Meta выпустила бесплатную модель, которая распознаёт 1600 языков
Компания представила самую масштабную систему распознавания речи в мире — Omnilingual ASR, способную понимать более 1600 языков, количество которых можно потенциально увеличить в разы.
Компания представила самую масштабную систему распознавания речи в мире — Omnilingual ASR, способную понимать более 1600 языков, количество которых можно потенциально увеличить в разы.

Компания представила самую масштабную систему распознавания речи в мире — Omnilingual ASR, способную понимать более 1600 языков, количество которых можно потенциально увеличить в разы.
Omnilingual ASR — это мультиязычная система автоматического распознавания речи (ASR), которая использует архитектуру с поддержкой zero-shot обучения. Это значит, что пользователи могут добавлять новые языки без переобучения модели, просто предоставив несколько примеров аудио и текста. Таким образом, технология охватывает почти все языки с письменной системой, включая сотни редких и исчезающих.
Meta открыла код и датасеты под лицензией Apache 2.0, позволив разработчикам использовать систему свободно, в том числе в коммерческих продуктах. Набор включает семейство моделей с числом параметров от 300 миллионов до 7 миллиардов, корпус речи более чем на 350 языках и инструменты для интеграции через PyPI и Hugging Face.
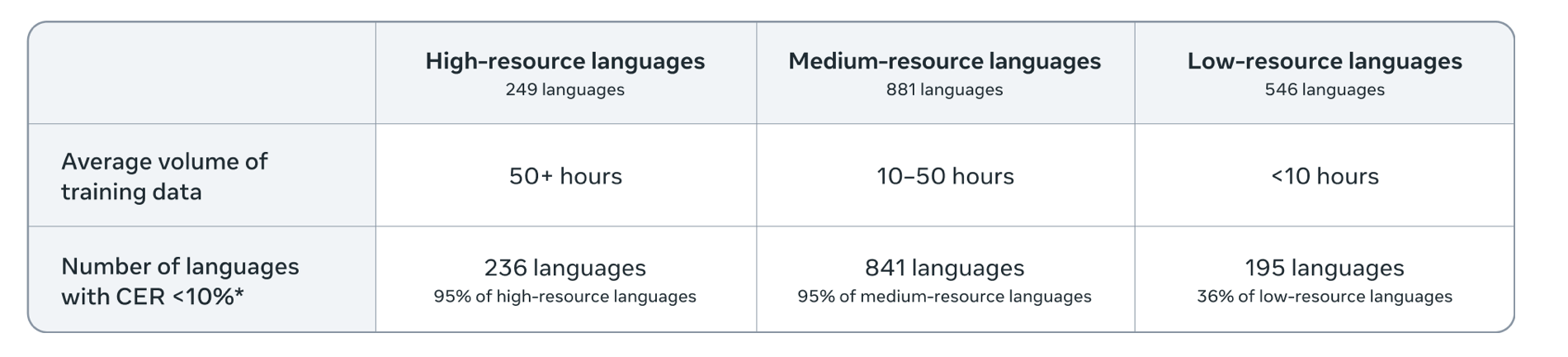
Компания отмечает, что Omnilingual ASR показывает уровень ошибок менее 10% в 78% поддерживаемых языков, включая 500, которые ранее не охватывались ни одной моделью. По словам команды Meta, цель проекта — «снять языковые барьеры и сделать цифровой доступ универсальным».
Релиз стал первым крупным открытым проектом после неудачного запуска Llama 4, вызвавшего критику за ограничительные лицензии и слабую адаптацию в бизнесе. Аналитики рассматривают новый шаг Meta как стратегическую перезагрузку и возвращение к философии открытого кода. Omnilingual ASR доступна бесплатно на GitHub и Hugging Face.








Релоцировались? Теперь вы можете комментировать без верификации аккаунта.