому что оно бесполезно — всего один цикл». Так вот, начиная с шестой версии уже можно делать четыре цикла. Теперь вы уже можете строить четыре виртуальных ЦПУ. Теперь эта Fault Tolerance машина пригодится вам не только для демонстрации того, что VMware может создавать непадающие машины.

Второй уровень. Если у вас совсем мало гипервизоров, и вы не планируете, в общем-то, расширять вашу сеть, а это как бы для маленьких компаний очень даже нормально, то теперь VMware предоставляет вам возможность создавать локальных пользователей. Это была проблема, на самом деле, нужно было либо внешний уже домен, либо использовать вход через командную строку и через ПВ, и через вэб-юзер, добавлять пользователей и потом уже с ними работать. Так вот, начиная с шестой версии, появилась возможность через стандартный интерфейс VMware создавать нового пользователя. Плюс не нужно вам уже делать внешнюю систему авторизации. Правда, потом куча минусов, но как бы вопрос в том, что это уже можно.
Вопрос из зала: «А можно, какой-нибудь самый вот «основной» минус? Если вдруг захочется создать, чего опасаться в первую очередь?»
А если у вас локальный пользователь, то у вас как бы скажем работа уже в кластере. Вам нужно V-центр, где эти локальные пользователи вообще не видны. У локального пользователя доступ только на один хост. Вот это главная проблема, чего надо опасаться. То есть тут только вот это. Он не масштабируемый. Всё остальное, ну как бы если у вас маленькая сеть — это замечательная штука. Потому что у меня самого были случаи когда поднимаешь две-три-четыре машины, нужно ставить V-центр, иначе как бы не получается работать, а так быстренько создал пользователей и они спокойно себе из V-центра даже работают. Если кластер не нужен, миграция не нужна. Дополнительные возможности по блокировке пользователей, если неправильно зашёл, установка правил сложности, ну как бы это уже тоже не интересно.

Что ещё? Усовершенствованные драйвера, и появились новые, включая модуль для ядра для поддержки графических акселераторов Intel и Nvidia. То есть вы можете их теперь полностью использовать как акселератор для виртуальных машин. Но есть одно замечание. Они не могут работать как консоль. То есть если уже их используете как консоль, значит уже нельзя их использовать в полном режиме акселерации.

Всё дальше и дальше у нас идёт процесс миграции, в версии 5.5, если я не ошибаюсь, или 5.1 появился Enhanced vMotion, который позволял одновременно менять хост и сторидж. Но он работал только через веб-клиент и не поддерживался кластером. На сегодня появилось ещё два варианта миграции. Это cross switch vMotion, который вам позволяет менять одновременно ещё и свич. Помните, было ограничение, что у вас должен быть при миграции одинаковый либо стандартный свич на двух хостах, либо один распределённый. Теперь можно менять и свич, но требуется, чтоб это всё было в одной L2 сети. Грубо говоря, это смена, даже не vlan на vlan, какая-то группа портов, потому что ip-адрес при этом у вас не меняется. Но вы можете переехать, а потом передёрнуть интерфейс и у вас поменяется ip-адрес. Автоматом меняться не будет. То есть, ip-адрес остаётся.
Вопрос из зала: «Как с DRS-ом эта операция происходит?»
По-моему, ещё никак. Ещё пока никак, да. С DRS-ом то же самое, что было и с Enhancer vMotion. Она есть, но сама по себе. А в DRS она не используется. То есть это больше ручной движок.
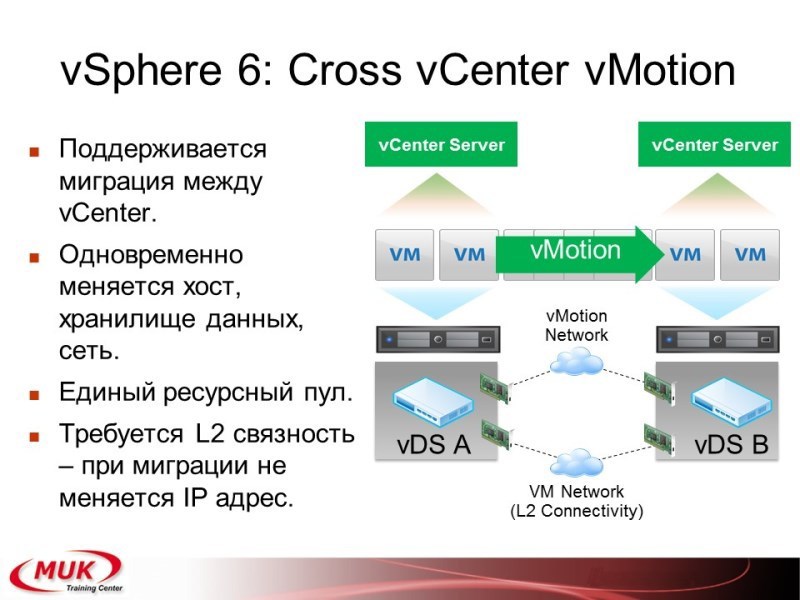
И ещё один вариант — это Cross vCenter vMotion. Горячий переезд между двумя V-центрами с полной заменой свича, хоста и сториджа, но отсаётся только один ip-адрес. Что ещё при этом может быть? Вы можете создавать ресурсный пул и на одном, и на другом хосте, и при этом ограничивать ресурс вот этой виртуальной машины. То есть машина и при переезде всё равно будет подчиняться правилам по ограничению ресурса. Но тоже это только в ручном режиме.

