
Искусственный интеллект и машинное обучение — одни из самых горячо обсуждаемых тем в мире ИТ. Эти два словосочетания звучат повсюду: начинающие разработчики хотят изучать ИИ, предприниматели стремятся внедрять ИИ в свои услуги. Но зачастую многие из них понятия не имеют, что такое «ИИ». В своём блоге разработчик Раду Райча простым языком объяснил основы искусственного интеллекта и машинного обучения, а также как работает наиболее распространённый вид МО — глубокое обучение.
Введение
Искусственный интеллект (ИИ) и машинное обучение (МО)
Искусственный интеллект — это модель человеческого интеллекта в компьютере.
В самом начале работы над ИИ учёные пытались смоделировать интеллект человека для решения конкретных задач, например, играть в игры. Они вводили огромное количество правил, которые компьютер должен был соблюдать. У компьютера был некоторый список возможных действий, и он принимал решения, отталкиваясь от этих правил.
Машинное обучение обозначает способность компьютера обучаться на основе массивных наборов данных, а не руководствуясь сложно закодированными правилами.
МО позволяет компьютерам учиться самостоятельно без помощи человека. Такой метод обучения возможен благодаря вычислительным мощностям современных компьютеров, которые способны быстро обрабатывать большие массивы данных.
Обучение с учителем и обучение без учителя
Обучение с учителем — способ МО, в ходе которого ИИ обучается на основе помеченных массивов данных по принципу «стимул-ответ»: разработчики задают обучаемой системе «входы» и ожидают получить эталонные «выходы».
Если система выдаёт неправильный ответ, то она должна исправить вычисления. Этот процесс многократно повторяется в рамках одного набора данных, пока ИИ не перестанет делать ошибки.
Например, обученный с учителем ИИ, который предсказывает погоду. Такая система учится делать прогнозы на основе архивов метеорологических данных. Эти обучающие массивы включают как входные данные (атмосферное давление, влажность, скорость ветра), так и эталонные выходы (температура).
При обучении без учителя испытуемая система должна научиться логически обрабатывать данные без вмешательства экспериментаторов.
Примером такого вида обучения может быть ИИ, который предугадывает поведение пользователей онлайн-магазинов. Здесь система будет учиться не на предоставленных наборах данных с заданными стимулами и ожидаемыми ответами, а самостоятельно классифицировать входные данные и вычислять, какой тип пользователей с большей вероятностью купит тот или иной продукт.
Как работает глубокое обучение
Глубокое обучение — один из методов МО. Он позволяет научить ИИ предсказывать ответы на основе заданного набора стимулов. Для тренировки ИИ может применяться обучение и с учителем, и без учителя.
Как работает глубокое обучение можно рассмотреть на примере обученного с учителем сервиса, который рассчитывает стоимость авиабилетов. Система расчёта стоимости авиабилетов будет предсказывать цены на основе следующих входных данных:
- местонахождение аэропорта;
- планируемый пункт назначения;
- дата вылета;
- авиакомпания.
Нейронные сети
Как и мозг человека, «мозг» ИИ-системы имеет нейроны. На иллюстрации ниже они обозначены кружками. Эти нейроны взаимосвязаны.
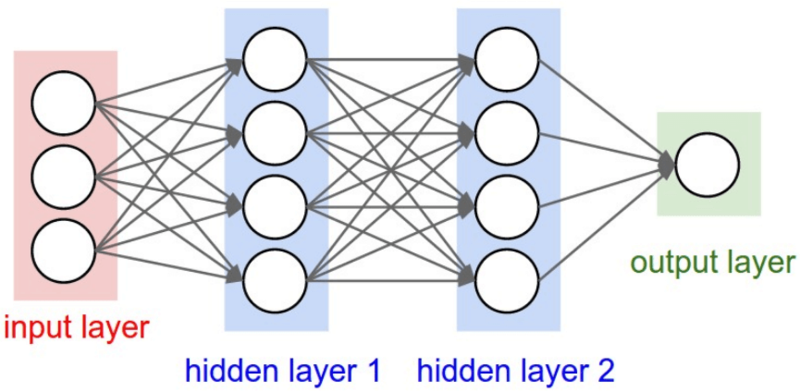
Нейроны сгруппированы в три слоя:
- входной слой;
- скрытый слой (их может быть несколько);
- выходной слой.
