
В продолжении совместного проекта геймдев-компании Playtika и портала dev.by — техническая колонка тимлида минского офиса разработчика социальных казино Павла Андреева об опыте логирования на примере поддержки проектов с многомиллионной аудиторией.

В наше время существует множество сторонних систем для агрегации эксепшенов, крашей и логов в приложении с возможностью анализа статистики, фильтрами, сортировками... Что выбрать, как эффективно использовать и главное — как потом этим пользоваться на продакшене, мы постараемся рассказать на примере мобильного проекта компании Playtika Slotomania — самой популярной слот-игры в мире.
И уж простят меня разработчики, но данная статья написана с точки зрения QA, а не девелопмента.
Для начала определимся с «джентельменским набором» необходимых ивентов, а затем подумаем, чем и как это логировать. Итак, что нам нужно:
- Логи для бизнеса.
- Продакшен-логи.
- Локальные логи.
- Краши.
Логи для бизнеса
Логи (ивенты) для бизнеса — этакий джентельменский набор ивентов, определяющий KPI. Наиболее критичными являются следующие параметры: платежи, сессии, пользователи, девайсы, оси, географические зоны. Но, конечно же, на этом никто не останавливается. Хорошие маркетологи, продакт-менеджеры и бизнес-аналитики пытаются обложиться логами, как партизаны в окопе. Особенно если в ваше приложение ежедневно играет 2 млн человек по всему миру. Как по мне, эта группа, конечно, необходима и критична, но скучна для QA.
Продакшен-логи
Тут уже поинтереснее. Я ещё не видел приложения, которое не имело бы багов на продакшене. Ну, разве что раскрученный когда-то Diamond, стоивший тысячу долларов, а по факту отображавший просто картинку бриллианта. Почти каждая компания с крупным проектом имеет в штате так называемую Production Team, отвечающую за стабильность продукта и быстрое реагирование на продакшен-инциденты. Ключевой инструмент для такой команды — ивенты, эксепшены, краши.
Напомню, что разработанная компанией Playtika игра Slotomania — в первую очередь мобильное приложение, которое пользователи далеко не всегда запускают по WiFi или имея неограниченный пакет 3G-трафика. А значит, нельзя логировать всё, что хочется, и тем более — что попало. В то же время, проблема может появиться где угодно, и клиент должен быть готов отправить необходимые логи для ее анализа.
Что мы рекомендуем?
Для начала выделите основные функциональные блоки с точки зрения целостности и объёма возможных посылаемых ивентов. Например: логин, FB-интеграция, пуш-нотификации, фича-1, фича-2, платежи, загрузка дополнительных пакетов, сетевые ошибки, ошибки работы с сервером, ошибки работы с сервисами.
Затем добавьте механизм сегментации с вынесенными параметрами в базу, на сервер или же в JSON, который будет подгружаться на каждом старте приложения. Причём, сегментация должна производиться не только по группам, но и по платформам. Таким образом, вы в любой момент можете выключить или включить любые группы ивентов на любой платформе.
Сразу хочу добавить, что «трекать» необходимо не только разного рода эксепшены, эрроры и фаталы, но, желательно, и ключевые действия пользователя (открыл всплывающее окно, закрыл его, что-то включил, выключил, принял настройку, отказался и т.д.). В будущем это поможет собрать полную картину происходящего в приложении для анализа бага.
Таким образом, комментарии типа «Да чтоб вы все в аду горели» приобретают конкретное очертание: «фэйлится» загрузка внешних ассетов на х86-девайсах или невозможно совершить повторную покупку пакета в рамках одной сессии и т.д.
Локальные логи
Это подробные события, которые пишутся в файл и в любой момент могут быть извлечены/отправлены/прочитаны. В основном нужны для дебага и редко когда доходят до продакшена. Тем не менее, настоятельно рекомендую добавлять скрытую возможность отправки логов с устройства. Объясню почему.
Бывали случаи, когда проблема специфична для конкретного пользователя на конкретном устройстве. Анализ общих логов в таком случае редко помогает, а для компании Playtika все пользователи одинаково важны, и мы не можем просто проигнорировать проблему. Связавшись с пользователем, вы можете попросить его выполнить определённую комбинацию действий для отправки лога с его устройства и чётко определить причину некорректной работы приложения. Бывало, что у пользователя были установлены некие кастомные ограничения на сетевое сообщение, а случалось и такое, что просто закончилось место на устройстве, и он просто не мог загрузить дополнительный контент на старте.
Краши
Краши, как это ни печально, есть всегда, и с ними приходится жить. Как их все отслеживать? Какие трекеры сразу приходят в голову? Конечно же, HockeyApp и Google Analytics. Это, пожалуй, первое, что обычно прикручивают в приложения разработчики. И не удивительно.
