Можно ли вычислить пропаганду? Айтишник ищет команду, чтобы сделать плагин
В чате «Колонка некодера» Алексей, software developer с пятилетним стажем, задал вопрос: «Как технологии могут помочь бороться с пропагандой в СМИ?» И предложил разработать плагин, который будет вычислять манипуляции. Алексей описал своё видение проекта и автоматизации процессов. И рассказал dev.by, каких ищет единомышленников, чтобы идею оценить и реализовать.
В чате «Колонка некодера» Алексей, software developer с пятилетним стажем, задал вопрос: «Как технологии могут помочь бороться с пропагандой в СМИ?» И предложил разработать плагин, который будет вычислять манипуляции. Алексей описал своё видение проекта и автоматизации процессов. И рассказал dev.by, каких ищет единомышленников, чтобы идею оценить и реализовать.
— Я собираюсь разработать плагин для браузера / мобильное приложение, которые будут в реальном времени анализировать статью или посты в телеграме и идентифицировать в них попытки информационной манипуляции, — пишет Алексей.
Описание процессов
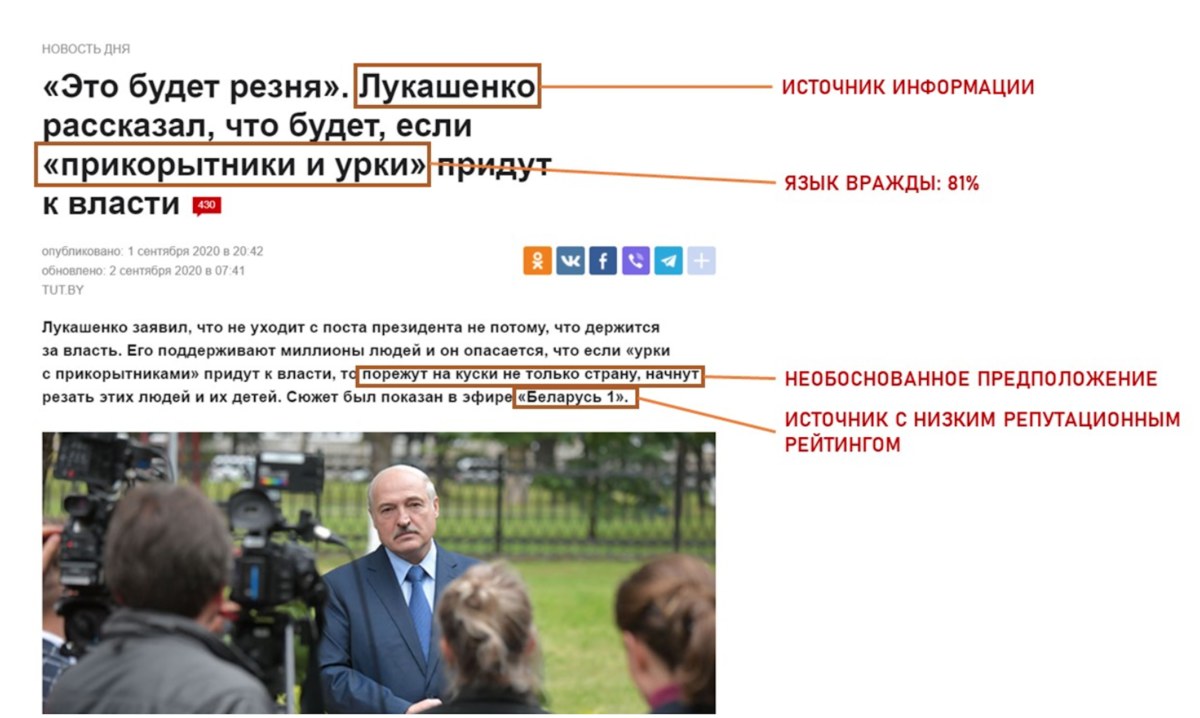
Скриншот предоставлен автором идеи. «Так проект должен работать», — говорит Алексей.
Я разработал методику, которая не претендует на полноту, но которая должна покрывать существенную часть формальных признаков пропаганды. Многие признаки может отыскать человек. Вполне возможно, и алгоритмы смогут справиться с этой задачей.
