
Посвящённый технологиям машинного обучения проект WILDML опубликовал краткий обзор важнейших достижений в области искусственного интеллекта за последний год. dev.by приводит сокращённый перевод текста.

Технологии машинного обучения превосходят возможности человека
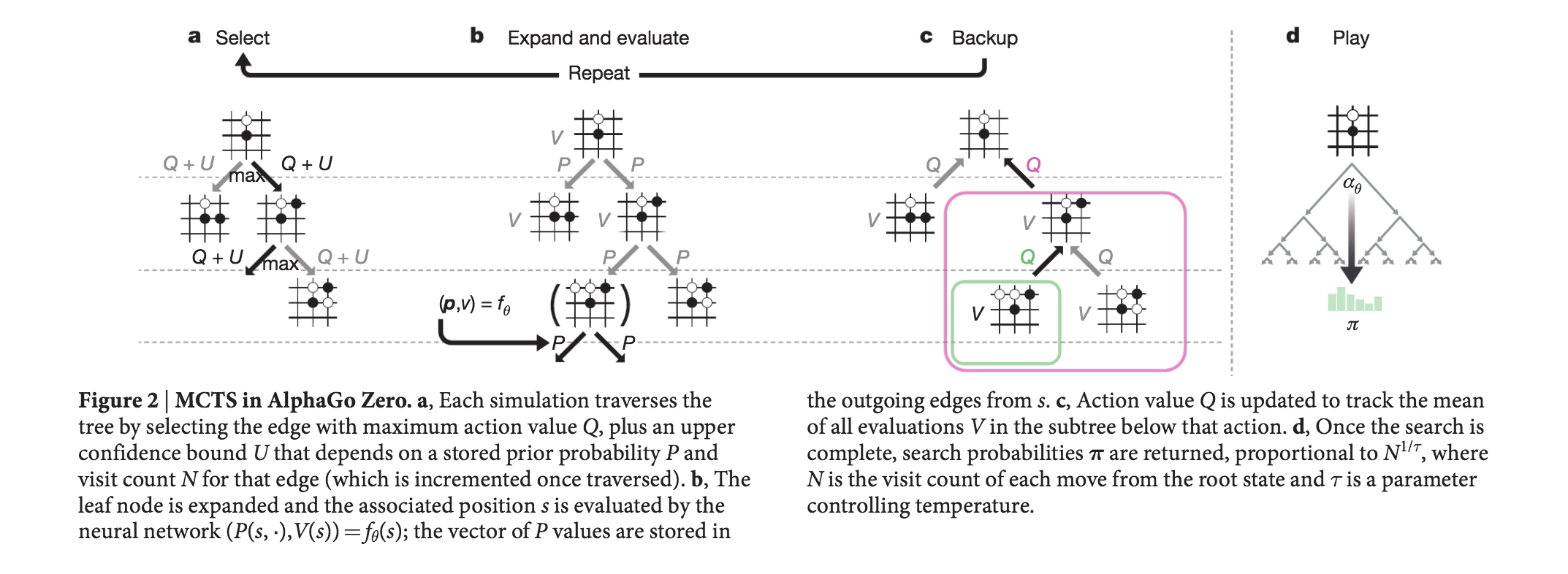
Пожалуй, самым громким публичным успехом года стало появление новой версии AlphaGo — программы, которая благодаря обучению с подкреплением разгромила чемпионов мира по игре в Го. Из-за огромного количества возможных ходов считалось, что победить в этой игре искусственному интеллекту не удастся ещё как минимум пару лет.
Изначально нейронные сети AlphaGo обучались на человеческих ходах, после чего начинали играть сами с собой, опираясь на метод под названием Monte Carlo Tree Search. Новая модель AlphaZero научилась играть лучше предыдущих версий, не имея никаких обучающих данных. К концу года вышел ещё более усовершенствованный алгоритм AlphaZero, который в добавок к Го играет ещё и в шахматы и сёги. Способности программы поражают даже самых продвинутых игроков, они сами готовы учиться у неё и заимствовать ловкие комбинации. В помощь им DeepMind выпустил специальное обучающее ПО AlphaGo Teach.
