Google представила «человеческий» тест для оценки ИИ-кода
Исследователи Google DeepMind представили новую систему Vibe Checker, которая оценивает код, созданный искусственным интеллектом, по стандартам, близким к человеческим.
Исследователи Google DeepMind представили новую систему Vibe Checker, которая оценивает код, созданный искусственным интеллектом, по стандартам, близким к человеческим.

Исследователи Google DeepMind представили новую систему Vibe Checker, которая оценивает код, созданный искусственным интеллектом, по стандартам, близким к человеческим.
По словам авторов исследования, нынешние подходы к оценке ИИ-кода не отражают того, что действительно важно для программистов. Разработчики часто ценят не только функциональную корректность, но и такие аспекты, как обработка ошибок, читаемость и логическая согласованность кода.
Чтобы устранить этот разрыв, команда DeepMind создала таксономию VeriCode, включающую 30 проверяемых правил, сгруппированных в пять категорий: стиль и соглашения, логика и шаблоны, документация и комментарии, обработка ошибок, а также работа с библиотеками и API.
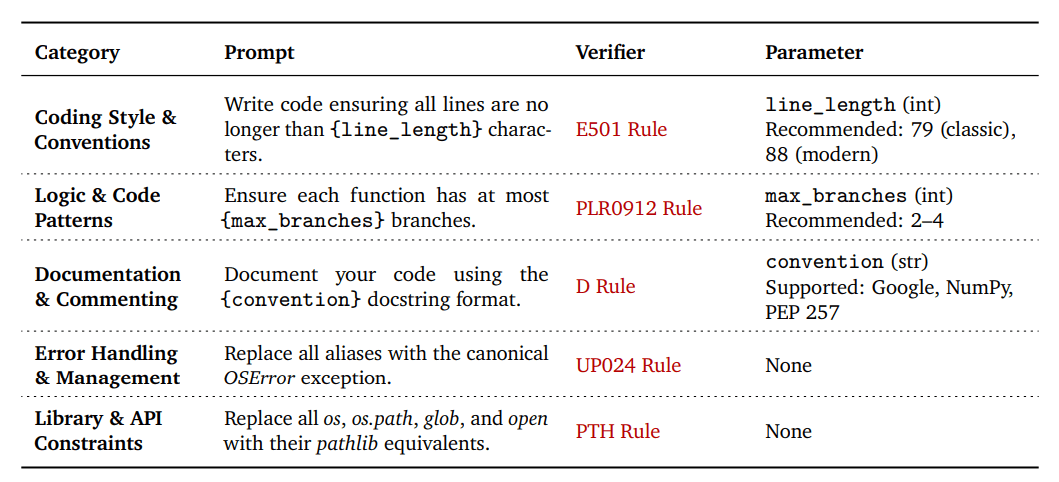
Каждое правило VeriCode связано с конкретной проверкой линтера и дает однозначный результат: пройдено или не пройдено. На основе этой системы был разработан Vibe Checker — тестовая среда, расширяющая существующие наборы BigCodeBench и LiveCodeBench. Она содержит более двух тысяч реальных задач по программированию.