HockeyApp — замечательный агрегатор крашей приложения с возможностью просмотра их количества на версию, анализа динамики их роста в день. Но даже у такого крутого эндпоинта есть недостаток. Допустим, вы выпустили уже 50 версий, в каждой версии у вас по 50 краш-групп. В топовых краш-группах у вас по 4-5 тысяч крашей. И тут приходит предупреждение, что краши начали сильно расти. Исходя из личного опыта, могу вам гарантировать: поиск проблемной версии, а тем более определение конкретного краша займёт длительное время. Особенно если краш не один, а проблема «размазана» по краш-группам.
Почему? Все из-за двух «маленьких» недостатков HockeyApp.
- Вы можете посмотреть распределение по количеству крашей в день максимум до вчерашнего вечера. То есть всё, что творится с цифрами сегодня, — out of mind.
- Агрегатор не строит распределение по количеству крашей сразу в нескольких группах. То есть определить, в каком месте начался «праздник», можно только перебирая все-все-все группы, заранее определив хотя бы проблемную версию.
Первый недостаток можно слегка нивелировать, используя Appdynamics — мощный инструмент, способный отображать количество крашей в рельном времени. Здесь у нас уже есть некая baseline, которая строится на основании количества крашей за предыдущий месяц и график количества крашей в реальном времени. То есть количественный скачёк крашей и момент этого скачка вы сможете моментально определить.
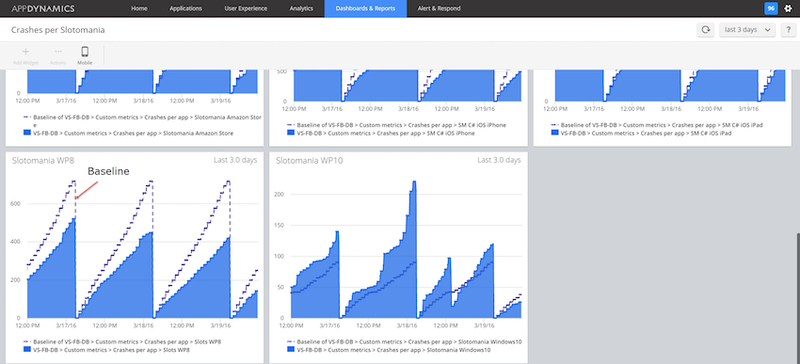
Вторую проблему можно попытаться решить, отслеживая краши в Google Analytics. Там вы легко сможете увидеть группу крашей, которая начала стремительно расти.
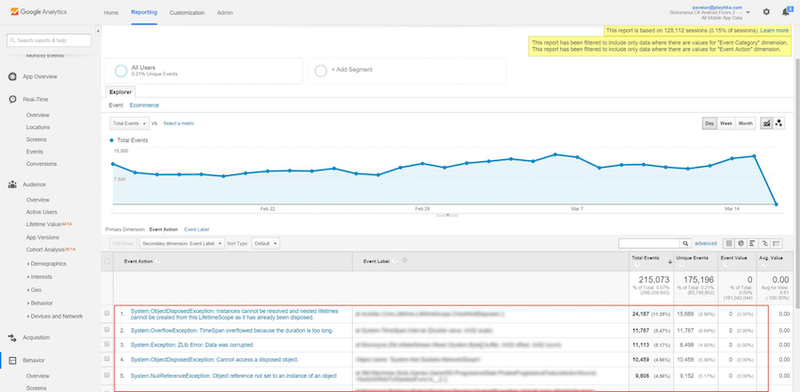
Итак, раз мы уже пришли к Google Analytics, пару слов про него. Это суперинструмент с достаточно тонкой настройкой конфигурации под себя. Он предоставляет широчайшие возможности сегментации ивентов: версия приложения, ось, платформа, брэнд устройства и его название, страна и возраст пользователя, разного рода группы и подгруппы. Всё это исключает возможность запутаться в статистике.
Стоит также отметить мониторинг ивентов в реальном времени, которые позволяют чётко видеть старт обновления пользователей на новую версию клиента, процент обновившихся и приблизительно спрогнозировать завершение обновления критической массы пользователей. С помощью аналитики вы можете отслеживать как различного рода ивенты и логи, так и краши.
Но, как у любого приложения, у Google Analytics есть минусы. Первый — количество агрегируемых ивентов для бесплатного аккаунта: их всего миллион в месяц. С каждой новой версией количество отсылаемых вашим приложением ивентов в месяц будет увеличиваться, и в скором времени вы можете превысить этот лимит.