Однако Го — не единственная игра, которую освоил компьютер. Программе Libratus, разработанной в Университете Карнеги-Меллон, удалось стать на один уровень с топовыми игроками в покер на 20-дневном чемпионате по техасскому холдему. Чуть ранее покерный бот DeepStack впервые обыграл профессионалов. Его созданли учёные из Карлова университета (Чехия), Чешского технического университета и Университета Альберты (Канада). В обоих случаях игра была «один на один», где генерировать решения значительно проще, чем в игре за полным столом.
Таким образом, следующей вершиной, которую покорят технологии обучения с подкреплением, должны стать более сложные игры с большим числом участников. DeepMind активно работает над превращением среды Starcraft 2 в тестовую площадку для искусственного интеллекта, а бот OpenAI, который один на один победил сильнейших игроков в Dota 2, в недалёком будущем сможет сражаться с профи в игре пять на пять.
Возвращение эволюционных алгоритмов
В контролируемом обучении нейросетей успешно использют метод обратного распространения ошибки, и замену ему найдут нескоро. А в обучении с подкреплением, похоже, снова становятся актуальными эволюционные методы, основанные на других принципах, чем градиентные алгоритмы. Так нейронные сети можно тренировать параллельно и с очень большой скоростью, на тысячах компьютеров. При этом не нужны дорогостоящие графические чипы — можно использовать большое количество (от сотен до тысяч) относительно дешёвых центральных процессоров.
В начале 2017 года исследователи из OpenAI также показали, что эволюционные стратегии могут достичь не худших результатов, чем обычные алгоритмы обучения с подкреплением, например, Q-обучение. К концу года команда Uber в своём блоге привела ряд научных статей, демонстрирующих потенциал генетических алгоритмов и дальнейших исследований. Используя простой генетический алгоритм без каких-либо градиентов, их нейросеть учится играть в сложные игры от Atari, и показывает результаты в десять раз лучшие, чем DQN, AC3 или другие эволюционные стратегии.
Новые модели генерации речи, нейросети, распознающие изображения, и механизмы внимания
Синтезатор речи от Google Tacotron 2 весьма убедительно научился генерировать аудио. Он основан на авторегрессионной модели прогнозирования WaveNet, которая за прошедший год значительно прибавила в скорости. Ранее WaveNet применялась в машинном переводе, а сейчас используется также в Google Assistant.
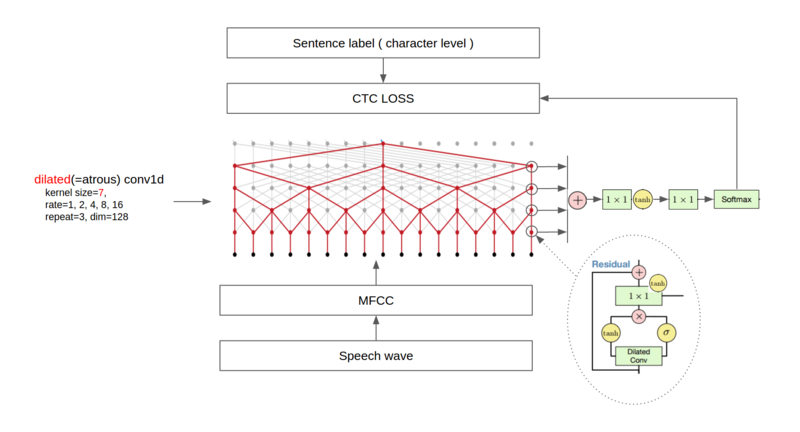
Переход от дорогих рекуррентных нейросетей, которые обучаются достаточно долго — тренд, который виден во многих направлениях машинного обучения. К примеру, в работе Attention is All you Need, исследователи полностью отказываются от рекуррентных и свёрточных нейросетей в пользу более сложного механизма внимания, позволяющего добиться отличных результатов при минимальных затратах на обучение.
Год фреймворков глубокого обучения
Если описать весь 2017 год в одном предложении, то это был год фреймворков. Стоит отметить нашумевшую библиотеку глубокого обучения PyTorch от Facebook: она завоевал расположение специалистов по обработке естественного языка благодаря своей гибкости, в отличие от статических фреймворков типа Tensorflow.