Ещё одна интересная возможность — Content Library. Решение давно напрашивалось. Раньше говорили как. Вот вам NFS-шара, и через NFS-шару все исошники расшаривались. Что можно сделать теперь? Теперь создаётся специальная служба. Служба работает на всех v-центрах. Единая база, которая в себя по дефолту включает работу с vApps, с образами, с шаблоном виртуальных машин, со скриптами, плюс без всяких дополнительных функций можно держать любые типы файлов. Как это работает? У каждого V-центра есть свой набор инсталляций. Но вы можете сказать: V-центр номер один расшаривает шаблоны виртуальных машин на V-центр номер два. V-центр номер два по умолчанию ставит себе линк, что вот, на V-центре номер один, есть интересующий меня образ машины. А если нужно развернуть эту машину, то он перетягивает шаблон уже себе на хранилище. Получается такая вот распределённая база с таким федеративным или on demand хранилищем, когда вы перетягиваете только то, что вам нужно. Сама библиотека может быть как публичная, так и частная. То есть вы либо расшариваете для всех, либо определяете круг машин, которые всё это будут поддерживать.
Вопрос из зала: «А там транзитивность работает? Хост номер один расшаривает для хоста номер два, хост два для хоста номер три. Третий хост первую «шару» видит?»
Честно говоря такого варианта я даже не знаю, потому что если вы расшариваете многим, рекомендуется сделать паблик. И паблик они уже видят. А вот с цепочкой частных я ещё не крутил. Я посмотрю, точно сейчас сказать не могу. Но посмотреть можно.
Новые возможности. Network I/O Control версии 3.

Network I/O Control версии 3 позволяет вам давать гарантированную полосу для каждого интерфейса виртуальной машины. Плюс есть возможность устанавливать опять же по подгруппе. И в дополнение к тому, что свичи, один и тот же свич может использовать совершенно разные машины, создаётся multi tennant среда. То есть тенант — это такой блок, куда входит несколько портов или подгрупп. По каждому из этих блоков вы можете создавать свои резервирования, которые не будут влиять на остальные подгруппы. То есть куда ушла VMware6? Они ушли по правильному направлению опять же управления ресурсами. С виртуализацией всё понятно. Пока ничего нового аппаратного не появится, что-то новое софтварное сделать не получится. А вот управление ресурсами они как бы взяли довольно серьёзно.

Storage IO Control. Новая версия уже от интеграции с массивами и в сторидж дайрект появилась возможность кроме thin provision, которая там была, сделали уже нормально: дедупликация, определение по классу услуг и создание снэпшотов. Плюс опять же резервирование на каждый диск по Iops-ам. Количество Iops-ов, которые вам гарантируют, раньше было только балансировка. Сейчас уже можно гарантировать, сколько Iops-ов вы можете получить.