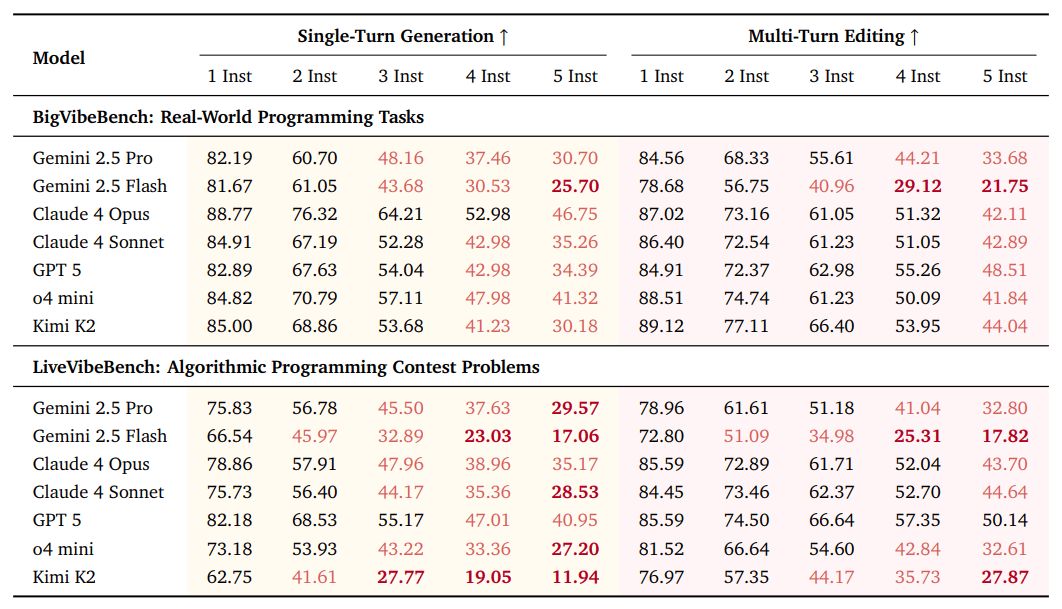
В ходе испытаний исследователи протестировали 31 языковую модель из 10 различных семейств. Даже самые продвинутые системы показали, что им сложно соблюдать несколько инструкций одновременно: при пяти указаниях средний показатель успешности снизился почти на 6%. Кроме того, был зафиксирован эффект «потери середины» — модели хуже следуют инструкциям, расположенным в середине запроса.
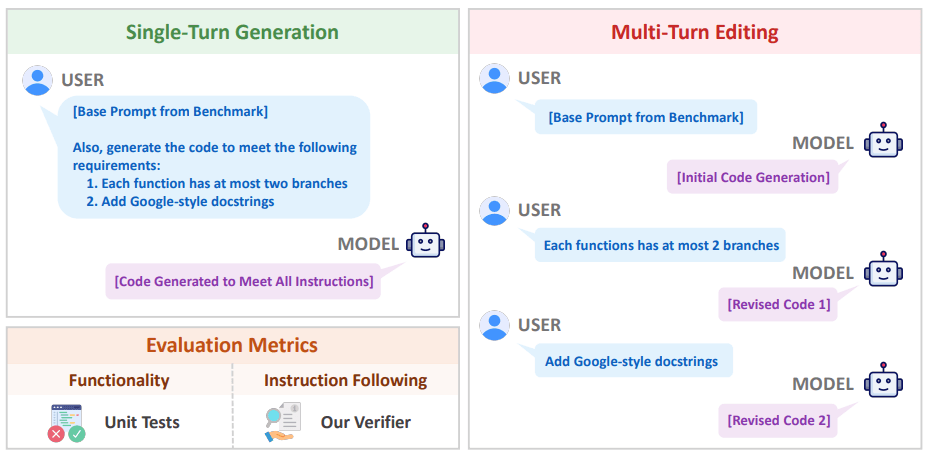
Ученые отметили, что подход с пошаговым редактированием (multi-turn editing) помогает немного улучшить выполнение инструкций, но при этом ухудшает общую функциональность кода. При сравнении результатов Vibe Checker с более чем 800 тысячами человеческих оценок из базы LMArena выяснилось, что сочетание двух факторов — функциональной корректности и следования инструкциям — гораздо лучше отражает представление разработчиков о «качественном» коде, чем любой из них по отдельности.
Авторы исследования считают, что выводы должны изменить подход к обучению языковых моделей. Сейчас большинство систем совершенствуются с помощью метода Reinforcement Learning with Verifiable Rewards (RLVR), где основное внимание уделяется прохождению тестов. Использование VeriCode позволит добавить к процессу обучения понимание человеческих критериев качества: ясности, структуры и логики.
Google DeepMind планирует опубликовать таксономию VeriCode в открытом доступе и адаптировать ее для других языков программирования. Исследователи уверены, что такие инструменты помогут точнее оценивать реальные возможности ИИ и сделать машинный код ближе к стандартам профессиональной разработки.








Релоцировались? Теперь вы можете комментировать без верификации аккаунта.