
В сентябре стартовали продажи самого быстрого сканера фотографий на рынке Epson FastFoto FF-640. Цель производителя достаточно амбициозна: ввести в жизнь рядовых пользователей высокоскоростной сканер, который бы позволял оцифровывать бумажные фотографии в домашних условиях, параллельно улучшая их качество. Над инновационным продуктом трудилась международная команда, в том числе минская группа разработчиков Softeq Development. Работа над десктопным приложением под Windows и macOS, которое предоставляется в комплекте поставки сканера, продолжалась почти год.
О внедрении уникальной функции автоматического удаления эффекта красных глаз читателям dev.by рассказывает Артём Мерц, Unit Lead в Softeq Development.

Вообще тема обработки изображений очень интересная и широкая, а для меня она была практически новой. У нас когда-то был курс в университете, но этого было, конечно, недостаточно, чтобы имплементировать все, что требовалось на проекте. Поэтому сначала я решил подтянуть матчасть. Прочитал книгу Digital Image Processing автора Rafael C. Gonzalez, прошел курс Fundamentals of Digital Image and Video Processing на Coursera, перелопатил кучу документации и блогов. Это позволило добиться хорошего результата на практике, но давайте обо всем по порядку.
Итак, мы разработали три алгоритма обработки фото.
Алгоритм восстановления цвета
Проблема выцветания изображений, тусклости и пожелтения бумаги знакома, наверно, каждому по детским фотоальбомам. Со временем проявляется эффект старения бумаги, с которым и борется наш алгоритм, восстанавливая цвет фото до состояния новой, только что распечатанной фотографии.
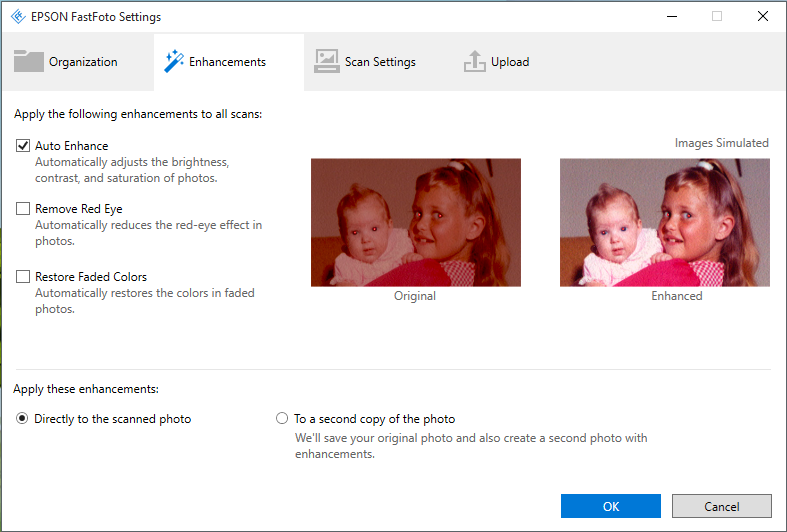

Алгоритм улучшения фото
Этот алгоритм призван добавлять контрастности и вытягивать цвета фотографии. Эффект можно отдаленно сравнить с ретушью в фотошопе.

Конечно, такие решения не могут быть универсальными на 100%. Если в большинстве случаев алгоритмы по выравниванию баланса белого или увеличению контраста отрабатывают на «ура», то в определенных сценах они портят изображения: фото заката, например, после автоматической обработки стало голубым. При этом с точки зрения частотных метрик фото идеально, однако, человеческий глаз (и мозг) воспринимает все по-другому.