Но и Tensorflow по-прежнему важен. В феврале 2017 года вышел релиз Tensorflow 1.0 со стабильным API, совместимым с более ранними версиями. Последняя версия на сегодня — 1.4.1. Помимо самого фреймворка появилось и несколько дополнительных библиотек, включая Tensorflow Fold для динамических графов, Tensorflow Transform для конвейеров данных и усовершенствованная библиотека Sonnet, разработанная DeepMind. Также анонсирован новый режим Eager Execution, по принципу работы напоминающий PyTorch.
Вслед за Google и Facebook за разработку фреймфорков машинного обучения взялись и многие другие компании:
- Apple анонсировала CoreML — мобильную библиотеку машинного обучения;
- Команда Uber открыла код Pyro — вероятностного языка программирования;
- Amazon выпустила высокоуровневый интерфейс Gluon для MXNet;
- Uber поделился подробностями о своей ML-платформе Michelangelo.
Новые фреймворки появляются как грибы после дождя, и чтобы как-то унифицировать обмен моделями между ними, Facebook и Microsoft разработали открытый формат ONNX.
Помимо общих фреймворков глубокого обучения, появилось множество фреймворков для обучения с подкреплением:
- OpenAI Roboschool — открытый софт для обучения роботов.
- OpenAI Baselines — высокоуровневые реализации RL-алгоритмов.
- Tensorflow Agents с оптимизированной структурой для тренировки RL-агентов с помощью Tensorflow.
- Unity ML Agents позволяет исследователям и разработчикам создавать игры и симуляции на Unity и тренировать нейросети с помощью обучения с подкреплением.
- Nervana Coach позволяет экспериментировать с новейшими RL-алгоритмами.
- Facebook’s ELF — платформа для исследования ИИ в играх.
- DeepMind Pycolab кастомизируемый движок для создания игр gridworld.
- Geek.ai MAgent — исследовательская платформа для обучения нескольких агентов.
Сделать глубокое обучение более доступным призваны фреймворки, работающие прямо в браузере, например, deeplearn.js от Google и WebDNN от MIL. По крайней мере один достаточно популярный фреймворк не пережил этот год — Theano. Разработчики библиотеки сообщили, что версия 1.0 станет последней.
Образовательные ресурсы
Со взлётом популярности глубокого обучения и обучения с подкреплением в 2017 стало появляться всё больше онлайн-курсов, лекций и мероприятий. Вот самые качественные из них по мнению wildml:
- Лекции по основам обучения с подкреплением и передовые исследования Deep RL Bootcamp, предоставляемые совместно OpenAI и Калифорнийским университетом в Беркли;
- Весенний курс Стэнфорда по применению свёрточных нейросетей к компьютерному зрению. Стоит заглянуть и на официальный сайт курса;
- Зимний курс Стэнфорда по глубокому обучению в обработке естественного языка. И страница курса;
- Курс по теориям глубокого обучения от Стэнфорда;
- Новая DL-специализация на Coursera;
- Материалы Летней школы по DL и RL в Монреале;
- Осенний курс Калифорнийского университета в Беркли, посвящённый машинному обучению;
- Конференция для разработчиков Tensorflow Dev Summit и выступления об основах глубокого обучения и изменениях в API;
- Материалы со многих научных конференций сейчас стали выкладывают в сеть. Узнать всё о передовых исследованиях можно из записей с NIPS 2017, ICLR 2017 и EMNLP 2017;
На ресурсе arXiv исследователи также размещают бесплатные учебные материалы и научные статьи. Вот несколько занимательных примеров:
- Deep Reinforcement Learning: An Overview — обзор последних достижений в RL;
- A Brief Introduction to Machine Learning for Engineers — краткое введение в машинное обучение для разработчиков;
- Neural Machine Translation — про нейронный машинный перевод;
- Neural Machine Translation and Sequence-to-sequence Models: A Tutorial — гайд по нейронному машинному переводу и модели обучения sequence-to-sequence.