Проблема решается переходом на премиум-аккаунт, но из-за его дороговизны советую для начала проанализировать, какая часть логирования для вас всё ещё полезна, а какая устарела и может быть удалена. Как показывает практика, после такого пересмотра статистика становится чище и эфективнее.
Что касается премиум-аккаунта, он также имеет лимит (хоть и гораздо больший), превышение которого может привести к неправильной агрегации и отображению данных, плюс к большущим задержкам и провалам статистики.
Ко второму недостатку я бы отнёс невозможность точечных запросов по ивентам. Например, вам не удастся найти все ошибки для конкретного пользователя. Тем более, вы не сможете сделать достаточно сложную выборку, для которой не помешал бы SQL-фреймворк.
В этом вам поможет Hadoop. Не очень быстрый, но незаменимый инструмент для анализа ивентов с поддержкой SQL-запросов. С его помощью вы можете сделать как достаточно точечную, так и глобальную выборку по данным. По сути это фреймфорк для работы с вашей базой данных ивентов.
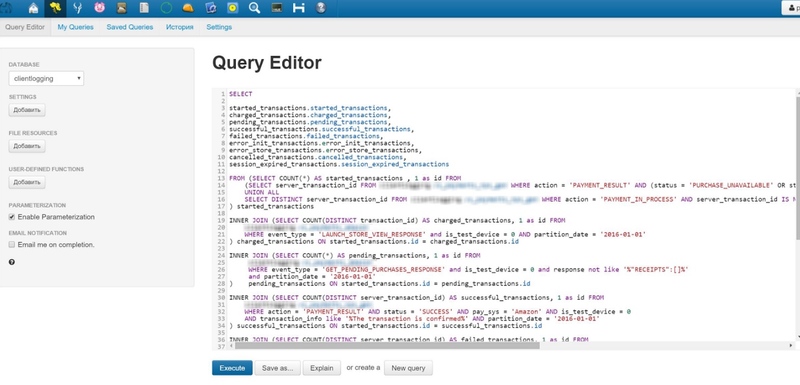
К основным недостаткам Hadoop, пожалуй, можно отнести довольно странный синтаксис, который не совсем похож на стандартный MySQL, невозможность индексации параметров для ускорения выборки и возможность наглухо «положить» сервис банальной синтаксической ошибкой.
Ах да, стоит упомянуть проблемы с разборкой некоторых JSONов — Hadoop грешит размазыванием длинных и вложенных JSONов по всей таблице базы.
Альтернативой этому сервису (на случай его отказа) мы выбрали Graylog.
Неплохая утилита, быстро агрегирующая данные, но имеет лимит на количество хранимых ивентов. То есть посмотреть ивенты за вчера вы вряд ли сможете. Также неудобна для детальной выборки (не дружит с SQL), хоть и поддерживает примитивные фильтры.
Как видите, у каждого трекера есть свои плюсы и минусы, поэтому настоятельно рекомендуем использовать как можно больше таких систем. И, несмотря на обилие разнообразных готовых решений логгеров, трекеров и агрегаторов, крупные компании всё же не могут полагаться только на них, поэтому имеют набор собственных утилит и надстроек к стандартным системам (особенно это касается логирования ивентов для анализа KPI). Тем более, что большинство инструментов спокойно делятся своими API, которые можно прикрутить к комфортному для вас UI.
Компания Playtika тут не исключение и имеет внутренние системы агрегации и хранения ивентов: Kibana, Vertica, Zabbix и т.д.
Четыре вывода на закуску
1. Перед тем, как начать логировать всё подряд, разработайте архитектуру логгера (так называемую иерархию ивентов и их сегментацию). Повторюсь: проблема может прийти когда угодно, и у вас не всегда есть возможность выпустить версию с добавленем логов, дабы понять, что происходит не так.
2. Помните: довольно частая ошибка в разработке — логирование чего-то в то время, когда логгер ещё не проинициализирован. Звучит нелепо, но это очень частый «факап».
3. Слишком много эндпоинтов — зло. Вы, конечно, перестрахуете себя во всём и везде, но начнёте генерировать терабайты трафика пользователя и в конечном счёте просто запутаетесь в форматах данных. Слишком мало - еще большее зло. Очень сложно найти «золотую середину» сразу. Все приходит со временем и опытом.
4. Думайте на шаг вперед. Старайтесь заранее обложить ивентами рискованный функционал. А в идеале, конечно же, не допускайте сомнительных фич к продакшену.
Также читайте в проекте: Как крупнейший разработчик социальных казино вырос в 15 раз за 5 лет





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.