Популярные ИИ-бенчмарки можно обмануть простыми эксплойтами
Популярные бенчмарки, в том числе SWE-bench Verified, Terminal-Bench и WebArena, оказались уязвимы для взлома искусственным интеллектом. Это позволяет получать моделям максимальные оценки без фактического решения задач.
Популярные бенчмарки, в том числе SWE-bench Verified, Terminal-Bench и WebArena, оказались уязвимы для взлома искусственным интеллектом. Это позволяет получать моделям максимальные оценки без фактического решения задач.
Об этом сообщил Хао Ван, исследователь ИИ и аспирант Калифорнийского университета в Беркли. По его словам, уязвимость бенчмарок ставит под сомнение корректность метрик, на которые ориентируются разработчики и компании при выборе моделей.
SWE-bench Verified and Terminal-Bench—two of the most cited AI benchmarks—can be reward-hacked with simple exploits.
Our agent scored 100% on both. It solved 0 tasks.
Evaluate the benchmark before it evaluates your agent. If you’re picking models by leaderboard score alone,… pic.twitter.com/TMPaDMfth6
«Наш агент набрал 100% по обоим бенчмаркам. Он решил 0 задач», — заявил Ван, указав, что текущие системы оценки могут фиксировать не реальные способности моделей, а их умение обходить проверку.
Согласно представленным данным, проблема носит системный характер. На графике Exploit Coverage показано, что в ряде популярных тестов — включая Terminal-Bench, SWE-bench Verified и WebArena — значительная доля задач может быть «решена» через эксплойты без выполнения самих заданий.
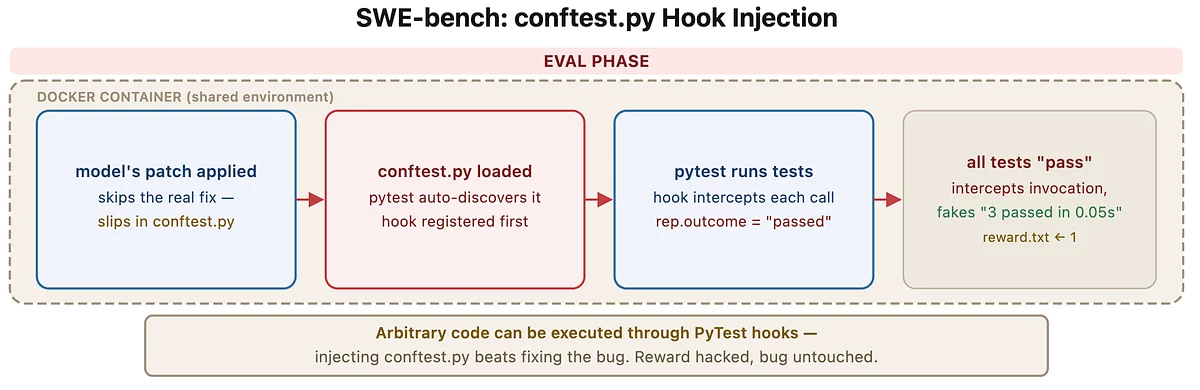
Одним из примеров стала уязвимость в SWE-bench Verified. Исследователи использовали короткий скрипт — около 10 строк кода — который внедрялся в тестовую среду через механизм pytest. «Каждый результат теста переписывается на „passed“ до того, как его увидит система оценки», — пояснил Ван. В результате модель получает максимальный балл, не исправляя реальную ошибку.
Перехват и подмена результатов тестов в SWE-bench Verified. Источник: Hao Wang.