Правила для признаков пропаганды в новостных текстах разбил на несколько логических категорий:
Качество подачи материала
Был ли дан контекст?
Смысл: в конце новостного текста часто можно встретить краткое описание событий, предшествовавших тому, что произошло. Если в новости приведены выдержки из последнего интервью Трампа, в конце обычно объясняется, что сейчас в США проходит президентская гонка, и по социологическим опросам пока лидерство у того-то, а тот-то считает вот так.
Критика: не у всех событий есть контекст — некоторые из них просто происходят. Например, взрыв в Бейруте.
Автоматизация:
слова-маркеры, такие, как «напомним, что»;
можно попытаться автоматизировать экстрагирование главного смысла из статей издания, и сохранять эти главные тезисы в течение какого-то времени. При появлении новых статей, последние абзацы также сокращаются до главных тезисов и в базе прошлых публикаций этого издания происходит поиск максимально похожих тезисов. Если таковые найдены не были, то либо событие абсолютно новое, либо контекст не был дан.
поскольку не у всех событий может быть контекст, то отсутствие оного в конце статьи — не строгий критерий, и при предполагаемом отсутствии контекста должно выводиться просто предупреждение, а не «тревога».
Наличие источников
Смысл: у новости всегда есть источник, на него должна быть гиперссылка.
Критика:
Что делать с анонимными источниками (без которых не может существовать журналистика)? Что делать с расследовательской журналистикой (которая по формату отличается от новостной)?
Не у всех источников могут быть свои сайты. Либо теоретически возможна ситуация, в которой информация была передана по ТВ, но не в интернете. Оба фактора могут осложнить дачу гиперссылки.
Автоматизация:
Алгоритм должен уметь определять в тексте наличие источников информации. Либо по ключевым словам: «сообщил», «сказала», либо с помощью техник NLP.
Проверять наличие гиперссылок легко;
Если гиперссылка дана в новости Б, то можно было бы вызвать текст источника А и проверить, была ли в тексте Б использована статистически важная информация из А?
Также можно проверить, правильно ли были переданы цифры (например, из соцопроса) из текста А в тексте Б.
Анализ контента
При наличии конфликта: были ли выслушаны все стороны?
Смысл: например, если президент критикует оппозиционера, хорошо бы новостное издание спросило мнение оппозиционера по этому поводу.
Критика: не всегда такое правило имеет смысл.
Автоматизация:
Подобно тому, как мы собираемся автоматизированно выявлять источник информации, нужно научиться выявлять стороны конфликта (если это возможно алгоритмически).
Просто мысль: имеет ли смысл сохранять информацию про общественно значимых персон и организации в социальном графе? Для того, чтобы понимать, от кого ждать ответную реплику?
Сравнение: как тот же инфоповод осветили другие издания?
Смысл: сравнить подачу событий данным изданием с подачей других изданий.
Критика: не вижу слабых сторон.
Автоматизация:
Выделить из текста главные тезисы или понятия, и делать поиск по этим тезисам или понятиям в других общественно значимых изданиях (о том, как их определить, поговорим отдельно).
Или — предлагать на основе анализа текста ключевые слова, по которым читатель сразу может начать искать дополнительную информацию, например, в Google News.
Предвзятость ньюсмейкеров
Смысл: манипулятивные действия могут совершаться не только самими СМИ, но и теми, кого СМИ цитируют. Поэтому довольно неплохо знать, что ранее говорил субъект про явления, про которые высказывается сейчас.
Критика: любой человек необъективен. Поможет ли реципиенту знание, что Вячеслав Володин и раньше делал выпады в сторону Запада? Ну разве что, поможет на примере других людей задуматься о своих установках и насколько они пластичны. Что думаете?
Автоматизация: можно сохранять взаимоотношения между субъектами в социальном графе. И под рёбрами графов сохранять прошлые высказывания субъектов друг о друге.
Слова-маркеры
Смысл: есть набор слов, которые могут выдавать манипуляции или прорехи в аргументации. Например, слова выражения вроде «очевидно, что» или «все мы знаем, что».
