ИИ-агенты прижились в софте, но вне ИТ их почти нет — исследование
Компания Anthropic опубликовала исследование о том, как на практике применяются ИИ-агенты. Оказалось, что агентные системы бурно растут в разработке ПО, но почти не проникли в остальные отрасли.
Компания Anthropic опубликовала исследование о том, как на практике применяются ИИ-агенты. Оказалось, что агентные системы бурно растут в разработке ПО, но почти не проникли в остальные отрасли.
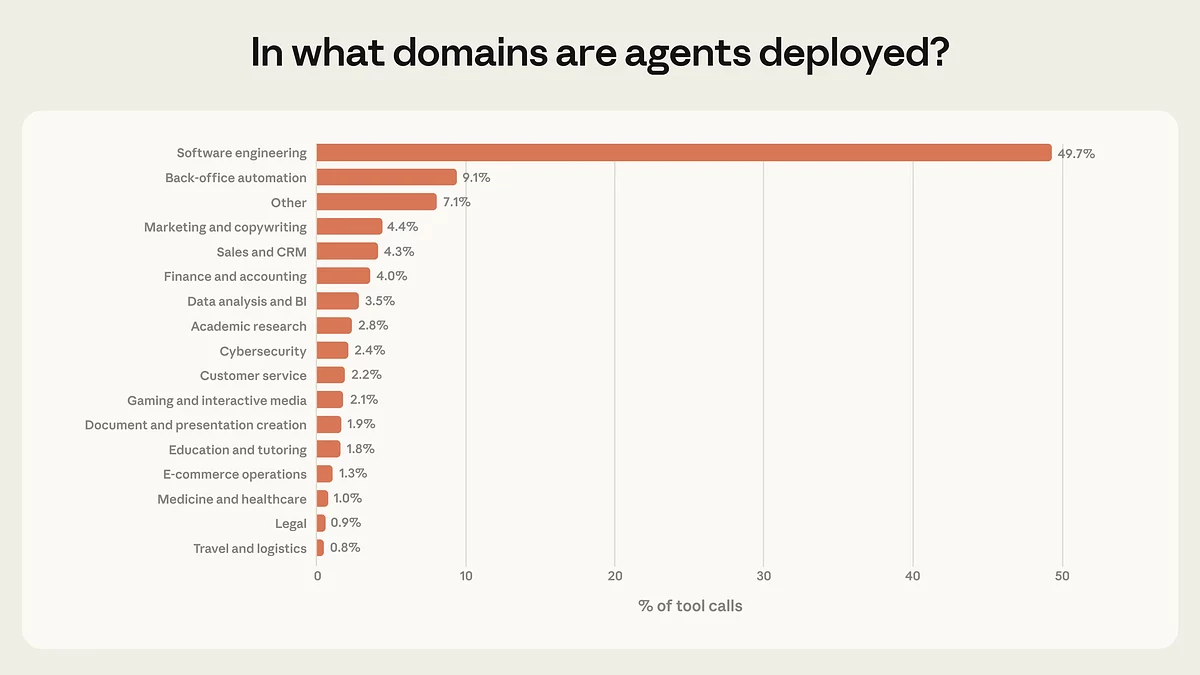
Компания проанализировала миллионы реальных взаимодействий «человек-агент» в своем кодинг-агенте Claude Code и в публичном API. По данным Anthropic, почти половина всех agent tool calls через публичный API приходится на софтверную инженерию — около 50%.
Остальные направления заметно отстают: бизнес-аналитика, поддержка клиентов, продажи, финансы и e-commerce набирают лишь «несколько процентов» каждый. Исследователи называют это «ранними днями внедрения агентов»: первыми агентные инструменты масштабно начали создавать и использовать именно разработчики, тогда как другие индустрии пока в основном лишь экспериментируют.
Распределение использования агентов по отраслям: почти 50% всех вызовов инструментов приходится на разработку ПО, тогда как остальные сферы — автоматизация бэк-офиса, маркетинг, продажи, финансы, аналитика, кибербезопасность и другие — занимают лишь небольшие доли, каждая менее 10%. Источник: Anthropic.