Тем не менее в большинстве случаев оба эти алгоритма действительно улучшали фотографии. На случай исключений, как в примере с закатом, в приложении предусмотрена возможность откатить автоматическую коррекцию и оставить просто «голый» скан.
Алгоритм автоматического удаления эффекта красных глаз
Как ни удивительно, готовых решений на данный момент не существует. Есть множество упрощенных вариантов, но они требуют активного вовлечения пользователя: он должен вручную указать компьютеру глаза на лице и кликнуть в центр красного зрачка, чтобы алгоритм начал его обрабатывать. При этом успешно они работают только на фотках огромного разрешения, где лицо сфотографировано ровненько анфас, а глаза красные настолько, что и Терминатор бы позавидовал.
Наша задача была намного сложнее. Целевой потребитель продукта — типичная домохозяйка среднего и старшего возраста, которой необходимо оцифровать кучу старых семейных фото, и чтобы при этом процесс оставался таким же простым, как закипятить воду в чайнике. Поэтому самым главным было полностью отказаться от привлечения пользователя. Единственное, что от него требовалось, — вставить фото в устройство.
В итоге мы разработали кастомный алгоритм, адаптированный под реальные фото и осуществляющий максимально деликатное удаление красных глаз. Чтобы упростить эту комплексную задачу, мы разбили ее на этапы:
определение лица — определение глаз — определение зрачка — ретушь зрачка.
Первое, что мы делали для распознавания лица и глаз — определяли ориентацию фотографии. То, какой стороной фото было вставлено в сканер, очень сильно влияло на точность определения лиц и глаз. Каждый скан мы поворачивали три раза, каждый раз распознавали лицо и глаза, анализируя их качество. В итоге выбирали тот вариант, где правильных лиц — с двумя глазами на каждом — было больше всего.
На этом этапе мы использовали библиотеку OpenCV, но у её алгоритма по поиску образов есть ограничения. Например, если голова человека на фото наклонена или повернута, то лицо не определяется. OpenCV определяет и исключает глаза котов, собак, игрушек, что облегчило нам задачу. Например, на одной из тестовых фото человек обнимал ростовую куклу Гуфи. Так вот у Гуфи, по мнению OpenCV, глаз нет. Уже неплохо!
Однако, над настройкой самого алгоритма обнаружения глаз на лице от OpenCV нам пришлось поколдовать. Изначально он подразумевает, что программист может указать параметры точности для нахождения заданного образа. Проблема в том, что если указать эти параметры слишком точными, то найдутся только самые «явные» глаза, а многие менее очевидные не будут обнаружены. Наоборот, если понизить эти параметры, то глаза найдутся и у Гуффи.
В основе нашей модели лежало то, что у лица по определению два глаза, один из которых слева, а другой — справа. Звучит смешно и очевидно, но на практике, когда мы уменьшали точность, то глаз могло найтись пять, а при увеличении — могло не оказаться вообще. Мы пытались найти баланс между этими числами, поэтому приходилось вводить дополнительные критерии. Например: мы разбивали распознанное лицо по вертикали пополам и уже на каждой из половинок искали по 1 глазу. Если их оказывалось несколько, скажем, пять, мы начинали сравнивать положение и размер прямоугольников — «кандидатов в глаза». Если группа потенциальных глаз из четырех прямоугольников была сконцентрирована в одном месте, а ещё один висел где-то на отшибе, то мы делали предположение, что наверно это мусор, а вот в той группе прячется искомый глаз.
К сожалению (или к счастью), в рамках проекта нам не довелось заняться обучением нейронных сетей, которые лежат в основе технологии распознавания объектов на изображениях, хотя такой опыт у нас в команде есть. Мы использовали готовые каскады: смотрели какие из них лучше подходят для нашего кейса, какие статистически дают меньше ошибок — и выбирали наиболее эффективные.
Нюансы со зрачками: RGB vs HSL и эквализация гистограмм
Переходим к этапу определения и закрашивания зрачка. Изначально мы пытались использовать стандартные методы. Мы знали, где глаз, и, казалось бы, оставалось лишь найти круглое пятно около его центра. Но реальность такова, что на старых фотках зрачки оказывались квадратными, ромбовидными — любой формы, но только не круглые. Это привело нас к решению ввести параметр цвета.
Однако, и с цветом оказалось все не так просто. Сначала мы пошли по модели, основанной на RGB-цветах. Мы сравнивали канал красного (R) c каналами зеленого и синего (G и B), и если он был больше них на определённую величину, то мы утверждали, что красный цвет найден. Но на сканах фоток зрачки были всех оттенков (от розового до оранжевого), при обработке всё размыливалось, и результат вообще не коррелировал с оригиналом.
Так мы пришли к модели HSL (и HSV). В ней один из каналов отвечает за оттенок, что позволило нам выделять сектор красного, одновременно анализируя его яркость и насыщенность. При этом мы учитывали эти три показателя для всей картинки, а не только для области зрачка, чтобы получить усредненное значение. Благодаря этому мы статистически поняли, на сколько красный зрачок по яркости и насыщенности отличается от всего остального.
Итак весь процесс выглядел следующим образом:

Мы вырезали глаз и анализировали цвета на картинке: чем дальше каждый пиксель от того идеального красного, который мы ищем, тем он темнее, и чем ближе — тем белее. В результате мы получаем картинку распределения нужного красного на глазу. Следующим этапом мы применяли подход под названием эквализация гистограмм. Упрощённое объяснение ниже, а более подробно можно почитать здесь и здесь.

