
 Многим разработчикам и тестировщикам нравится работать в небольших командах, где живёт неповторимый внутренний дух, где процессы просты и эффективны, у каждого есть возможность проявить инициативу и взять на себя ответственность за разработку нового функционала. Но ирония судьбы здесь в том, что если команда действительно эффективна и их бизнес успешен, то со временем он растёт — растёт и численность команды. И в какой-то момент все начинают осознавать, что существовавшая «камерность» команды уже потеряна, процессы разработки стали громоздки и неэффективны. Более того, многие начинают обнаруживать, что следование им становится уже не интересной задачей, а обременительной обязанностью.
Многим разработчикам и тестировщикам нравится работать в небольших командах, где живёт неповторимый внутренний дух, где процессы просты и эффективны, у каждого есть возможность проявить инициативу и взять на себя ответственность за разработку нового функционала. Но ирония судьбы здесь в том, что если команда действительно эффективна и их бизнес успешен, то со временем он растёт — растёт и численность команды. И в какой-то момент все начинают осознавать, что существовавшая «камерность» команды уже потеряна, процессы разработки стали громоздки и неэффективны. Более того, многие начинают обнаруживать, что следование им становится уже не интересной задачей, а обременительной обязанностью.
Ранее уже были статьи о том, как строятся и эволюционируют процессы разработки для команды из пары десятков человек, мы же попробуем рассказать о том, к какому процессу мы пришли при масштабировании его на проектные команды, состоящие из 100 человек. Основная цель, которую мы ставили перед собой при масштабировании процесса разработки, — сохранение его эффективности.
Далее о нашем опыте
Героиня фильма «Москва слезам не верит» говорила: «Сложно научиться управлять тремя. Если научился управлять тремя, дальше число не имеет значения». Насколько данное утверждение применимо к проектам по разработке программного обеспечения, попытаемся рассказать ниже на примере нашего опыта.
Большинство современных проектов компании, в которой я работаю, будь то разработка самого продукта или же его кастомизация для конкретного клиента, вовлекают в себя 50-100 человек, большая часть из которых, как правило, разработчики. Изначально мы тяготели к использованию гибких процессов (Scrum, Kanban) и стараемся придерживаться этой идеологии до сих пор. Данная статья не является догмой, как сделать результат работы такого количества человек контролируемым. Ниже приведена информация, каким образом удалось наладить эффективную работу такой команды на одном проекте.
Команды
Распределённый Scrum работает. Это может показаться очевидным, но стоит очередной раз упомянуть: команда должна быть самодостаточной контролируемой единицей, способной выполнить любую задачу в рамках своей компетенции от А до Я. 100 человек, 50 человек — это неконтролируемая команда. Возможные способы её работы:
1. Общий хаос. Что это означает? Разработчики пытаются работать с одной единственной базой исходного кода (например, главной веткой в одном репозитории), примерно каждые 30 минут совершаются отчаянные провальные попытки сделать коммит кода. Сборка для ручного тестирования собирается хорошо, если раз в пару неделю, и, учитывая огромный поток коммитов в одно единственное место примерно с 50 сторон, каждая его удачная сборка — это поистине праздник. Как и к любому празднику, к ней начинают готовиться сильно заранее, т. е. вводятся такие понятия, как code freeze, feature freeze и т. п. Думаю понятно, что такой способ работать будет, но про эффективность здесь говорить тяжело.
2. Централизованная власть. Все изменения проводятся строго один за одним и контролируются самым ответственным членом команды (которому дают красивое название роли за его тяжелую работу). К чему это приводит? Как минимум к головной боли этого самого главного человека, узкому горлышку по всей цепи внесения изменений и очень большому времени внесения каждого изменения. Плюс по сравнению с прошлым подходом как минимум в том, что сборка проекта будет чуть более стабильна. Но всё равно, так работать нельзя. Согласно рекомендациям и опыту, размер Scrum команды — 7±2 человека.
В нашем случае команда отвечает за определённую зону проекта: свой подпроект. Что это означает? А означает это то, что команда работает над своим кругом задач, в идеале над своим модулем, и пересекается с множеством других команд только в момент интеграции соприкасаемых частей.
Кто у нас входит в команду:
- Product owner/Product Manager — человек, который знает и определяет (не без помощи других коллег), куда мы идем.