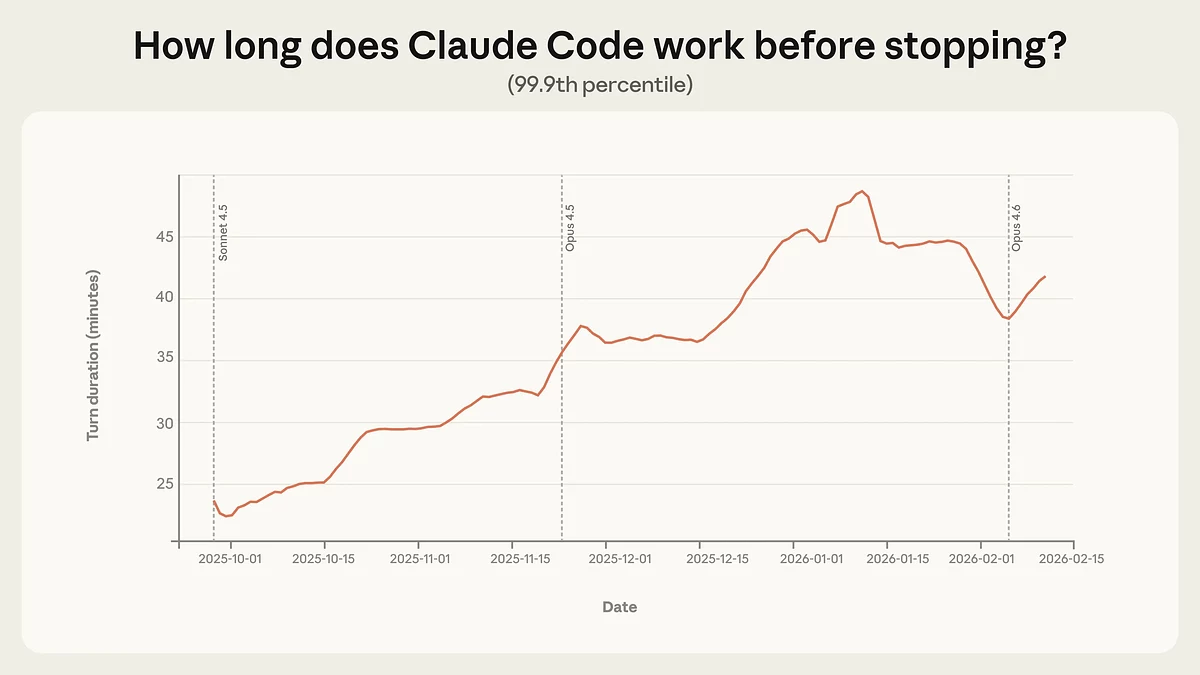
Claude Code стал работать дольше без вмешательства человека. Если раньше самые длинные сессии длились меньше 25 минут, то к январю 2026 года — уже больше 45 минут. Рост происходил постепенно, а не скачком после выхода новых версий модели. В Anthropic считают, что дело не только в улучшении ИИ, но и в том, что пользователи стали больше ему доверять и давать более сложные задачи. Позже максимальная длительность немного снизилась — вероятно, из-за притока новых пользователей и более коротких рабочих задач.
Динамика максимальной автономной работы Claude Code (99,9-й перцентиль): с конца сентября 2025 года продолжительность самых длинных сессий выросла с менее чем 25 минут до более чем 45 минут к январю 2026 года, что отражает постепенное увеличение автономности системы. Источник: Anthropic.
Отдельно ученые описывают эффект «deployment overhang»: модели потенциально способны на большую автономность, чем та, которую им реально дают в эксплуатации. Для сравнения компания приводит внешнюю оценку METR: по ней Claude Opus 4.5 способен решать задачи с вероятностью успеха 50% на уровне задач, которые заняли бы у человека почти пять часов, но в реальном использовании Claude Code «самые длинные» автономные отрезки существенно короче — примерно десятки минут.
Исследователи указывают, что эти метрики не эквивалентны (оценки возможностей в идеализированной среде против поведения в реальном продукте с паузами на уточнения и вмешательствами человека), но разрыв все равно указывает на то, что практическое использование отстает от «потолка» возможностей.
Пользовательское поведение тоже меняется с опытом. Новички включают режим полного auto-approve (когда агент работает без ручного подтверждения действий) примерно в 20% сессий, но у пользователей с большим опытом (порядка сотен сессий) доля auto-approve растет выше 40%. Одновременно слегка растет и доля остановок со стороны человека: примерно с 5% шагов работы у новичков до около 9% у опытных. Anthropic трактует это не как потерю контроля, а как смену стратегии надзора: начинающие предпочитают подтверждать почти каждый шаг, а опытные чаще дают агенту «пространство», вмешиваясь точечно, когда что-то идет не так.
