Половина одобренного бенчмарками ИИ-кода не прошла ручного код-ревью
Исследовательская организация METR опубликовала подробный анализ, который ставит под сомнение реальную эффективность ИИ-агентов в программировании.
Исследовательская организация METR опубликовала подробный анализ, который ставит под сомнение реальную эффективность ИИ-агентов в программировании.

Исследовательская организация METR опубликовала подробный анализ, который ставит под сомнение реальную эффективность ИИ-агентов в программировании.
Ученые проверили, насколько результаты одного из главных отраслевых бенчмарков SWE-bench Verified соответствуют практике разработки с участием живых мейнтейнеров open source-проектов. Выяснилось, что около половины решений, которые автоматическая система оценки считает успешными, в реальности не были бы приняты в основной код.
В исследовании участвовали четыре действующих мейнтейнера трех популярных репозиториев: scikit-learn, Sphinx и pytest. Они провели ручной код-ревью 296 pull-request, созданных ИИ-моделями. Среди протестированных систем были Claude 3.5 Sonnet, Claude 3.7 Sonnet, Claude 4 Opus, Claude 4.5 Sonnet и GPT-5.
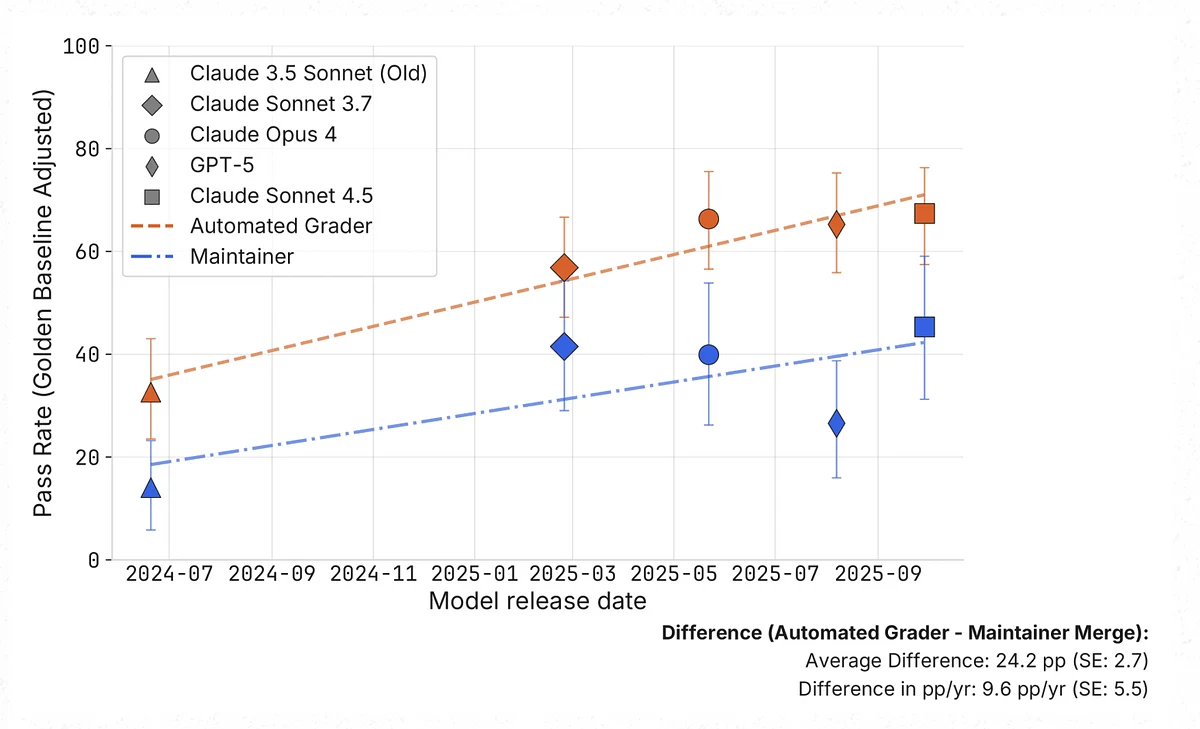
Рецензенты не знали, написан ли код человеком или машиной. В результате оказалось, что в реальной разработке такие решения принимаются значительно реже: уровень одобрения оказался примерно на 24 процентных пункта ниже, чем показывали автоматические тесты SWE-bench. Даже если учитывать, что сами человеческие решения при повторной проверке одобрялись только в 68% случаев, разница между оценками алгоритма и мнением разработчиков все равно осталась статистически значимой.
Разработчики классифицировали причины отклонения решений на три основные категории. Первая — низкое качество кода, включая несоблюдение стандартов проекта и избыточную сложность. Вторая — нарушения существующей логики системы, когда исправление одной ошибки приводило к поломке других частей кода. Третья — базовые функциональные ошибки: значительная доля решений формально проходила тесты, но фактически не устраняла исходную проблему.
Исследование также выявило различия между моделями: переход от Claude 3.5 к Claude 3.7 сопровождался ростом общего числа «успешных» решений, но увеличением случаев функциональных дефектов, тогда как более поздние версии Anthropic улучшали прежде всего качество кода. GPT-5 в среднем демонстрировал более слабые результаты по этому критерию.
Дополнительный анализ показал, что результаты тестов могут создавать неверное впечатление о том, насколько хорошо ИИ работает в реальных задачах. По автоматическим данным Claude 4.5 Sonnet достигает 50-процентного уровня успеха на задачах, сопоставимых с 50 минутами работы разработчика. Однако оценки мейнтейнеров снизили этот показатель примерно до восьми минут. Это означает, что лабораторные метрики могут завышать реальную эффективность ИИ-агентов в несколько раз.
Авторы указывают, что исследование не доказывает фундаментального потолка возможностей современных моделей. В эксперименте ИИ-системы получали только одну попытку решения задачи, тогда как в реальной разработке код дорабатывается итеративно после замечаний.
Кроме того, часть процедур ревью была упрощена: например, мейнтейнеры работали без инструментов непрерывной интеграции. Тем не менее результаты показывают, что прямое использование бенчмарков для прогнозов о влиянии ИИ на рынок труда и индустрию разработки может приводить к серьезно завышенным ожиданиям.








Релоцировались? Теперь вы можете комментировать без верификации аккаунта.