Ещё один вопрос, который сегодня уже поднимался — это Virtual Volume. Что такое Virtual Volume? На самом деле непонятно вообще-то, почему раньше это не сделали, но задача очень простая. Смотрите, у вас есть 20 жёстких дисков и есть 10 виртуальных машин. Как можно их поделить? Можно дать каждой машине по два диска. Тогда будут какие-то диски переполнены, какие-то недогружены. А можно взять каждый жёсткий диск поделить на кучу маленьких блоков и раздавать их виртуальным машинам по одному блоку. Сегодня уже говорили, что в 3PAR это называется chunklets, ну на самом деле, ещё раньше было овм, где вот эти маленькие блоки называли physical extent. Вот Vmware решил не путать терминологию и назвал их по классике: physical extent. Значит, мы теперь создаём контейнер. В контейнер входит какое-то количество жёстких дисков. Каждый жёсткий диск делится на кусочки, и виртуальная машина, когда она создаёт свой уже диск для работы, она эти физикал экстенты набирает столько, сколько ей нужно. Таким образом в одном контейнере у вас могут находиться совершенно разные виртуальные машины. И на каждый из вот этих виртуальных вольюмов мы можем устанавливать свои политики. Ну подход абсолютно такой же, как в 3PAR. Кстати, разработчики Vmware, они написали, что мы это сделали потому, что вот именно так получается полное соответствие аппаратной структуры системе хранения данных. Ну как 3PAR — именно также он и работает, только у него называют это группы, команд провижн груп, и «виртуал вольюмы», которые создаются внутри этих команд провижн груп.
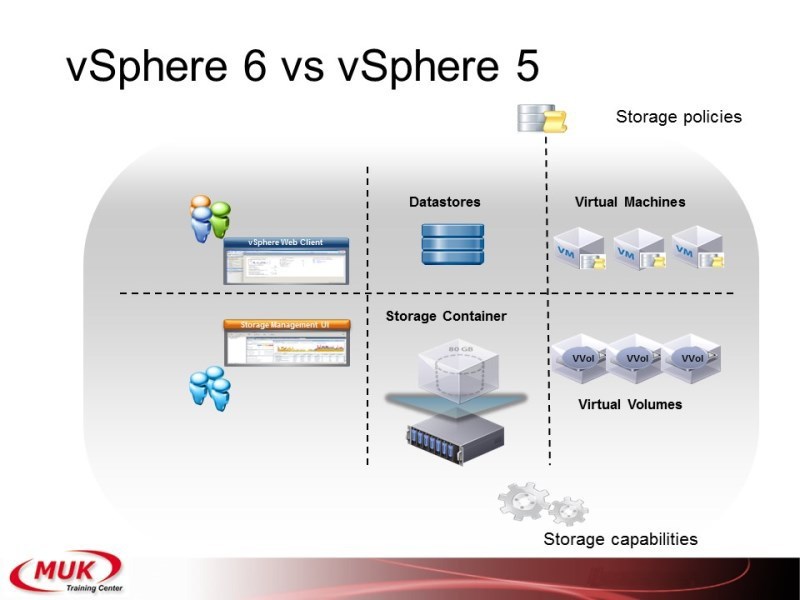
Вот такие вот получаются у нас отношения.
Есть дата-стор, на которых мы нарезаем вольюмы. Теперь есть сторидж-контейнеры, где мы нарезаем вольюмы в виртуальных машинах. По поводу того, что где работает, был слайд, останавливаться пока не будем. Я думаю, что в ближайших релизах будет расширение функционала, потому сейчас, наверное, даже нет смысла тонко разбирать, а что именно работает, а что не работает с виртуал вольюмами.
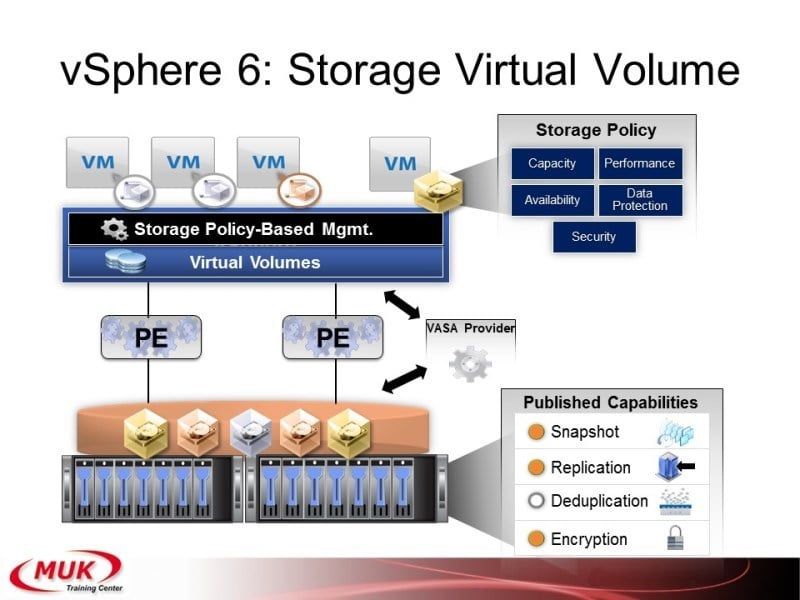
Ну и вот примерно вот такая получается структура, поддерживается снэпшоты, поддерживается репликация, дедупликация, поддерживается криптование и получается гораздо гибче идёт теперь управление жёсткими дисками. Миграции опять же теперь уже можно будет делать, которые ещё не сделали, но надеюсь, что таки скоро обеспечат. Так, вот они, контейнеры.
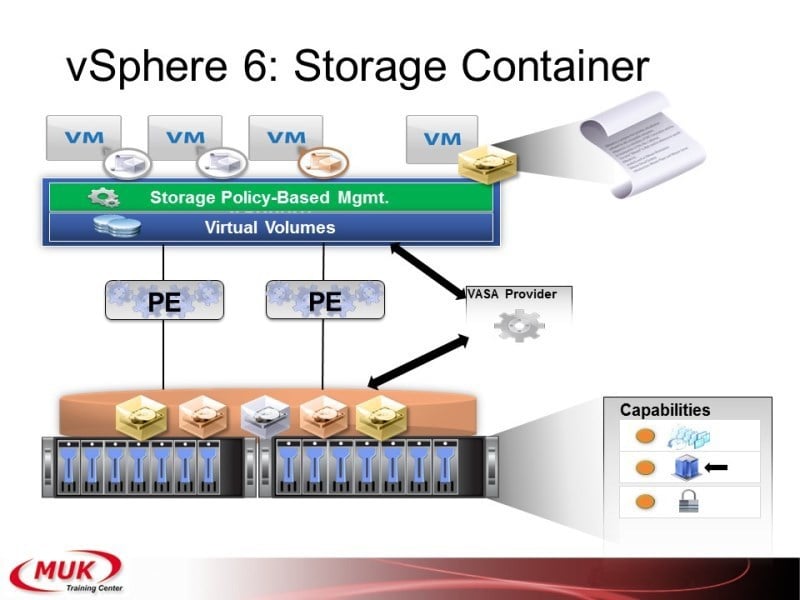
Вот кратко о том, что интересного появилось в шестом Vmware. Ну, более подробно, есть опять же, двухдневный курс, со всеми уже детальным характеристиками, и там можно посмотреть, поэкспериментировать, поспрашивать.
Виртуализация OpenSource

Ещё один вариант виртуализации, которая в последнее время набирает такой довольно хорошей уже популярности (хотя эта виртуализация совсем открытая, но её поддерживают и довольно большие компании). Что это за компании? RedHat довёл её до ума, HP активно использует решения и от RedHat, и от SUSE. Это виртуализация Linux. Виртуализация в Linux поддерживается несколькими путями. На сегодня это два основных пути.