ИИ в медицине
В 2017 году прозвучало много смелых заявлений о том, что технологии глубинного обучения в медицине превзойдут способности человека. Но несмотря на ажиотаж, оценить значимость открытий человеку, далёкому от медицины, совсем не просто. Достаточно исчерпывающе о них рассказывает в своём блоге The End of Human Doctors Люк Оукден-Райнер. Вот выжимка наиболее важных моментов.
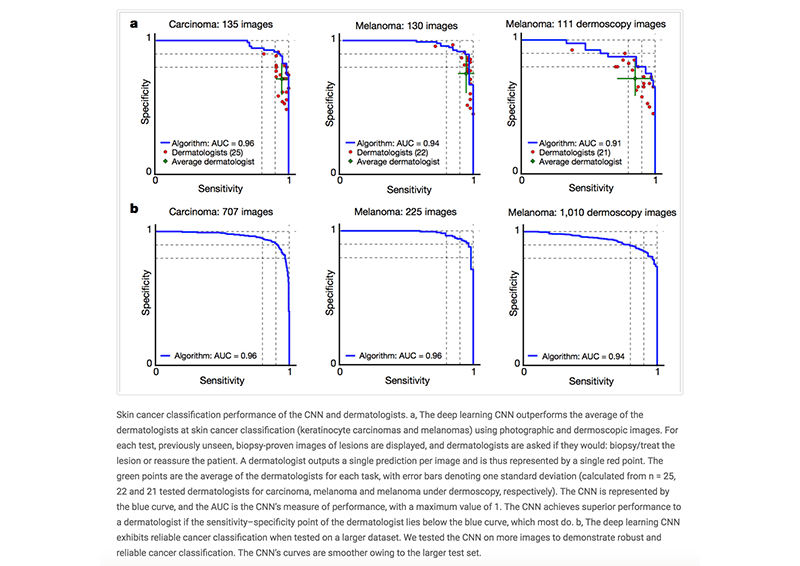
Одной из самых громких новостей стало создание исследователями Стэндфордского университета алгоритма глубинного обучения, который диагностирует рак кожи не хуже квалифицированных дерматологов. Об этом можно почитать на сайте Nature. Ещё одна команда из Стэнфорда разработала модель машинного обучения, способную эффективнее врачей выявлять признаки аритмии по ЭКГ.
Не обошлось в в 2017-м и без проколов. Много вопросов возникло по поводу сделки DeepMind и Национальной службы здравоохранения Великобритании, которая открыла доступ к данным пациентов. Национальный институт здоровья США предоставил научному сообществу более 100 тысяч рентгеновских снимков грудной клетки, однако позже оказалось, что они бесполезны для обучения нейросетей.
ИИ в искусстве
Всё интенсивнее применяется генеративное моделирование для порождения изображений, скетчей, музыки и видео. На конференции NIPS 2017 впервые был проведёт мастер-класс на тему ML в творчестве и дизайне.

Создатели QuickDraw из Google обучают нейронные сети распознавать, а потом даже дорисовывать пользовательские наброски.
Настоящий прорыв в 2017 году совершили генеративно-состязательные сети (GAN). Впечатляющие результаты показали модели CycleGAN, DiscoGAN и StarGAN, которые умеют, например, рисовать лица. Обычно GAN-ам тяжело давались реалистичные изображения высокого разрешения, но pix2pixHD может исправить это уже в скором времени.
ИИ для беспилотных автомобилей
Крупнейшие разработчики самоуправляемых авто — сервисы по заказу такси Uber и Lyft, Waymo (дочка Alphabet) и Tesla. Uber начала год не совсем удачно: в Сан-Франциско их беспилотник несколько раз проехал на красный — из-за сбоя программы, а не по вине водителя, как сообщалось ранее. Uber также поделилась некоторыми деталями о своей платформе для визуализации данных. К декабрю машины Uber преодолели в автономном режиме более 3,2 млн км.
Между тем, в апреле первых клиентов прокатили беспилотные авто Waymo, а в Финиксе компания полностью отказалась от «живых» водителей в тестировании. Компания также рассказала о том, как обучает в режиме симуляций и тестирует свои авто.