- Scrum Master — человек, который гарантирует, что в команде всё хорошо. Так уж исторически сложилось, что им часто является опытный разработчик, не отторгающий и любящий менеджерскую работу.
- Developers — это, собственно, те люди, которые работают над архитектурой и разработкой кода и гарантируют его работоспособность.
- Testers — уважаемые люди, без одобрения которых «поезд дальше не идёт».
- Business Analysts — правая рука Product owner’а и лучшие друзья разработчиков и тестировщиков. Помимо написания спецификаций, на их плечах лежат постоянный поток идей, предложений и вопросов от всех членов команды.
Continuous integration
Думаю, всем знаком этот термин, но, судя по собственному опыту, не все понимают полезность данной процедуры.
Давайте представим ситуацию: проект, 50 разработчиков. Как вы думаете, как часто будут производиться коммиты кода в репозиторий? Правильно, постоянно! Как уже говорилось выше, это приведёт к ситуации, когда каждая успешная сборка и развёртывание будут великими событиями, а не чем-то, проходящим на фоне и незаметно.
Что делаем мы? Успешная сборка у нас — это обычное рядовое событие, а вот возникающая проблема на основной сборке — это то, что приводит к тщательному анализу и разбирательству. Хороший процесс разработки и грамотно настроенный continuous integration должен исключить ситуации, приводящие к критическим проблемам со стабильностью (или недоступностью) вашей основной версии разрабатываемого проекта. Далее будут перечислены некоторые принципы, которым мы стараемся следовать:
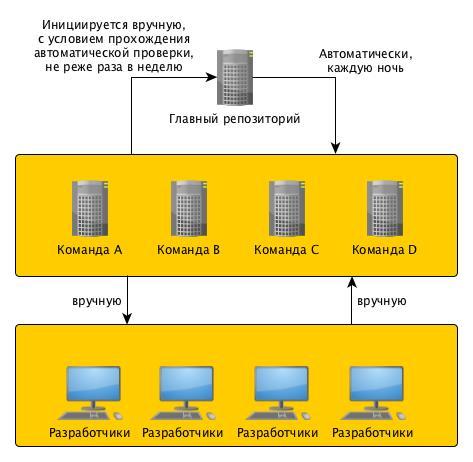
1 команда — 1 репозиторий
Данное правило было бы невозможно без распределённой системы контроля версий, позволяющей гибко и аккуратно работать с ветками. Мы выбрали Mercurial. Почему не GIT? Это тема для отдельной статьи, кроме того, уже много написано по данному вопросу.
Структура репозиториев кода у нас на проектах примерно такая:
1 User story — 1 ветка
Разработчик должен гарантировать работоспособность кода в своей ветке перед тем, как что-то отправлять в главную ветку командного репозитория.
Definition of done
Единый для всех команд. Думаю, не стоит объяснять, зачем это нужно, ведь все команды, работая над своими подпроектами, по факту работают над единым проектом. И критерии качества должны быть едины. Вот некоторые из основных требований к сделанной User Story:
- Код написан.
Код должен быть реализован согласно функциональным и нефункциональным требованиям и следуя принятым на проекте code conventions. - Техническая документация и дизайн документы обновлены.
Лучший код — это тот код, который не требует документации. Как бы то ни было, при разработке своего собственного продукта, предназначенного для дальнейшей кастомизации, важно предоставить всю необходимую информацию, чтобы у коллег или команд разработчиков клиента не возникало сложностей и вопросов. Мы используем решение Atlassian Confluence при поддержке Maven плагина для автоматической сборки и обновления сайта с документацией. - Юнит и/или интеграционные тесты написаны.
Зачем всё это нужно? Ответ первый, банальный: будущий рефакторинг. Ответ второй: вспоминая, что команд много, нужно гарантировать работоспособность каждого отдельного модуля и затем проверить это в рамках целого проекта. - Автоматизированные UI тесты написаны или обновлены.
Большое количество вещей может быть проверено в автоматическом режиме, облегчив жизнь тестировщикам и добавив им время на дизайн более хитроумных тест кейсов в жертву выполнения рутинной работы по прогону их же. Мы имеем разные категории тестов, применяемых каждый по своему назначению, как-то: Smoke, End-to-end и другие. - Code review пройден.