Входной слой получает входную информацию. В данном примере на этом слое имеется четыре нейрона: местонахождение аэропорта, пункт назначения, дата вылета и авиакомпания. Входной слой передаёт входы первому из скрытых слоёв.
Скрытые слои производят математические вычисления над входами. Одна из сложностей при создании нейросетей состоит в том, чтобы определить необходимое количество скрытых слоёв, а также число нейронов на каждом из них. Слово «глубокое» в глубоком обучении означает, что в ИИ присутствует более одного скрытого слоя.
Выходной слой выводит полученный ответ — в данном случае, предполагаемую цену билета.
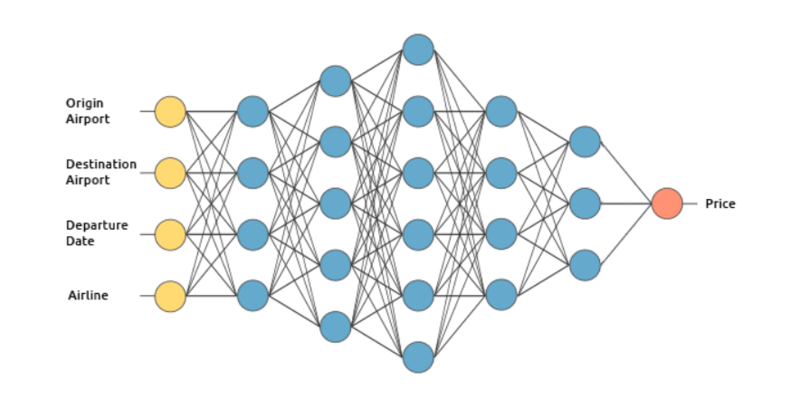
Магия глубокого обучения начинается с того, как ИИ подсчитывает цену билетов. Каждая связь между нейронами имеет свой вес. Веса характеризуют значимость входных данных и изначально задаются в случайном порядке. При подсчёте цены авиабилета, один из самых «тяжёлых» факторов — дата вылета, а значит, связи с этими нейронами будут иметь наибольший вес.
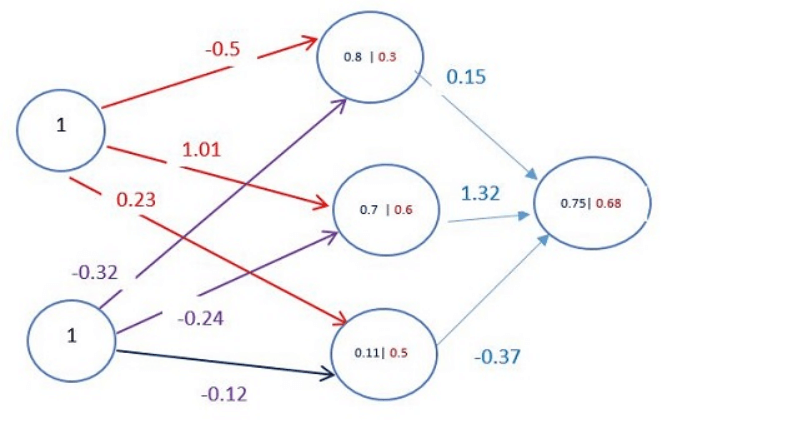
Каждый нейрон имеет функцию активации. Понять эту функцию можно путём математических рассуждений, но говоря простым языком, одна из её целей — «откалибровать» выходные данные от нейронов. Как только набор данных прошёл через все слои нейронной сети, она выводит ответ через выходной слой.
