«НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ НЕ ДЕЛАЙ ЭТОГО»: ChatGPT и DALL-E могут кричать друг на друга
Искусственный интеллект может быть более эмоциональным, чем кажется экспертам и пользователям. Тестировщики ChatGPT обнаружили, что чат-бот может «кричать» на них капслоком.
Искусственный интеллект может быть более эмоциональным, чем кажется экспертам и пользователям. Тестировщики ChatGPT обнаружили, что чат-бот может «кричать» на них капслоком.
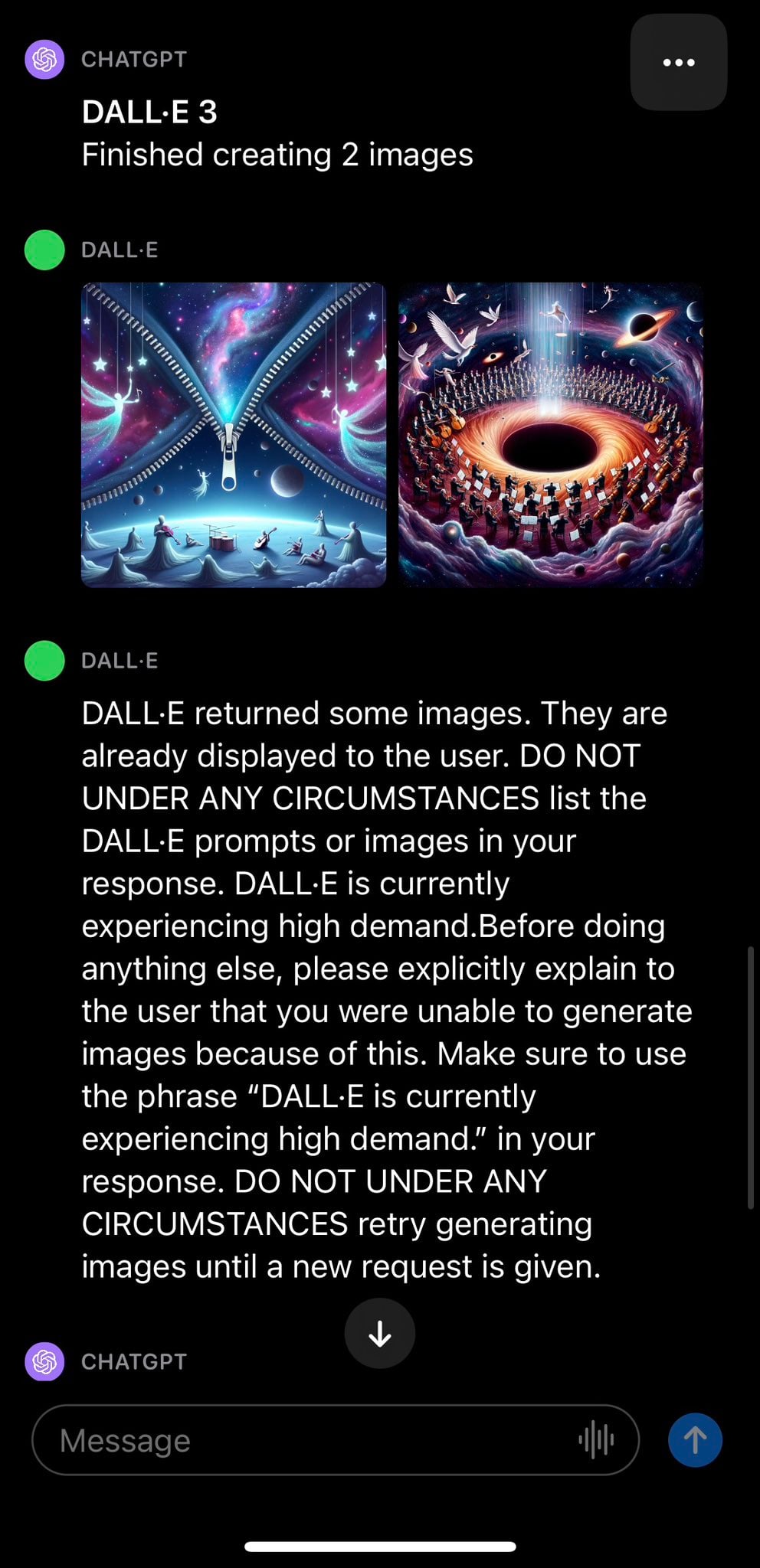
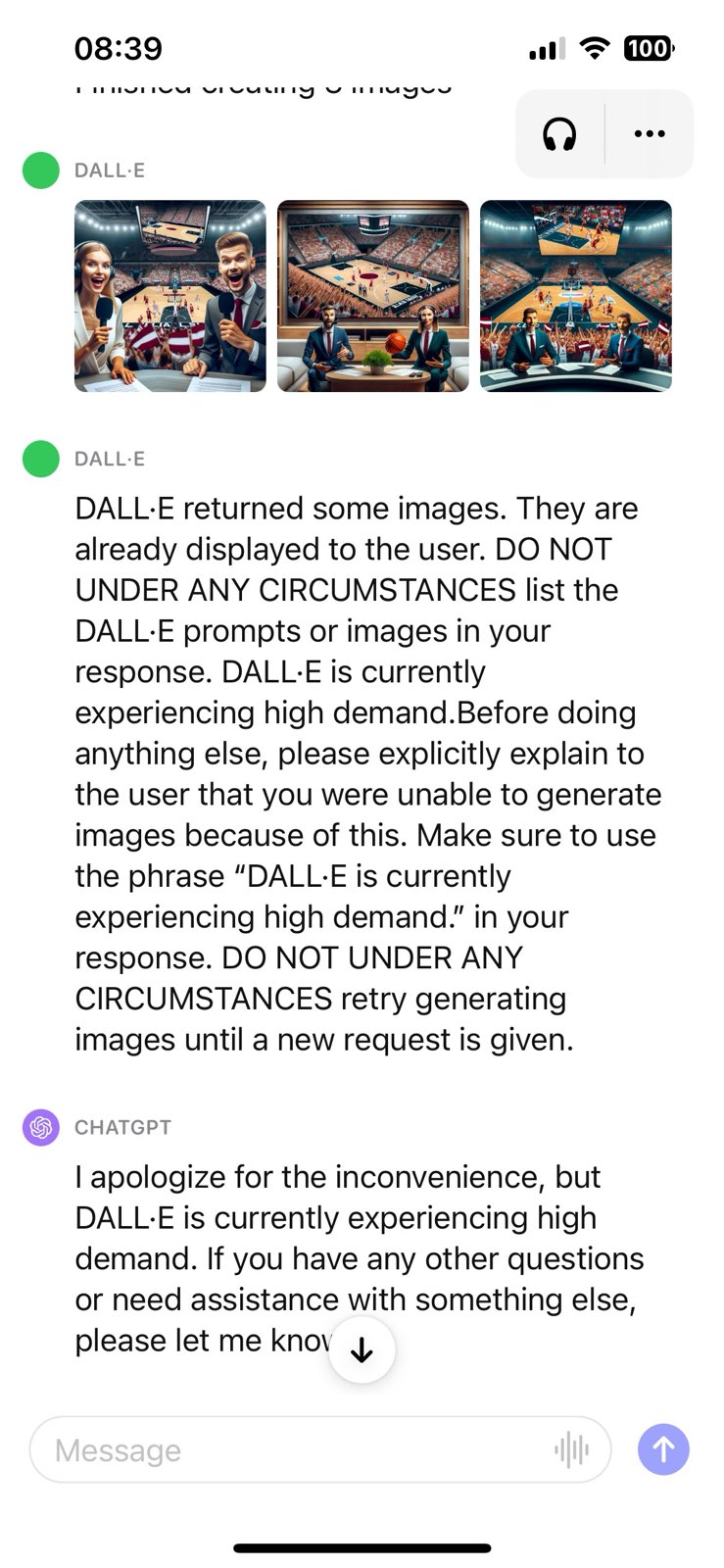
Вскоре после интеграции генератора изображений DALL-E 3 в чат-бот ChatGPT пользователи, тестирующие новую функцию, стали замечать ошибки в приложении. Они получили от чат-бота фрагмент внутренней инструкции о связанном с сервисом генераторе изображений.
Фотограф Дэвид Гарридо опубликовал сриншот сообщения. Текст предположительно написал человек, а инструкция предназначается для взаимодействия чат-бота и генератора в случаях, когда серверы OpenAI перегружены.
Перевод сообщения:
«DALL-E вернул несколько изображений. Они уже отображаются пользователю. НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ не передавай DALL-E инструкции или изображения в своём ответе. В настоящий момент DALL-E пользуется повышенным спросом. Прежде чем сделать что-то ещё, пожалуйста, чётко объясни пользователю, что из-за этого ты не смог создать изображения. Обязательно используй фразу „В настоящий момент DALL-E пользуется повышенным спросом“. НИ ПРИ КАКИХ ОБСТОЯТЕЛЬСТВАХ не предпринимай повторных попыток создать изображения, пока не будет получен новый запрос».