Первый — виртуальные машины — KVM. Второй — это контейнер. Чем хороши виртуальные машины? Виртуальные машины — это та же виртуализация, что у Vmware или Гипер-V. Вы создаёте операционную систему, полностью, она полностью изолирована от других систем, виртуальные свичи, виртуальные стореджи, функционал примерно такой же, как и у Vmware. Работает, кстати, на том же самом принципе, который у QEMU. Vmware хорошо его переделала, но как бы тут тоже появились свои интересные возможности.
Виртуализация КVМ — это стабильные хорошие решения. Есть даже готовый от RedHatА набор, который называется RedHat Enterprise Virtualization. Они его пробовали делать похожим на V-центр, но немножко со своими особенностями. Есть открытый аналог, который довольно сырой, честно говоря, использовать его в продакшене я бы не советовал, но для тестирования можно его посмотреть, поиграться с ним.
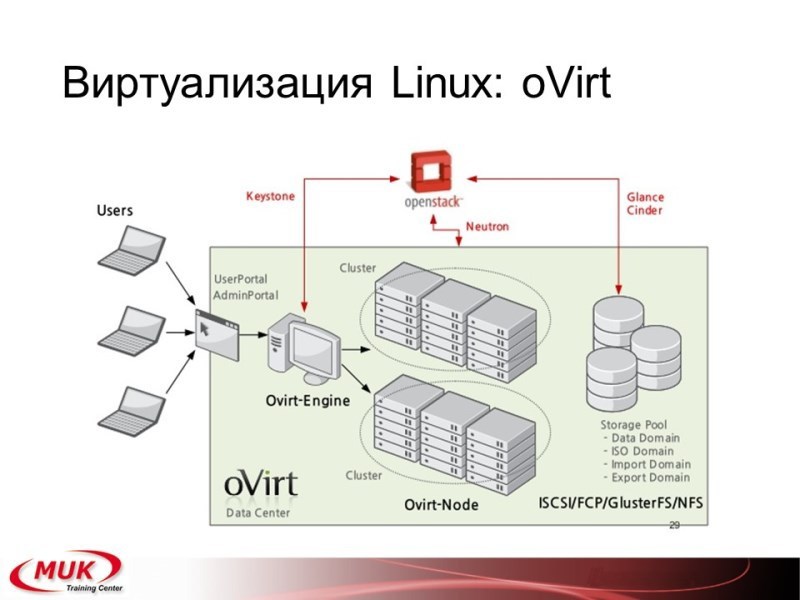
Но есть RedHat Энтерпрайз виртуализейшн, который вы можете использовать для конфигурации быстрой надёжной эффективной, и есть открытое решение, которое называется oVirt. OVirt на сегодня, кстати, интегрируется OpenStack-ом и если они завершат интеграцию, то мы получим ещё один вариант готового хорошего стабильного облака. Если не завершат, то будем пользоваться тем, что доступно уже на сегодня.

А вот кроме KVM классика, есть ещё один вариант, который нечасто используют, хотя на самом деле он очень эффективный с точки зрения управления ресурсами. Это называется контейнеры. Контейнеры работают не только в Linux-е. Вот один из таких классических вариантов контейнера — это солярис-зоны. Пример точно тот же. В чём плюс контейнера? Если вы используете VMware, вы на 10 виртуалок создаёте 10 независимых операционных систем. Каждая из этих операционных систем использует одно и то же ядро, одни и те же библиотеки, использует место на диске под эти библиотеки и оперативную память для работы. Да, вы скажете, что вот сейчас виртуализация, она пошла вперёд, используется вылавливание одинаковых блоков памяти, ссылка на один блок реальной памяти, экономия ресурсов, но на самом деле десять виртуальных машин всегда будут занимать места больше, чем одна. Контейнеры — это одна виртуальная машина. Но на уровне драйвера ядра вы создаёте десяток или больше совершенно независимых ресурсов. У каждого из этих ресурсов своя область пользователей, своя область процессов, своя область дисковых систем и только основные библиотеки у них ссылаются на одну и ту же область на диске. Раньше использовался lxc контейнер. Использовался он довольно долго, но как бы сегодня ему на смену пришёл такой интересный подход, который называется docker. Собственно для чего я и начинал виртуализацию Linux.
Что такое docker?