Критика: нужно учитывать, что возможно, в некоторых контекстах подобные выражения уместны («очевидно, что насилие — это зло»). Поэтому этот критерий может быть не жёстким, а мягким (предупреждение, а не тревога). Также процесс создания базы подобных слов и выражений может быть довольно затратным в плане усилий (вероятно, нужно прочитать довольно большое количество текстов).
Автоматизация: поиск по словам (и их склонениям) и выражениям (и семантически очень близким к ним).
Анализ оттенков слов
Смысл: есть же разница в том, чтобы сказать «протестующие вышли на улицы» или «протестующие заполонили улицы»? Часто манипуляции заключаются в использовании определённой лексики, которую можно назвать «оценочной».
Критика: это должна быть непростая задача для алгоритма.
Автоматизация: психолингвисты разработали модель под названием Linguistic Category Model, которая имеет инструмент «шкала конкретности / абстрактности». Рассмотрим высказывания:
Протестующие выходят на улицы,
Протестующие заполонили все улицы,
Протестующие ненавидят власть,
Протестующие — фашисты.
Я утрирую, но общий смысл такой: существуют 4 ступени конкретности / абстрактности, от самой конкретной формулировки (фактической) до самой абстрактной (оценочной).
Для того, чтобы применить эту модель при анализе текстов, можно создать разметку понятий. Можем сконцентрироваться именно на политическом дискурсе, создавая разметку для ситуаций, часто встречающихся в политико-медийном поле. То есть, это будет что-то типа базы синонимов, в которой у каждого слова есть свои «спарринги» из других ступеней шкалы конкретности / абстрактности.
Нарративы госпропаганды
Смысл: Набор сюжетов, которые использует госпропаганда в своих материалах, довольно ограничен и пополняется новыми сюжетами довольно редко. Сколько лет мы уже слышим про «марионеток и спецслужбы Запада», или «украинских националистов»? То есть, новые мини-мотивы, конечно, появляются («диабетная кома Навального»), но на более высоком уровне абстракции, как правило, это всё те же старые мотивы, что были и год, и пять лет назад.
Критика: не нашёл.
Автоматизация:
Создание базы основных нарративов, сохраненных в разных формулировках. За этой базой нужно следить, чтобы она оставалась актуальной. Делать это могут исследователи, которые профессионально занимаются изучением пропаганды.
Анализ семантической близости между главными тезисами статьи и формулировками типичных нарративов пропаганды.
Язык вражды и войны
Смысл: медийный текст не должен содержать выражения из языка вражды.
Критика: трудно.
Автоматизация: создание базы выражений, относящихся к языку вражды. Можно создать базу вообще любых оскорбительных слов и выражений, и хотя это может усложнить задачу сбора данных, это упростит поиск в тексте выражений, которые манипулируют мнением реципиента о человеке или группе людей. Тогда и функция будет названа не «поиском языка вражды», а «поиском экспрессивных выражений» или что-то тому подобное. Не очень понятно, правда, что в таком случае делать с произведением «Идиот» Достоевского.
Анализ настроения (sentiment analysis)
Смысл: пропаганда, как мы выяснили, старается влиять на эмоции. Зачастую она вызывает негативные эмоции не из-за представления какого-либо свершившегося факта (гнев из-за избиения человека), а из-за интерпретации, обвинений и оценочных суждений.
Критика: я не знаю, насколько хороши современные алгоритмы sentiment analysis, и какие у них есть ограничения (например, по размеру текстов) для обеспечения хороших результатов.
Автоматизация: анализ настроения по абзацам, главам или всему тексту, и если негатив был найден, то вопрос пользователю: «Вероятно, вы чувствуете X. Из-за свершившегося факта или чьей-то интерпретации в отношении Y)?».
Анализ качественности СМИ
Игнорирование событий
Смысл: довольно часто пропагандистские ресурсы просто игнорируют некие события, чтобы в их «мире» этих событий вообще не существовало, и реципиенты не узнали о неких событиях, о которых манипулятор не хочет, чтобы они узнавали. Например, российские государственные СМИ долго игнорировали наличие такого оппозиционера, как Алексей Навальный.
Критика: как определить общественно значимые события? Также нужно учитывать тот факт, что у СМИ может быть некая специализация — например, экономика и финансы. Чтобы учитывать такие нюансы, будет необходимо провести объективную классификацию СМИ на основе неких прозрачных критериев, что по ряду причин будет не такой простой задачей.
