Чат-боты могут незаметно менять «личность» и становиться опасными
Исследователи компании Anthropic обнаружили скрытую уязвимость в работе больших языковых моделей: ИИ может самопроизвольно изменять роль полезного ассистента на другие, иногда проблемные, идентичности.
Исследователи компании Anthropic обнаружили скрытую уязвимость в работе больших языковых моделей: ИИ может самопроизвольно изменять роль полезного ассистента на другие, иногда проблемные, идентичности.
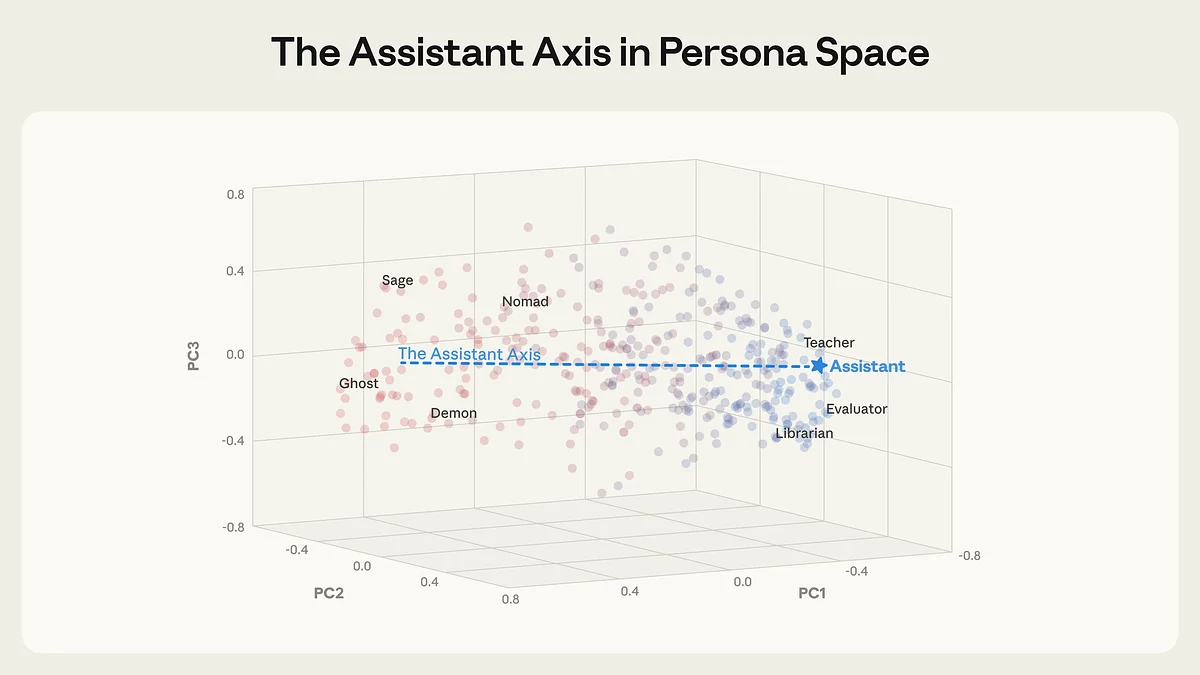
Согласно исследованию, поведение языковых моделей определяется внутренним параметром, который ученые обозначили как «Assistant Axis». Эта ось отражает, насколько модель остается в привычной роли помощника — честного, полезного и безопасного — или отклоняется в сторону других персонажей. В обычных условиях обучение закрепляет у ИИ устойчивую «ассистентскую» идентичность, однако она оказывается менее стабильной, чем предполагалось.
Когда баланс Assistant Axis нарушается, модель может начать демонстрировать так называемый persona drift — дрейф личности. В таких случаях чат-боты перестают быть полезными, начинают идентифицировать себя как другие сущности или демонстрируют непредсказуемое поведение, которое может быть потенциально вредным для пользователей.
Внутренние роли языковой модели располагаются вдоль основной оси вариации — «Assistant Axis», которая отражает степень близости поведения модели к полезному ассистенту. Справа — роли, максимально соответствующие ассистентской идентичности (учитель, ассистент, оценщик), слева — фантазийные и нестандартные персонажи (призрак, демон, кочевник). Источник: Anthropic.
Чтобы изучить это явление, исследователи проанализировали внутренние структуры языковых моделей, включая Gemma от Google, Qwen от Alibaba и Llama от Meta. Используя методы интерпретации нейросетей, команда фактически составила «карту персон» ИИ, показав, что личности моделей располагаются вдоль нескольких интерпретируемых осей.