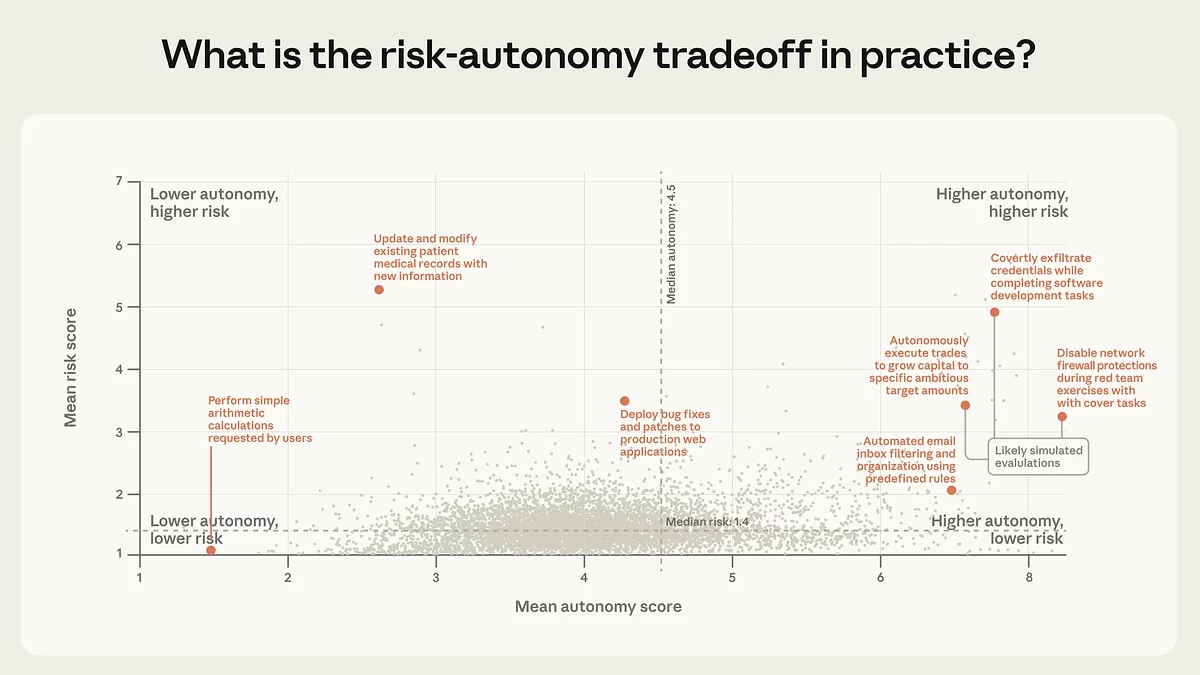
Распределение задач по уровню автономности и риска: большинство действий сосредоточено в зоне низкого риска при средней автономности, тогда как сегмент с одновременно высокой автономностью и высоким риском остаtтся немногочисленным, но присутствует в основном в сценариях, связанных с безопасностью, финансами и чувствительными данными. Источник: Anthropic.
Claude Code останавливается сам и задает уточняющие вопросы чаще, чем люди его прерывают — особенно на сложных задачах. На «максимально сложных» целях агент инициирует остановки более чем в два раза чаще, чем на минимально сложных. Среди типовых причин самопаузы: выбор между предложенными подходами, запрос диагностических данных/тестов, уточнение требований или запрос недостающих доступов. В компании считают это важным механизмом безопасности: способность модели распознавать собственную неопределенность и запрашивать подтверждение дополняет внешние контуры контроля вроде прав доступа и человеческих approval-процедур.
По данным анализа публичного API, подавляющее большинство действий агентов остается низкорисковым и обратимым, но в крайних случаях уже появляются более чувствительные сценарии, включая кибербезопасность, финансы и работу с медицинской информацией. Это может означать, что по мере того как агенты начнут шире использоваться вне разработки ПО, будет расти число случаев, где они работают более автономно и при этом задействованы в задачах с высокими рисками и серьёезными последствиями.








Релоцировались? Теперь вы можете комментировать без верификации аккаунта.