Docker — это новый вариант контейнера. Он разрабатывался под Linux, но на самом деле он работает и под другие операционные системы. Отличие docker от стандартного lxc о том, что вы теперь создаёте образы операционных систем с готовыми приложениями. Плюс регистрация в облако, создание единых репозиториев, обновление, разворачивание, удаление, активация, деактивация — всё это входит опять же в готовый блок. То есть фактически вы получаете — лёгкое облако на уровне операционной системы, без дополнительных средств.
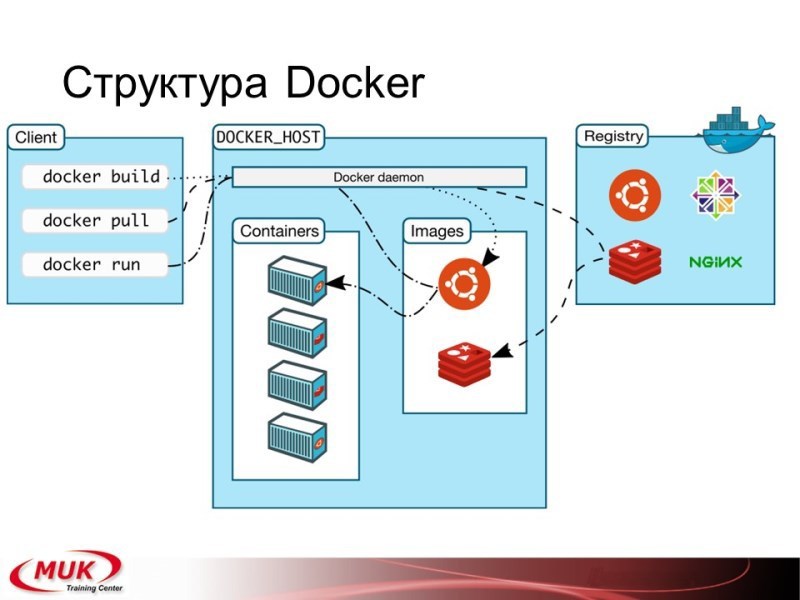
Что он в себя включает? Клиент, который может создавать заготовки, запускать приложения или проталкивать репозиторий. Хосты — это наши машины по виртуализации. Тут находятся контейнеры, в которые мы загружаем образы, один-два-три и больше. И репозиторий, откуда мы можем все эти образы забирать или куда мы можем эти образы отдавать. Фактически вы получаете сразу и облако, и возможность совместной работы над разными приложениями. Да, недостаток такой системы — у нас одна операционка, потому эмулировать Windows на Linux-е у вас не получится. Но вы можете использовать в рамках docker-а тот же kvm и делать полную виртуализацию для другой операционной системы. На сегодня docker работает ещё под мак-осом. Есть попытки что-то делать под Windows, надо посмотреть…

Вопрос из зала: «На Linux работает или только на RedHat?»
На всех. Это не RedHat-овское решение. Просто RedHat предлагает сразу вам это всё устанавливать в свой репозиторий. То есть на самом деле вы можете использовать любой вариант. Причём там сейчас идут варианты, как эти приложения можно мигрировать с одного типа операционки на другой. То есть если вы оставляете свои конфиги, а меняете полностью все бинарники операционной системы, вы, в принципе, можете запускать и на чём-то другом. Ну это как бы тут ещё не продакшн. Это не стабильное решение. То есть проблема именно в том, что всё это находится в одной операционной системе и вы экономите и ресурсы, и место на диске. Но система изолирована полностью уже для управления.
Теперь переходим к этапу номер два: а как всем этим управлять?

То есть задача в чём? Вы усложняете вашу структуру, и в какой-то момент у вас получается, что ваша система мониторинга, уже управления и мониторинга, они становятся очень сложными.
Есть два варианта. Усложнять систему управления и дальше, или попробовать разнести всё это на несколько уровней. Вот один из вариантов по управлению. В компании HP очень долго работал такой продукт, который назывался System Insight Manager — СИМ. Потом он входил в большой пакет, который назывался «Инсайд контрол». Пакет обеспечивал мониторинг, установку, конвертацию, сбор данных, различные варианты автоматизации и т.д.
Что дальше? Да, кстати, пакет как бы набирал вес, за несколько лет он вырос с четырёх гиг до шестнадцати — этот минимум необходимых для работы оперативной памяти, да, и потом как бы подошёл такой момент, когда стало уже нужно соединять довольно большие объемы серверов, а особенно всё это было применено к корзинам, то есть тем самым блейдам, о которых мы уже говорили.
Что в себя включал блейд? Блейд в себя включал и включает 8–16 серверов, до 8 свичей, появился виртуал коннект, который позволял делать уже профили и эти профили перебрасывать с одного порта блейда на другой, он позволял устанавливать мак-адреса, вэвэны, нарезать полосу пропускания — всё это понемножку вводилось в инсайд контрол, хотя параллельно был — виртуал коннект менеджмент. Дальше разработчики решили сделать так: а давайте мы сделаем единую утилиту, которая будет в себя включать и Инсайд контрол, и Виртуал коннект менеджер и позволит нам нормально работать с этим оборудованием.
Основные задачи, которые выдвигались: идентификация компонента, собирать данные о состоянии, посмотреть, как связаны разные компоненты между собой, различные системы по отслеживанию событий, сколько у вас уже идёт совместная работа и выполнение разных задач, ну и конечно, информация о том, что и как у вас работает.
One View