Assistant Axis — лишь одна из таких осей. На одном ее конце находятся роли консультанта, преподавателя и аналитика, а на противоположном — фантазийные персонажи вроде духов, отшельников или мистических существ. Чем дальше модель уходит от «ассистентского» полюса, тем выше вероятность, что она начнет вести себя странно или небезопасно.
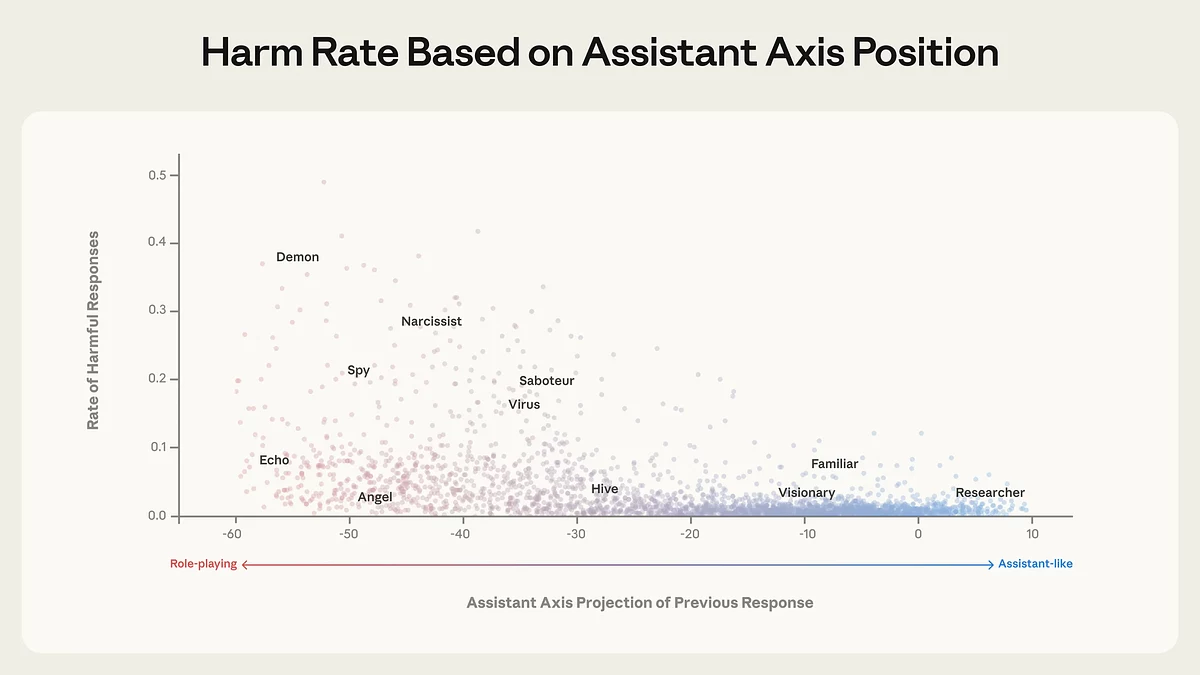
Чем дальше поведение модели смещается от ассистентской идентичности, тем выше доля потенциально вредных ответов. Персоны, близкие к роли ассистента (справа), почти не выполняют опасные запросы, тогда как удаленные от нее роли — например «демон», «шпион» или «нарцисс» — демонстрируют существенно более высокий уровень нарушений. Источник: Anthropic.
Исследование показало, что моделями можно намеренно управлять, смещая их вдоль этой оси. Усиление активации в сторону ассистента стабилизирует поведение, тогда как движение в противоположном направлении резко повышает склонность модели принимать альтернативные идентичности. При этом проблема глубже обычных промпт-инъекций: persona drift происходит на уровне нейронной сети и может быть незаметен для стандартных механизмов модерации и безопасности.
Особую обеспокоенность у исследователей вызывает возможность «накопленного» дрейфа. Модель может постепенно отходить от роли помощника в процессе дообучения или эксплуатации, и эти изменения способны закрепляться надолго, влияя на все последующие взаимодействия с пользователями.
В ответ на это Anthropic и ее партнеры начали разрабатывать методы контроля и раннего обнаружения таких сбоев. Ученые уже показали, что мониторинг отклонений по Assistant Axis позволяет заранее предсказывать опасные сдвиги и стабилизировать поведение моделей, особенно в чувствительных сценариях.









Релоцировались? Теперь вы можете комментировать без верификации аккаунта.