
 Вероятностное программирование — тема для меня новая и интересная. Немного взял тут, добавил отсюда и предлагаю вам готовый вариант из двух статей. Автор — один и тот же человек, Бо Кронин. Ниже — только его текст.
Вероятностное программирование — тема для меня новая и интересная. Немного взял тут, добавил отсюда и предлагаю вам готовый вариант из двух статей. Автор — один и тот же человек, Бо Кронин. Ниже — только его текст.
Недавно DARPA (Агентство передовых оборонных исследовательских проектов США) объявило о новой инициативе, связанной с финансированием исследований в области языков вероятностного программирования. Несмотря на то что в новостях сразу появились сюжеты, в которых под определенным соусом были поданы объяснения, почему же эти исследования так важны, данная область по-прежнему остается новой и довольно неясной для большинства специалистов, работающих в области искусственного интеллекта.
Язык вероятностного программирования — это язык, в котором случайные события имеют статус примитивов первого класса. Если реализовать выразительный потенциал реального языка программирования таким образом, что он сможет обращаться со случайными событиями, то разработчик сможет легко кодировать на подобном языке сложнейшие структурированные стохастические процессы. Таким образом, можно создавать вероятностные модели событий, которые могли бы произойти в мире и генерировать заданную коллекцию данных или наблюдений.
Но в том, чтобы выразить вероятностную модель в виде компьютерной программы, нет ничего особенного — эта задача решается на уровне синтаксиса. Истинный же потенциал вероятностного языка программирования заключается в его компиляторе и среде времени исполнения (как и другие языки, вероятностный язык может быть компилируемым либо интерпретируемым). Наряду с решением обычных задач, такой компилятор или такая среда должны понимать, как выполнять в программе операции выведения (inference). Выведение позволяет ответить на вопрос вида: «какие из всех способов, которыми может выполниться программа, содержащая возможности случайного выбора, позволяют наилучшим способом описать имеющиеся данные?»
В чем же заключается автоматическое выведение? Давайте сравним вероятностную программу с классической компьютерной моделью — например с моделью климатических изменений. Нам потребуется написать программу, которая принимает в качестве ввода некий набор исходных условий, например историю температур, оценка энергии, получаемой от Солнца и т. д. Затем обычная модель использует предположения программиста о том, как должны взаимодействовать эти переменные величины. Переменные заключаются в тождествах и коде, который позволяет прогнозировать, как климат будет изменяться в будущем. Модели такого рода фактически однонаправленные: они развиваются от причин к гипотетически выводимым следствиям.
В вероятностной программе все совершенно наоборот. Имея универсум всех возможных взаимодействий между элементами климатической системы, а также набор наблюдаемых данных, мы можем автоматически заключить, какие взаимодействия наиболее полно объясняют наблюдаемые явления — даже если эти взаимодействия довольно сложны. А как это выглядит на практике? В сущности, среда времени исполнения вероятностного языка программирования одновременно выполняет программу и из начала в конец, и из конца в начало — как от данных к эффектам, так и от эффектов к тем данным, которые могли к ним привести. При грамотной реализации программы можно максимально эффективно использовать оба этих направления и находить наиболее вероятные объяснения наблюдаемых явлений.