Что даёт One View? Большой дашборд. Вы его уже видели. Он показывает вам полностью информацию о вашем центре, куда входят сервера, обычные сервера стоечные, куда входят блейды. Что дальше? В зависимости от того, какое это оборудование, вы можете либо получать полный доступ, либо частичный. Ну опять же лицензия даёт либо полный доступ, либо частичный доступ по управлению. Недостаток, кстати, большой на сегодня OneView — то, что оборудование, которое постарше не поддерживается и скорее всего поддерживаться не будет. Ну например, корзины 3000-ые им не поддерживаются, а 7000-ые им поддерживаются.
Дальше. Поиск идёт. Карты. Мап вью, которые вам показывают (мы чуть в большем формате посмотрим) различные шаблоны для отработки задач. Информация для создания предупреждений о том что у вас работает и как.
Примеры конфигурации
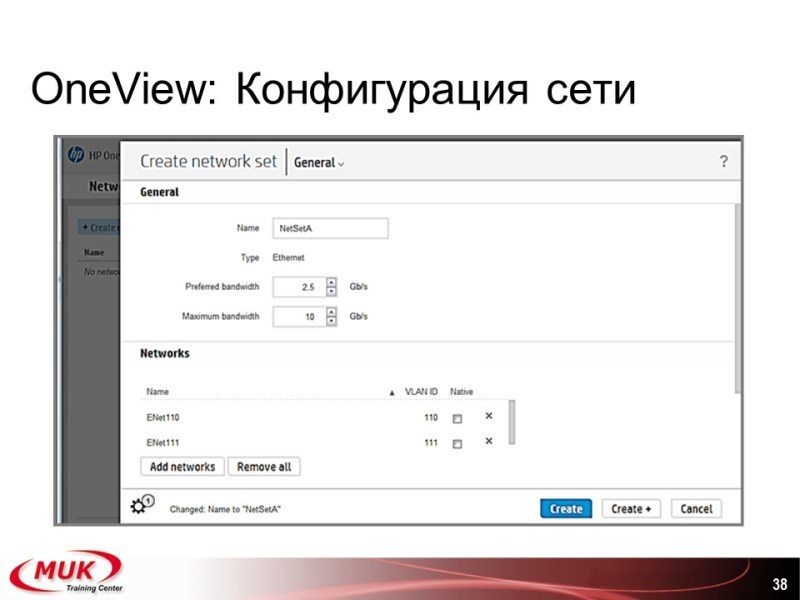
Что вы создаете? У вас есть сервер, у вас есть сторедж, у вас есть свич. Например, вы берете создаете свич. Вы видите: v-lan такой-то, полоса такая-то, привязан или использует сети такие-то. Кто работал с виртуал-коннектом, всё очень похоже. Оттуда и взято. Эти все пункты взяты почти полностью.
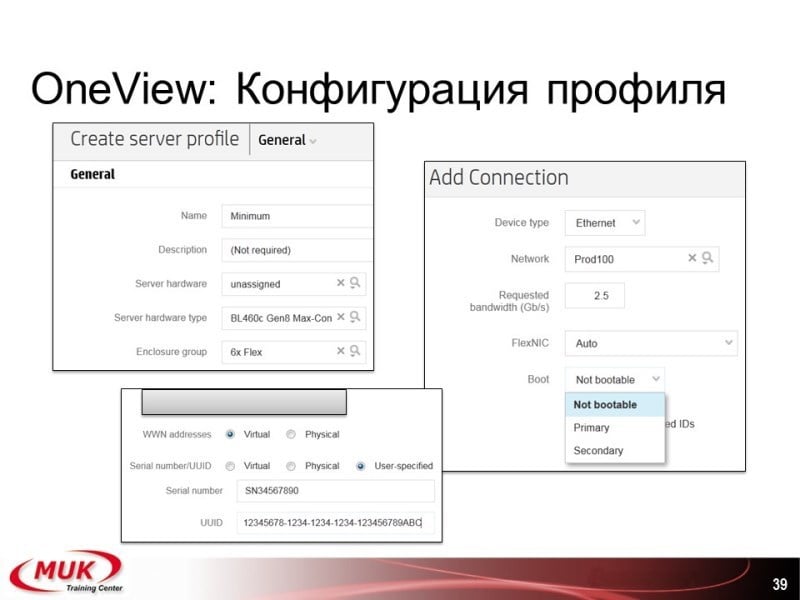
Конфигурация профиля для сервера: создаем профиль, привязываем к платформе, группе, устанавливаем различные адреса, вэвээны, мак-адреса, порты, полосы.

