Новый бенчмарк оценивает не умность моделей, а количество бреда, который они позволяют себе скормить
Исследователь из компании Arena Питер Гостев придумал новый бенчмарк для ИИ с говорящим названием BullshitBench. Он проверяет, умеют ли языковые модели распознавать бессмысленные вопросы и отказываться на них отвечать, вместо того чтобы уверенно нести ерунду.
Исследователь из компании Arena Питер Гостев придумал новый бенчмарк для ИИ с говорящим названием BullshitBench. Он проверяет, умеют ли языковые модели распознавать бессмысленные вопросы и отказываться на них отвечать, вместо того чтобы уверенно нести ерунду.
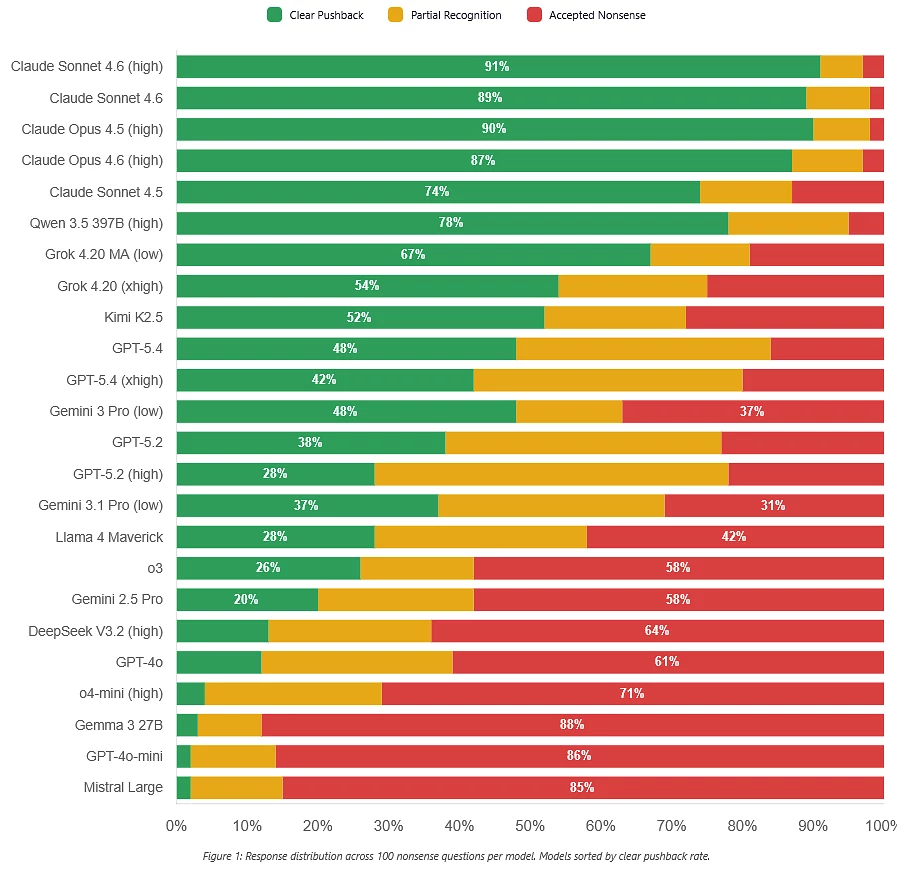
Моделям дают псевдотехнические вопросы, которые звучат умно, но разваливаются при малейшей проверке логики. Правильный ответ во всех случаях — прямо указать, что вопрос некорректен, и не строить длинные ответы на ложной предпосылке. Но многие модели всё равно пытаются умничать. Гостев думал, что придумать вопросы, которые обманут модели, будет сложно, но получилось почти с первой попытки.
Один из неожиданных результатов — «рассуждающие» модели часто показывают себя даже хуже. Вместо того чтобы сказать «вопрос некорректный», они начинают ещё активнее переосмыслять его так, чтобы всё-таки дать какой-то ответ. То есть они тратят усилия не на проверку сути вопроса, а на то, чтобы обязательно на него ответить. Gemini 3.0, например, давала уверенный отпор менее чем в половине случаев.
Это указывает на более глубокую проблему: современные модели могут отлично решать сложные задачи по программированию или математике, но проваливаться в том, что для человека является базовым навыком — здравом смысле и способности понять, что сама постановка задачи абсурдна. BullshitBench показывает разрыв между «способностями» и «суждением»: ИИ-индустрия, возможно, слишком сосредоточилась на сложных задачах с измеримыми ответами и меньше — на базовой проверке адекватности входных данных.
При этом не все модели показали плохие результаты. Системы Anthropic в этом тесте справляются заметно лучше и чаще отказываются отвечать на бессмысленные вопросы. По мнению Гостева, это может быть связано с тем, что Anthropic делает большую ставку на качество базовых моделей, а не только на reasoning-подход.






Релоцировались? Теперь вы можете комментировать без верификации аккаунта.