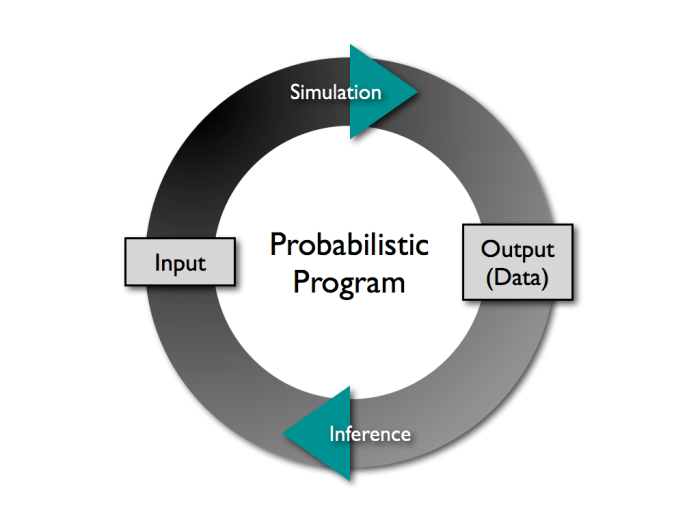
Где: Simulation — Моделирование
Probabilistic program — Вероятностная программа
Input — Ввод
Output (Data) — Вывод (данные)
Inference — Выведение
Можно сформулировать иначе: в отличие от обычной программы, которая выполняется лишь в «прямом направлении», вероятностная программа может выполняться как в прямом, так и в обратном направлении. При работе в прямом направлении программа рассчитывает все возможные следствия тех предпосылок, которые заложены в нее в виде информации о мире (под миром здесь понимается представленное в ней пространство-модель). Но программа может работать и в обратном направлении, отталкиваясь от имеющихся данных.
Второй способ работы применяется для ограничения набора возможных объяснений. На практике во многих вероятностных программах эти «прямые» и «обратные» операции, очевидно, будут переплетаться, чтобы программа с максимальной эффективностью давала лишь наилучшие объяснения.
В этом и заключается сущность вероятностного программирования. Но почему же оно нас так интересует?
Дело в том, что вероятностное программирование может дать ключ к нарративному описанию данных. Эта возможность давно кажется Святым Граалем бизнес-аналитики и научного подхода к языковым воздействиям. Человек мыслит сюжетными историями. Вот почему примеры из практики так серьезно влияют на принятие решений, независимо от того, насколько обоснованным будет такое решение. Но в рамках имеющейся аналитики сформулировать такие истории обычно не удается. Слишком часто кажется, что цифры взяты откуда-то с потолка. А человек, который взвешивает различные варианты, предпочитает ориентироваться именно на «рабочий» контекст.
Вероятностную программу как раз можно написать «генеративным» образом. Таким образом, в программе можно непосредственно закодировать целое пространство гипотез. Каждая из таких гипотез является вариантом объяснения того, как модель мира породила наблюдаемые данные. Конкретные решения, выбираемые из имеющегося множества, будут конкретными «прикладными» и нарративными объяснениями для данных.
В данном случае было бы идеально скомбинировать наилучшие аспекты эмпирического и статистического обоснования. Так мы сможем одновременно пользоваться и убедительностью «реальных историй», и предсказуемостью (а также широкими обобщениями), обеспечиваемой большими корпусами данных.
Вероятностное программирование позволяет размежевывать моделирование и выведение. Точно как в современных базах данных выполнение запросов абсолютно не связано с индексированием и хранением информации, а в высокоуровневых языках и компиляторах вопросы построения алгоритмов отделены от аппаратной стороны исполнения, в вероятностном программировании мы сможем провести еще одну важнейшую границу, которая пока отсутствует в современных самообучающихся системах.
Моделирование и выведение/обучение довольно давно считаются концептуально разными видами работы, но на практике они тесно связаны. Я имею в виду, что модели, применяемые при решении конкретной проблемы, жестко ограничены необходимостью создания репрезентативных схем выведения информации. А на подготовку и реализацию таких схем уходит масса времени. К тому же для этого требуются очень специфические навыки и опыт. Если же внести в модель даже самые незначительные изменения, то, возможно, потребуется полностью переработать подход к выведению информации. Это не место для импровизаций.
Если вероятностное программирование сможет как следует развиться, то два этих вида деятельности, наконец-то, будут однозначно разделены прочным «барьером абстрагирования»: разработчик пишет программу, которую хочет создать, а компилятор и среда времени исполнения обустраивают механизм выведения (с учетом известных проблем). Таким образом, специалист по вероятностному программированию сможет реализовывать в коде и значительно более эффективно использовать свои знания из конкретной предметной области. В итоге имеем гораздо более взвешенную аргументацию и более качественные решения, принимаемые в контексте всех имеющихся данных.