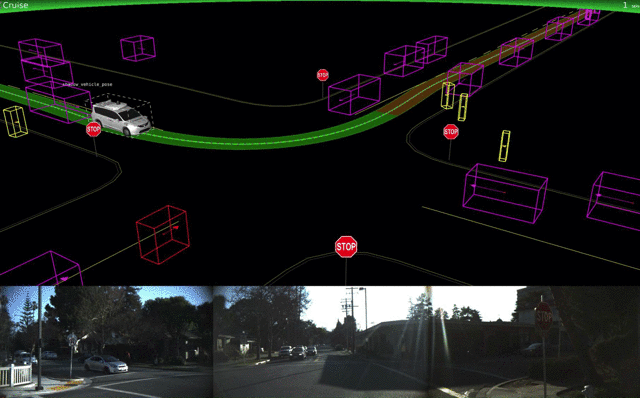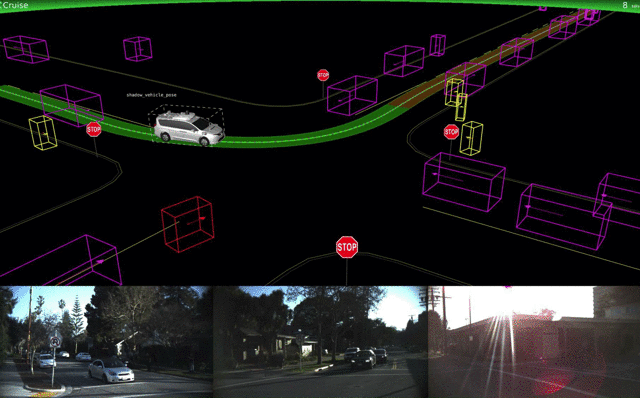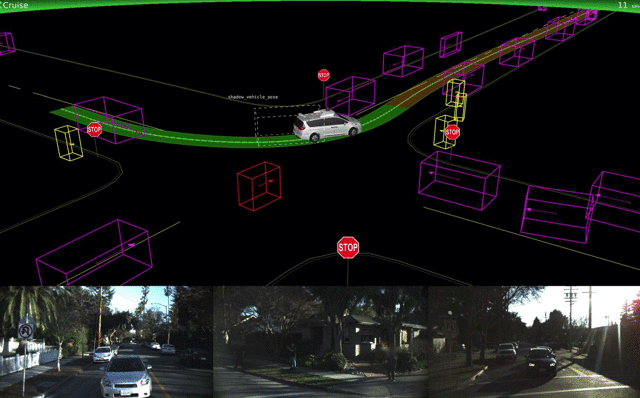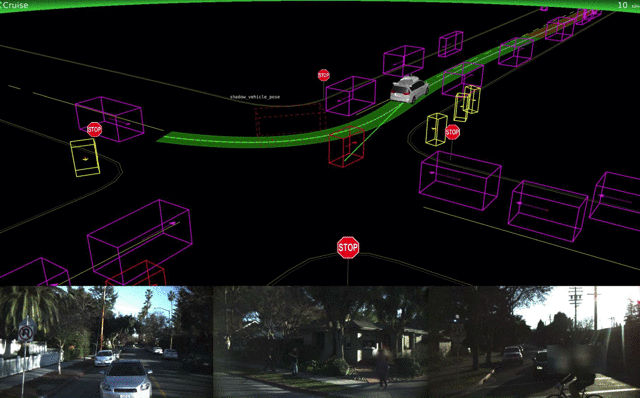
Lyft объявила о работе над собственными процессорами и соответствующим ПО и уже тестирует его в Бостоне. Автопилот Tesla значительно не изменился, но зато у него появился новый конкурент — Apple. Тим Кук подтвердил, что его компания разрабатывает ПО для самоуправляемых авто, некоторые работы исследователей уже можно найти на arXiv.