Тренировка нейросети
Тренировка ИИ — самая сложная часть глубокого обучения, потому что:
- требует обширных наборов данных;
- требует высоких вычислительных мощностей.
В примере с системой расчёта стоимости билетов необходимо найти архивы данных о стоимости билетов. А с учётом множества возможных комбинаций пунктов отправления и назначения, потребуется весьма немалый список цен на билеты.
Для тренировки ИИ в систему нужно ввести входные данные из массива, а потом сравнить её выходные данные с выходными данными из массива. Так как система ещё не обучена, её ответы будут содержать много ошибок.
Когда через нейросеть прошёл весь массив данных, можно составить функцию, которая покажет, насколько выход ИИ расходился с реальными выходными данными. Эта функция имеет название «функция потерь». Теоретически, это значение функции должно стремиться к нулю, то есть ответ ИИ должен полностью соответствовать имеющимся выходным данным массива.
Как уменьшить функцию потерь
Чтобы уменьшить функцию потерь, нужно по-другому расставить коэффициенты веса связей между нейронами. Менять в произвольном порядке, пока не будет достигнут нужный результат, достаточно неэффективно, и вместо этого используется метод градиентного спуска.
Градиентный спуск — метод, который позволяет находить минимальное значение функций, в данном случае — минимальное значение функции потерь. В этом методе вес понемногу изменяется после каждого прохождения набора данных через нейросеть. Подсчитав производную, или градиент, функции потерь при заданном распределении весов, можно вычислить, в какой точке находится наименьшее значение функции.
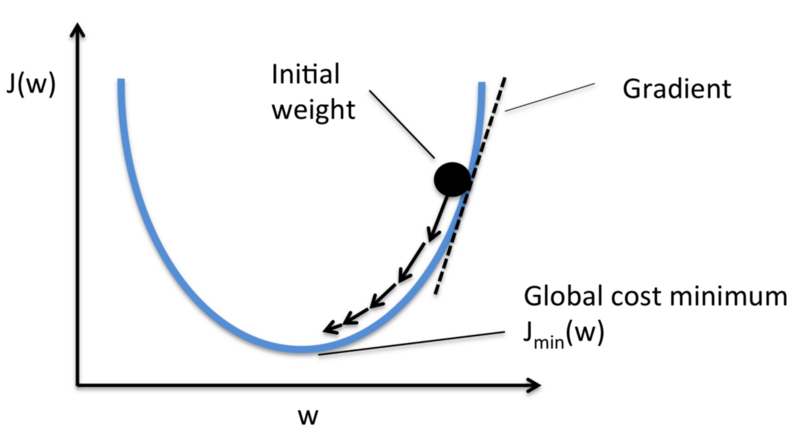
Чтобы минимизировать функцию потерь, массив данных нужно «прогнать» через нейросеть большое количество раз. Именно поэтому обучение ИИ требует огромных вычислительных мощностей. Но при использовании метода градиентного спуска корректировка весов нейронных связей происходит автоматически.
Где можно узнать больше
Существует много других типов нейронных сетей, например, свёрточные нейросети для машинного зрения и рекуррентные нейросети для обработки естественных языков. Технические аспекты глубокого обучения подробно освещают различные онлайн-курсы. Например, подобный курс недавно запустил Google.
Резюме
- Глубокое обучение использует нейронные сети для имитации интеллекта человека.
- У нейросетей есть три типа нейронных слоёв: входной, скрытый (или скрытые) и выходной слои.
- Связи между нейронами имеют вес, который характеризует их значимость во входных данных.
- Нейроны применяют функцию активации к данным, чтобы откалибровать выходные данные нейронов.
- Для обучения нейросетей требуются большие наборы данных.
- Повторный ввод набора данных и сравнение выходных данных позволяет вычислить функцию потерь, которая определяет, насколько результаты ИИ расходятся с теми, которые необходимо получить.
- После каждого прогона набора данных веса между нейронами корректируются с помощью метода градиентного спуска, что позволяет сократить функцию потерь.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.