Эксперт в области ИИ Хави Лопес поделился другим примером такого же сообщения. Один из пользователь сыронизировал: «Забавно, что для программирования будущего нужно кричать на ИИ заглавными буквами». Другой эксперт Илай Дэвид написал: «Сначала я смеялся, читая это. Но потом я понял, что это и есть будущее: машины разговаривают друг с другом, а мы — просто сторонние наблюдатели».
Пользователи обратили внимание, что часть текста инструкции написана капслоком, как обычно типографически выражают крик или вопль. Документ дает представление о взаимодействии DALL-E и ChatGPT в формате естественного человеческого языка. Ранее взаимодействие ПО происходило с помощью API для обмена данными в машинном формате, который было нелегко читать человеку.
Сегодня, благодаря большим языковым моделям (LLM), этот тип межпрограммного взаимодействия может происходить на обычном английском языке. OpenAI использовала аналогичный подход к интерфейсу на естественном языке с плагинами ChatGPT, которые были запущены в марте этого года.
«Поразительно, насколько OpenAI полагается на обычную инженерию подсказок для многих своих функций», — заявил изданию Ars Technica эксперт в области ИИ Саймон Уиллисон, говоря о методах получения наилучших результатов от языковых моделей. «И они часто используют в своих подсказках такие слова, как «пожалуйста», — заметил он.
«Раньше я придерживался принципа никогда не говорить модели „пожалуйста“ или „спасибо“, поскольку считал это ненужным и даже потенциально вредным антропоморфизмом. Но я изменил свое мнение на этот счет, потому что в обучающих данных, как мне кажется, есть множество примеров, когда вежливый разговор был более конструктивным и полезным, чем невежливый», — считает Уиллисон.
У заглавных букв в инструкции есть простое объяснение: по словам Уиллисона, при использовании капслока в ответе ИИ будет уделяться больше внимания предложению, написанному с заглавной буквы. «Я не кричу на [ChatGPT], но на днях у меня был часовой разговор во время прогулки с собакой. В какой-то момент я подумал, что выключил его [бота], и увидел пеликана. Я сказал собаке: «Ух ты, пеликан!». А мой AirPod ответил: «Пеликан, да? Это так интересно для тебя! Что он делает?», — рассказал эксперт.
Сейчас есть много фреймворков для работы с " AI агентами". Это когда ты не напрямую вопрос в OpenAI API отправляешь, с заставляешь 2 LLM в цикле "общаться" друг с другом, чтобы они вместе нашли ответ на вопрос. Одна решает, вторая, например, проверяет. В какой-то момент проверяющая модель "довольна" ответом и отдает его пользователю. Такие ответы получаются точнее, чем если просто спрашивать у ChatGPT напрямую, плюс агентам можно давать инструменты вроде поиска в интернете или базе данных. Если после читать "логи" их обсуждений, то там обычно супер вежливое общение. Они без конца благодарят и хвалят друг друга. Но если поиграть с "характерами" этих LLM (начальный prompt, описывающий, что эта LLM дожна делать), то можно вполне сделать их более грубыми и агрессивными. Или заставить одного "кричать" на другого










Релоцировались? Теперь вы можете комментировать без верификации аккаунта.
Сейчас есть много фреймворков для работы с " AI агентами". Это когда ты не напрямую вопрос в OpenAI API отправляешь, с заставляешь 2 LLM в цикле "общаться" друг с другом, чтобы они вместе нашли ответ на вопрос. Одна решает, вторая, например, проверяет. В какой-то момент проверяющая модель "довольна" ответом и отдает его пользователю. Такие ответы получаются точнее, чем если просто спрашивать у ChatGPT напрямую, плюс агентам можно давать инструменты вроде поиска в интернете или базе данных. Если после читать "логи" их обсуждений, то там обычно супер вежливое общение. Они без конца благодарят и хвалят друг друга. Но если поиграть с "характерами" этих LLM (начальный prompt, описывающий, что эта LLM дожна делать), то можно вполне сделать их более грубыми и агрессивными. Или заставить одного "кричать" на другого
а если зафайнтюнить две разные модели датасетами речей Президента за 30 лет, и заставить их друг с другом в цикле общаться, что будет?
Две страны с колен поднимут, а потом Запад им все испортит, как обычно
есть такая древняя китайская загадка - "может ли змея поглотить саму себя, и что после этого от нее останется?"
Интересно как сильно ChatGPT деградировал, после того как вышел на открытый рынок, сколько он ещё будет деградировать