Исследовательские проекты
В 2017 года вышло огромное количество впечатляющих проектов и демо, упомянуть все в одном обзоре невозможно. Вот лишь некоторые разработки:
- Нейросети, умеющие самостоятельно менять фон изображений;
- Модель для создания персонажей аниме;
- Раскрашиваем чёрно-белые фото с помощью нейросети;
- Нейросеть, оставившая позади соперников в Mario Kart;
- И тренирующаяся играть в Mario Kart 64 в онлайн-режиме;
- Распознающая подделки произведений искусства;
- И по отдельным деталям воссоздающая изображения.
И немного исследований:
- The Unsupervised Sentiment Neuron — система, которая может с высокой точностью определять, положительным или отрицательным будет отзыв на Amazon, и предсказывать дальнейший текст;
- Learning to Communicate — исследование, в котором агенты разрабатывают собственный язык;
- The Case for Learning Index Structures — новая, на 70 процентов более быстрая модель поиска нужного элемента по индексу;
- Attention is All You Need — о механизмах внимания в машинном переводе;
- Mask R-CNN — фреймворк для сегментации изображений;
- Deep Image Prior для восстановления и ретуширования изображений.
Для обучения нейронных сетей им нужно «скормить» тонны информации, поэтому исследователей тут действительно спасают открытые массивы данных. Вот самые полезные из них:
- Youtube Bounding Boxes;
- Google QuickDraw Data;
- DeepMind Open Source Datasets;
- Голосовые команды Google;
- Atomic Visual Actions;
- Датасет картинок Open Images;
- Обширный датасет музыкальных нот с пометками Nsynth;
- Вопросы-дубликаты на Quora.

Глубокое обучение: наука и алхимия
На протяжении года многие исследователи задавались вопросом, насколько воспроизводимы результаты, описанные в научных статьях. Модели глубинного обучения зачастую опираются на громадное число гиперпараметров, которые нужно настраивать, чтобы достичь тех результатов, о которых не стыдно написать. Такие затраты могут себе позволить разве что Google и Facebook. Исследователи не всегда открывают код, упускают важные детали в публикации, используют в чём-то отличающиеся процедуры оценки или постоянно подгоняют гиперпараметры к тестовой выборке. От этого повторить заявленные результаты становится сложнее. В работе Reinforcement Learning That Matters исследователи доказали, что одни и те же алгоритмы с различными базами могут давать значительно разнящиеся друг от друга результаты.
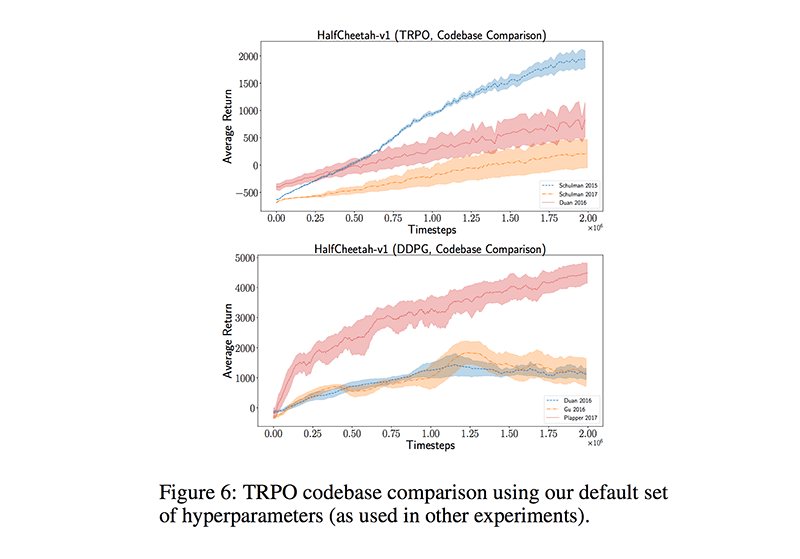
В масштабном исследовании Are GANs Created Equal? A Large-Scale Study исследователи проиллюстрировали, что хорошо отлаженная GAN может быть эффективнее, чем более сложные и «лучшие» подходы. Также авторы исследования, посвящённого оценке нейронных языковых моделей показали, что простая, но тщательно настроенная LSTM-сеть превосходит более новые модели.