По оси Х расположены все возможные цвета, пронумерованные от 0 (максимально чёрный) до 255 (максимально белый), а ось Y — это количество каждого из цветов. Чем более спокойный, плоский график, тем более разноцветное и контрастное изображение. И наоборот: пик означает превалирование какого-то одного цвета и ближайших к нему оттенков. Так вот эквализация гистограмм позволила нам найти такой пик (в нашем случае красный), увеличивая контрастность.
Дальше на этапе трешхолда (threshold) мы анализировали градиенты на фото и итерационно обрубали значения, которые меньше задаваемого порога. Таким образом мы ввели параметр тусклости. Пиксели, которые были более тусклыми, чем установленный порог, мы закрашивали белым. Постепенно увеличивая порог яркости, мы достигали чёткой чёрно-белой картинки. Потом в полученной картинке мы прорисовывали контуры. Далее мы искали круги на контуре и наклыдывали их на трешхолд-картинку. Проанализировав плотность белых пикселей внутри и вокруг круга, мы выбирали тот, внутри которого этот показатель был максимальным.

Выбранный круг мы использовали, чтобы вырезать маску для последующей ретуши красного зрачка. В итоге результат получался наиболее естественным.
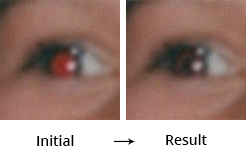
Национальный вопрос
Довольно весело проходил тюнинг алгоритма для обработки фотографий людей разных рас. В тестовых целях мы использовали несколько фотографий темнокожих людей и индейцев. Оттенок их кожи сам по себе достаточно красный, что затрудняло определение красного зрачка. Статистический анализ всего изображения очень помогал в таких случаях. Мы брали средний показатель красного по фото и поднимали минимальный уровень, чтобы в итоге на основании данных об освещенности и насыщенности найти зрачок. Изначально наш алгоритм был «расистом» и таких гибких допущений не делал.
Новая порция исправлений была внесена после тестового прогона с фотографиями азиатов. Из-за специфического разреза даже распознание глаз на лице было проблемой, не говоря уже о зрачке, который оказался совсем другой формы. Нам пришлось ввести уточняющие параметры: например, что глаза должны быть в верхней половине лица, а не в нижней. Именно обрабатывая изображения неевропеоидов, мы немного модифицировали наш алгоритм, расширив диапазон допустимых значений, и убедились в полезности анализа целой картинки, а не только самого зрачка.

Мы гордимся полученным результатом. Аналогов у нашего алгоритма нет. Он автоматизирует полный цикл: от нахождения лица до собственно редактирования красных зрачков, без вовлечения пользователя. Точность распознавания и закрашивания красных глаз около 70% при 300 dpi. Это очень хороший результат. С увеличением разрешение фото до 600 dpi точность также возрастает. Сам Epson остался очень доволен работой минской команды Softeq, и наше сотрудничество расширяется по многим направлениям.
Стек технологий десктопного приложения:
- В основе лежит .NET для Windows и Mono/Xamarin.Mac для Mac.
- Для нативного UI мы используем WPF и Cocoa/Interface Builder.
- Функционал по обработке изображений написан на C++ при поддержке фреймворков OpenCV и ImageMagick.
- Общение со сканером происходит через TWAIN-фреймворк, используя кастомный протокол.
- Инсталлятор на Windows сделан с помощью Wix Toolset.
- Приложение интегрируется с Facebook и Google Drive по REST API.
- Написаны различные скрипты на Python, AppleScript, Shell для постановки цифровой подписи, автоматизации сборки компонентов и др.





Рэлацыраваліся? Цяпер вы можаце каментаваць без верыфікацыі акаўнта.