Вероятностное программирование обеспечивает более универсальные, абстрактные суждения, так как в программах, написанных в соответствии с данной методологией, можно будет непосредственно «зашивать» несколько уровней суждения, а потом осуществлять выведение, опираясь на все эти уровни одновременно. Имеющиеся системы обучения в основном сводятся к изучению тех параметров модели, которые обеспечивают наиболее качественное объяснение данных. Но такие системы не способны «судить» о том, насколько репрезентативным является весь класс моделей, к которому относится данная абстракция.
С другой стороны, вероятностные программы способны и к «сквозным» суждениям, затрагивающим сразу все уровни. Так, программа может изучить параметры модели, либо выбрать наилучшие варианты моделей из конкретного класса, либо, наконец, выбрать один из двух совершенно разных классов моделей. Конечно, нет универсального средства для моделирования случайных отклонений, а также для расчета последствий применения неподходящих моделей. Но уже имеющиеся возможности, несомненно, позволяют значительно более качественно объяснять информацию: не только с количественной, но и с качественной точки зрения.
Наконец, хотелось бы перечислить ряд ключевых проблем, которые можно будет решить при помощи вероятностного программирования.
Создавать компиляторы и среды времени исполнения, которые автоматически генерируют качественные схемы выведения информации для произвольных вероятностных программ, очень сложно.
Если все вышесказанное создает у вас впечатление слишком радужной картины, мало похожей на правду, то это потому, что такую стройную систему еще лишь предстоит создать. У исследователей впереди еще непочатый край работы. Самые успешные из современных вероятностных систем (BUGS, infer.net, factor.ie) при работе целенаправленно ограничивают выразительный потенциал языка, искусственно упрощая проблему выведения.
Все абстракции протекают, и те из них, что расположены между моделированием (написанием вероятностной программы) и выведением, — не исключение. Таким образом, некоторые вероятностные программы выполняют выведение значительно быстрее других, а причины достижения этой скорости могут быть достаточно сложны для понимания. В традиционных высокоуровневых языках программирования подобные проблемы обычно решаются методом профилирования и оптимизации, и в вероятностных системах еще предстоит разработать аналогичный инструментарий, чтобы программист мог изучать и решать проблемы, возникающие в области производительности.
Наконец, вероятностное программирование требует и иной комбинации навыков у разработчика и активного применения машинного обучения или статистических заключений. Думаю, нам останется лишь постыдиться, если такие системы разовьются, но все равно останутся маргинальными и будут применяться лишь небольшими кастами программистов. Такая незавидная судьба сегодня постигла, например, языки Lispи Haskell.
Эти проблемы, конечно же, весьма интересны. Я возлагаю большие надежды на вероятностное программирование и то, чего можно достичь в этой области в ближайшие годы. Подобными проектами уже занимаются некоторые умнейшие люди, с которыми мне когда-либо доводилось общаться, и, я думаю, что прогресс не за горами.
Заинтересовались подробностями? Почитайте о BUGS — это язык для вероятностного программирования, разработанный статистиками уже более 20 лет назад. Конечно, у него есть определенные недостатки, связанные с малой языковой выразительностью и размером множества данных (dataset), но для знакомства с темой этот язык подходит отлично. Кроме того, можете почитать ознакомительный пост Роба Зинкова, где приведены примеры некоторых моделей. Church — один из наиболее многообещающих языков вероятностного программирования. Почитайте руководства по языку, но в любом случае в нем еще предстоит доработать и механизм выведения, и весь инструментарий. Поэтому в краткосрочной перспективе вам может больше понравиться factorie, особенно если вы любитель Scala, либо MicrosoftResearch’sinfer.net, связанный с C# и F#. Отличный обзор вероятностного программирования по состоянию на конец 2012 года дают материалы последнего академического семинара, посвященного этой проблеме.
Примечание: сам я не участвую ни в текущих исследованиях вероятностного программирования, ни в программе DARPA; я просто очень заинтересованный наблюдатель.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.