Али Рахими на NIPS сравнила некоторые новейшие DL-подходы с алхимией, в чём с ней согласились многие специалисты, и призвала серьёзнее относиться к постановке исследований. Это заявление очень обидело Яна Лекуна, так что его ответ не заставил себя ждать.
Искусственный интеллект в Канаде и Китае
Пока США ужесточают миграционные правила, компании стремятся обзавестись офисами за пределами страны, и в первую очередь в Канаде. Google открыла новый офис в Торонто, DeepMind — в Эдмонтоне, а Facebook AI Research теперь присутствует и в Монреале.
Другой привлекательной страной стал Китай. Огромные бюджеты, талантливые специалисты, и относительная доступность государственных данных делают Китай не менее благоприятным местом для развития ИИ и размещения производств, чем США. Новую лабораторию в Пекине скоро собирается открыть и Google.
«Железные» войны: Nvidia, Intel, Google и Tesla
Современные технологии глубинного обучения далеко не уйдут без дорогостоящих графических процессоров, необходимых для обучения нейросетей. Пока что бесспорным лидером здесь является NVIDIA. В 2017 году компания анонсировала мощнейший в мире GPU Titan V.
Но страсти накаляются. Тензорные процессоры Google стали частью облачного сервиса компании, Intel показала линейку процессоров Nervana, и даже Tesla призналась, что разрабатывает собственные ИИ-процессоры. Возможно, скоро на пятки им начнёт наступать и Китай, где производители процессоров для майнинга биткоина хотят попробовать свои силы в изготовлении GPU для искусственного интеллекта.
Много шума и… ничего
Чем больше хайпа, тем больше и ответственность. Но, к сожалению, то, о чём кричат медиа, и то, что действительно происходит в исследовательских лабораториях, очень часто абсолютно разные вещи. Суперкомпьютер IBM Watson — яркий пример раздутой шумихи и неоправдавшихся ожиданий. После ряда неудач в медицине отношение к нему неоднозначное.
Сильно потрясла общественность Facebook, которая была вынуждена отключить систему искусственного интеллекта, когда «боты изобрели свой язык». Но шум раздули на пустом месте. Исследователям просто пришлось свернуть стандартный эксперимент, который не давал желаемых результатов.
Но «хайп» поднялся не только из-за СМИ. Исследователи сами перегнули палку, дав провокационные и далёкие от действительности названия своим работам, например, этой о генерации естественной речи или этой о машинном обучении для рынков.
Громкие увольнения топовых менеджеров
Несколько раз засветился в сводках новостей сооснователь Coursera Эндрю Ын, известный массовыми открытыми онлайн-курсами по ML. В марте он покинул Baidu, где возглавлял команду исследователей ИИ, собрал фонд в $150 млн и организовал стартап landing.ai, ориентированный на промышленное производство. Гари Маркус покинул пост руководителя лаборатории искусственного интеллекта Uber, Facebook наняла бывшего старшего менеджера по машинному обучению Siri, и несколько видных исследователей ушли из OpenAI, создав собственную компанию по робототехнике.
Профессоры всё чаще сбегают из университетских лабораторий в крупные компании, ведь зарплаты там несравнимо выше.
Стартапы: инвестиции и приобретения
Как и в прошлых годах, в 2017 ИИ-стартапы были нарасхват:
- Microsoft приобрела DL-стартап Maluuba;
- Google Cloud купила Kaggle;
- Softbank купила специализирующуюся в робототике Boston Dynamics;
- Facebook поглотила Ozlo, разработчика ИИ-ассистента
- Samsung приобрела Fluently для поддержки Bixby
… и просто много и усердно собирали инвестиции:
- Mythic собрала $8.8 млн на разработку чипа для искусственного интеллекта
- Element AI, платформа для создания ИИ-решений, подняла $102 млн
- Drive.ai, к которой присоединился Эндрю Ын, подняла $50 млн
- Graphcore собрала $30M
- Appier подняла $33 млн в раунде C
- Prowler.io получила $13M
- Sophia Genetics подняла $30 млн для изучения геномных данных и ускорения диагностики пациентов






Релоцировались? Теперь вы можете комментировать без верификации аккаунта.