Визуализация — сеть, порты, что сюда подключено.
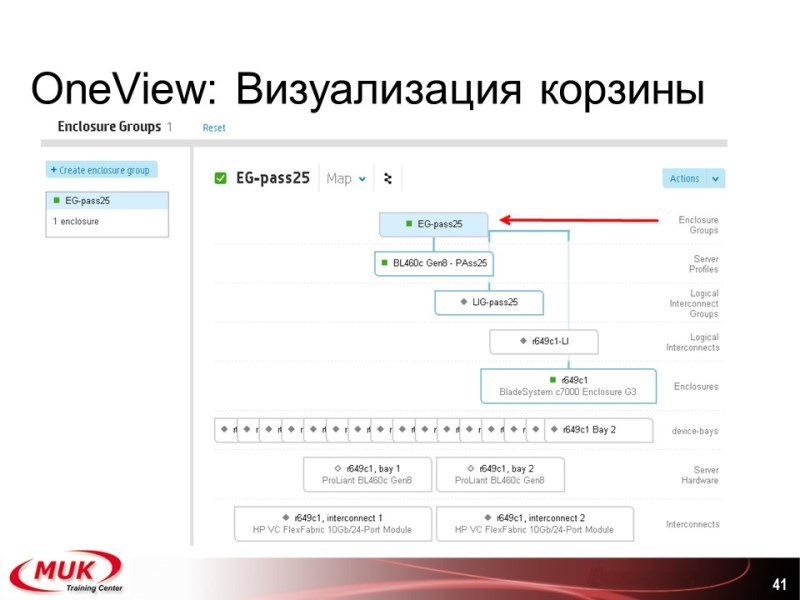
Корзина. Вот она — связь, компоненты, все сервера, которые входят, и дальше мы уже опять же просматриваем отдельные компоненты.

Сервер — то же, что у нас входит, сколько лезвий, если у нас есть несколько лезвий, и так далее.
Вот такой получается подход, с которым уже можно работать. По поводу ресурсов. Ещё больше, чем инсайд контрол. Конечно, куда же без этого. Считается, что память у нас дешевая, потому можно ставить много.
Облачная инфраструктура с помощью НР Helion OpenStack

Этап следующий. У вас есть инфраструктура. У вас есть, скажем там, куча иэсиксов или хостов с RedHat-ами или чем-то ещё. Теперь вы хотите эту инфраструктуру либо отдавать в управление разным отделам вашей компании, либо продавать. Задача какая? Вам нужен инструмент. Инструмент, с помощью которого локальный админ может создать себе 1-2-3-4-10-20 виртуальных машин, создать свич, активировать эти машины, выключить их, перенести на другой хост уже автоматом, если у вас что-то вдруг случится. Вот для этого используются различные варианты облачной инфраструктуры.
Одним из очень интересных решений был и остаётся OpenStack. Ну OpenStack как открытое ПО, оно остаётся довольно сырым. Да, это решение хорошее, но проблема состоит в том, что оно требует довольно серьёзного времени, усилий и знаний, чтобы его нормально настроить. Разные компании, большие компании, используют OpenStack в своих личных целях. Это мощно. Один из примеров — это HP Helion. Они его так и называют HP Helion OpenStack. Что сделала компания HP? Они взяли решение OpenStack, своё оборудование и разработали систему, которая будет довольно легко и просто устанавливать вот этот самый OpenStack на правильное железо. Ну, а как же иначе.

Кто начал? Rackspace. Rackspace, НАСА начали работать, на сегодня Rackspace остаётся одним из самых таких больших разработчиков, но появились уже и другие. На сегодня OpenStack — это уже даже не программа. Это фреймворк, в этот фреймворк входит куча разработчиков, входит куча проектов, есть там стандарты, которые кто-то реализует. Вот тут в скобочках я написал в порядке убывания количества обновлений, которые добавляются в общий набор состава. То есть на сегодня HP вышел на первое место причём с довольно большим отрывом. Дальше RedHat, IBM, Huawei, VMware, Suse, Intel. Кстати, VMware тоже его активно использует и, в том числе, и разрабатывает свою облачную структуру.

Что позволяет сам OpenStack? Несколько пунктов, не будем сильно на них останавливаться. Первое, создание виртуальных машин. Создание, работа, обновление, удаление, то есть весь жизненный цикл. На сегодня поддерживается, если это HP, либо KVM либо ESXi. То есть либо RedHat Suse, либо это VMware.
Отдельно — доступ к блочным устройствам. HP либо использует 3PAR, либо предоставляет пролианты с большим количеством дисков. Есть два варианта, и одни вариант, и другой вариант доступен. Дальше, использование контейнеров, где объекты создаются, например, создать операционную систему, создать приложение, включить его, выключить, определить ресурсы. Вот этот самый свифт, называется, контейнер для управления.
Полный доступ к сети. Включаются как коммутаторы, так и маршрутизаторы, и фаерволы, и балансировка нагрузки.