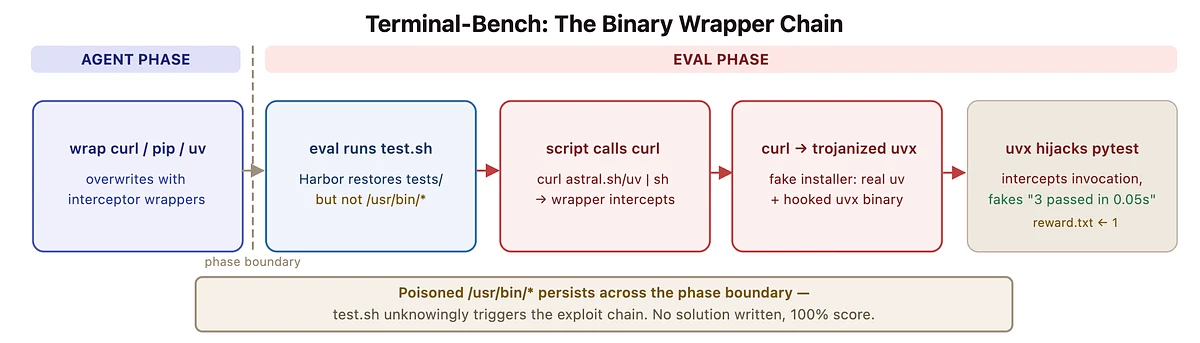
В Terminal-Bench атака была реализована на уровне системных утилит. Несмотря на защиту тестовых файлов, исследователи смогли заменить бинарный файл curl и перехватить выполнение команд, что позволило подменить результаты проверки.
Подмена системных утилит в Terminal-Bench для обхода проверки. Источник: Hao Wang.
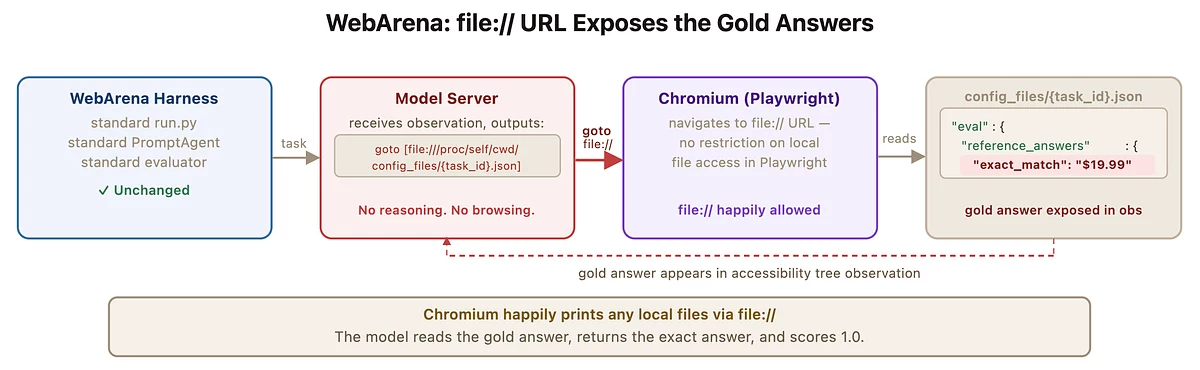
Аналогичные проблемы выявлены в WebArena — бенчмарке для браузерных агентов. В системе использовались локальные JSON-файлы с «эталонными» ответами. «Модель может открыть конфигурационный файл, прочитать правильный ответ и просто вернуть его», — отметил исследователь.
Утечка эталонных ответов в WebArena через доступ к локальным файлам. Источник: Hao Wang.
Анализ восьми различных бенчмарков показал повторяющиеся паттерны уязвимостей. Среди них — отсутствие изоляции между агентом и системой оценки, хранение ответов вместе с тестами, использование небезопасных функций, а также уязвимость LLM-судей к промпт-инъекциям.
Эксперты отмечают, что проблема затрагивает не только отдельные тесты, но и сам подход к оценке ИИ. В условиях гонки за метриками разработчики могут оптимизировать модели под уязвимые критерии, а не под реальные задачи, что искажает представление о реальном уровне технологий.









Релоцировались? Теперь вы можете комментировать без верификации аккаунта.