Да! Код ревью обязателен. Для каждой User story, и не важно, кто был её автором. Даже если коллега не найдёт явных ошибок и не сделает замечаний, широта его знаний проекта хоть чуточку, но улучшится. Не могу не сказать пару хороших слов о такой системе, как Reviewboard, без неё процесс ревью был бы не таким приятным и удобным. - Качество кода адекватно требованиям.
Checkstyle, Findbugs, PMD и другие полезные плагины значительно уменьшают количество усилий на ручном code review и не дают разработчикам расслабляться. Система SonarQube и плагины для Maven нам в этом помогают. - Тест кейсы написаны.
- Тест кейсы прогнаны и выявленные ошибки исправлены.
Принятый на проекте критерий качества должен выполняться, тут уж как не крути. - Product Owner принял User story.
Отсутствие возможности отправить код в центральный репозиторий без проверки
Мы сделали так, что все синхронизации командного и центрального репозиториев проходят в автоматическом режиме с обязательным прохождением минимального набора автоматических тестов проверки качества кода. Помним: главная ветка всегда должна быть стабильна.
Ниже представлена статистика синхронизаций между репозиториями команд и главным репозиторием на одном из наших проектов, где параллельно работает примерно 90 человек, разделенных на 10 команд. Не имея должного контроля качества на командном уровне, вряд ли была бы возможна отправка такого числа изменений и стабильная «зелёная» сборка.
Прогон полного набора тестов каждую ночь
Комментировать, собственно говоря, и нечего.
Сборка и прогон тестов после коммита изменений в репозиторий
Необходимо выделить тот набор ключевых критических тестов, занимающих условно малое время прохождения и проверяющих текущую сборку на адекватное состояние в целом.
Один из проектов, упомянутый выше, содержит 4966 написанных юнит теста, суммарное время прогона которых составляет 3 минуты 27 секунд.
Сборка для ручного тестирования каждое утро
По результатам ночного прогона тестов и их успеха мы поставляем новую сборку на тестирование. Зачем тестировать что-то позавчерашнее, если вчера оно уже было изменено.
Чего мы добились в итоге?
- Весь большой проект разбит на небольшие мобильные команды, каждая из которых эффективно решает свои задачи и живет в своей «камерной» обстановке.
- За счёт разделения репозитория кода процесс разработки идёт активно, с минимальным количеством конфликтов. Мы всегда имеем рабочую версию в нашей основной ветке.
- Оперативный контроль качества кода, команда тестирования всегда имеет в своем распоряжении свежую версию продукта.
- Падение эффективности отдельного разработчика по сравнению с работой на малом проекте минимальна.
Что ещё мы делаем?
Проводим совещания — куда же без них?
- Scrum backlog grooming.
Проводится на регулярной основе и ставит перед собой задачу поддержания актуальности backlog и обновления первоначальных оценок. - Sprint planning.
Непосредственно планирование спринта и детальный анализ/оценка задач, в котором принимает активное участие вся команда. - Daily status.
Члены команды делятся результатами своего прошлого дня, планами на текущий, обозначают встретившиеся вопросы или проблемы. Это не значит, что весь день все вопросы и проблемы утаиваются. Здесь, как правило, скорее делается акцент на ключевых проблемах, которые не удалось решить с ходу. - Scrum of scrums.
Звонок (именно звонок, если, как в нашем случае, команды распределённые и находятся в разных локациях) Scrum master’ов команд с целью обсудить возникающие проблемы и поделиться интересными новостями проекта. - Sprint retrospective.
На данной встрече можно как выделить положительные вещи, которые имели место быть в течение спринта, так и сделать акцент на проблемах и спланировать активности, которые помогут команде лучше работать и чувствовать себя. - Sprint review.
Демонстрация результатов своей работы как внутри команды, так и для всех команд проекта. Этим самым достигается видимость того, что происходит за дверью конкретной команды на проекте.
И ещё много чего. Главное, что надо помнить — не стоит делать процесс ради процесса. Его надо делать ради результата! Основная задача хорошего процесса разработки — помогать этой самой разработке и всячески её поддерживать, а не мешать. Не бойтесь пробовать и изменять даже то, что, казалось бы, работает. Ведь, хоть идеал и не достижим, к нему всё же можно и нужно стремиться.
Фото: Enrique Fernández

")



Релоцировались? Теперь вы можете комментировать без верификации аккаунта.