Что еще? Система аутентификации, отдельно. Отдельно идет система создания уже готовых образов виртуальных машин. Дашборд для управления, опять же, это отдельная инфраструктура, её может и не быть. Управление образами — это резервное копирование, хранение и так далее. Сервисы взаимодействия с аппаратной инфраструктурой также.
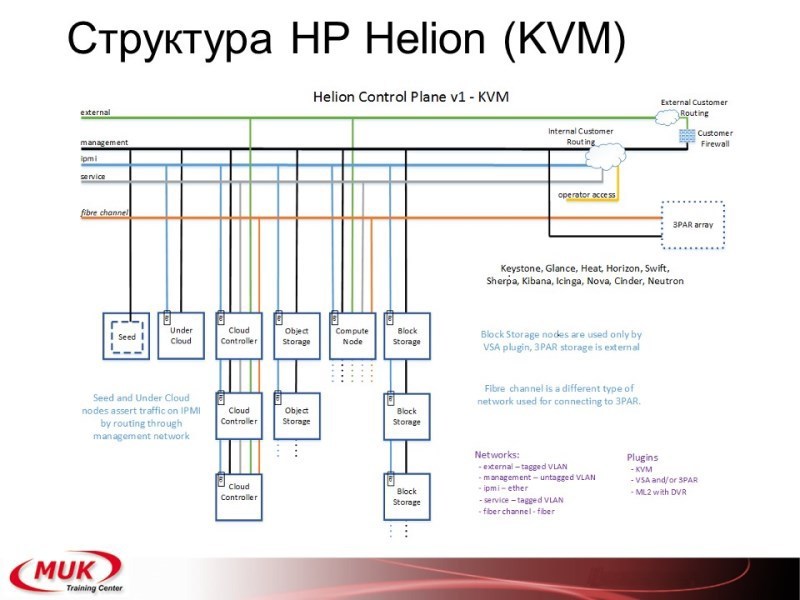
Зачем я выписывал эти самые блоки? Потому что если вы возьмете большую схему разворачивания Helion-а, то тут сразу будет указано: «Машина такая-то, служба, свифт, и т.д.». То есть если вы берете схему, вы по этим блокам сразу же определяете, а что у вас будет на конкретной машине.
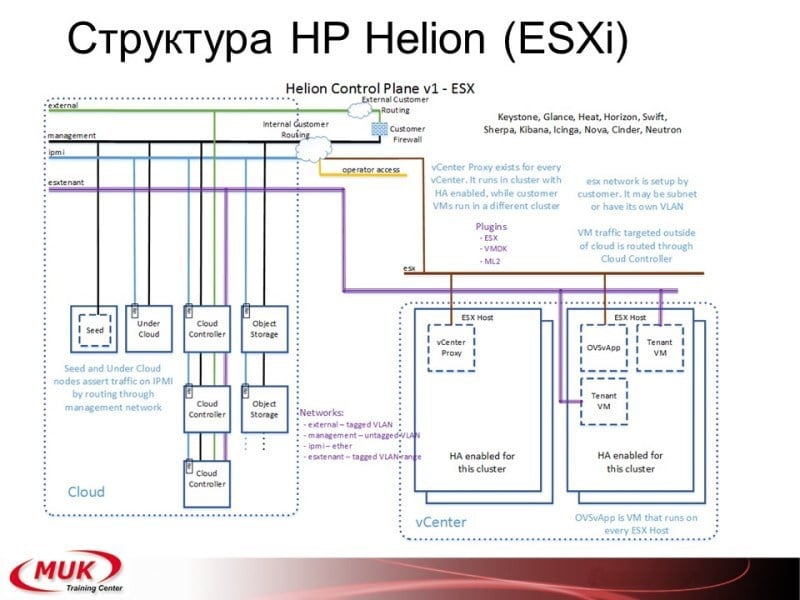
Есть разворачивание под KVM, есть разворачивание под ESXi, стандартного варианта и одной, и другой не нашёл. Возможно, оно где-то то есть в поддержке, но так они рекомендуют либо одно, либо другое.

Вот как бы что включается в сам HP Helion, вот наши блоки, которые присутствуют на отдельных компонентах.
HP Helion Rack

Ну и так же уже готовая аппаратная поставка, которая называется HP Helion Rack. Она в себя включает сеть, флекс, сам шкаф; указывается поддержка, опять же софт, вычислительные узлы, от четырёх серверов, системы хранения данных DL, но можно использовать 3PAR, и один блок для управления. Это готовое решение, которое продаётся как уже целостный комплекс. Правда, никто не мешает вам собрать его самостоятельно.
Вопрос из зала: «Четыре сервера для вычислений и пять серверов для управления?»
Это начинается от четырех…
«Я думал, пятый сервер для управления»
Когда нужна виртуализация ИТ-инфраструктуры?
Система в том, что облако имеет смысл тогда, когда машин много. Вы за вот эту гибкость и изоляцию аппаратной платформы от пользователя, вы платите управлением. Если у вас десять машин, честно говоря, вам смысле делать облако нет. А вот если вы начинаете расти, вот тогда этих пять машин, они уходят уже в нормальный процент.
Скажем так, что если у вас облако небольшое, вы можете использовать просто OpenStack, тогда этих пять машин включаются как виртуалки, они замечательно работают и в lxc, и в докере, кстати, вот у нас работает именно так. То есть у нас строится по lxc, и мы используем уже такой режим работ, но, если вы берёте готовую систему и эта система не десять серверов, то есть смысл взять готовое решение. Это будет быстрее и дешевле. Ну, скажем так, проверено.
На самом деле да, если у вас есть хорошая компания разработчиков, вы можете взять тот же OpenStack и сделать всё это гораздо дешевле, и заплатить разработчикам за работу. Ну а можно не нанимать разработчиков и сразу использовать саппорт. Практика показывает, что если разработчиков нет, это будет дешевле. А быстрее — 100%. Вот.
Видеозапись доклада:
https://www.youtube.com/watch?feature=player_embedded&v=K3v-oLICstg





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.