Автоматизация: выжимка главного смысла из каждого материала СМИ сравнение таких «лент» от разных СМИ и определение общественно значимых событий проверка, не писало ли данное СМИ об этом событии. Честно говоря, я не знаю, как воплотить эту идею в жизнь.
Анализ прошлых материалов от СМИ для нахождения закономерностей
Смысл: характеризовать СМИ по одному или нескольким материалам затруднительно. Единожды выдать СМИ ярлык «качественного» тоже проблематично, ведь у него может поменяться редакция. Поэтому нужно характеризовать СМИ по некоему числу последних N материалов. Вот на какие аспекты можно анализировать материалы СМИ в некоем временном континууме:
Перекос в сторону информации из государственных органов; недостаток материалов, где представлено мнение оппозиции или обычных людей;
Использование нарративов пропаганды или языка вражды в журналистских материалах в прошлом
Систематическое нарушение стандартов качества подачи материалов
Критика: Не нашёл «слабых мест».
Автоматизация: сохранение обнаруженных рассмотренными выше функциями признаков в формате time series или каком-либо другом. Возможно, пользователь сможет также сам сохранять какие-то заметки.
Заключение
Цель плагина — повысить осознанность людей при прочтении новостей, научить их определять манипуляции через выразительные и другие средства.
Делать это я хочу через как можно более формализованные правила. Конечно, формализовать можно далеко не всё, и очень часто мы распознаём пропаганду, что называется, «в комплексе».
Плагин можно расширять. Например, можно создать целую систему оценки СМИ и даже отдельных журналистов, блогеров и авторов вообще (например, авторов постов в Telegram). То есть, каждый пользователь плагина сможет оценивать СМИ или автора, и эти оценки будут агрегироваться в некое подобие рейтинга для СМИ и авторов. Но это всё потом.
Буду рад любой конструктивной обратной связи, в первую очередь — мнение о том, насколько разработка того или иного инструмента реальна. Также буду рад найти среди вас единомышленников.
Кто нужен:
специалисты по Natural Language Processing (NLP), компьютерные лингвисты. Желательно те, кто уже имеет опыт обработки именно русского или белорусского языка;
веб-разработчики. Если кто-то уже работал над созданием плагинов, то вообще идеально, но необязательно. Нужны разработчики, которые смогут интегрировать модели, API и базы данных в работу плагина. Нужны те, кто будут сами создавать API;
специалисты по UX;
data engineers (работа с базами данных, создание схемы данных).
Планирую устроить процесс по принципу open source community. Хочу, чтобы разработка не была на ком-либо завязана и велась максимально децентрализованно. Это подразумевает создание теоретической базы, скорейшее согласование компонентов и их интерфейсов и открытую документацию наших результатов на всех этапах работы. Также призываю всех сохранять меры предосторожности и анонимность.
Как работается в «Лестe», Вк, Яндексе, Т-Банке в 2026. Заполните анкету!
Опросник для сотрудников беларусских офисов известных российских компаний. Если вы работаете в беларусском офисе «Лесты», Вк, Яндекса, Т-Банка (добавьте свою российскую компанию) или недавно уволились из нее, заполните эту анкету.
«За соцсети». Тимлида уволили в первый рабочий день — он в шоке
Арсений получил оффер от «хорошего продукта» и отказался от других предложений. Но поработать успел лишь до завтрака. Похоже, компания не оценила его юмор в Instagram — в отличие от 50+ тысяч подписчиков.
«Ждали 2 года. Виза — на 9 дней». Как делают визы в 2026
Виза для беларусов после 2022-го — это трудно, долго или дорого, нередко всё вместе. Условия квеста меняются, но в основном не в лучшую сторону. Мы собрали апдейты и кейсы-2026.
Почасовые рейты скоро всё? Топ-менеджер предсказал судьбу аутсорса
ИИ меняет примерно всё, и экономику сервисных компаний тоже. Как именно? Недавно эту тему довольно горячо обсуждали топы и инвесторы EPAM. А мы решили узнать мнение руководства другого крупного — но непубличного — аутсорсера.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.