Microsoft обучила крупнейшую языковую модель на базе архитектуры Transformer
Подразделение Microsoft AI & Research представило, по его словам, крупнейшую в мире модель синтеза речи на основе нейронной архитектуры Transformer, сообщает VentureBeat.
Подразделение Microsoft AI & Research представило, по его словам, крупнейшую в мире модель синтеза речи на основе нейронной архитектуры Transformer, сообщает VentureBeat.
Подразделение Microsoft AI & Research представило, по его словам, крупнейшую в мире модель синтеза речи на основе нейронной архитектуры Transformer, сообщает VentureBeat.
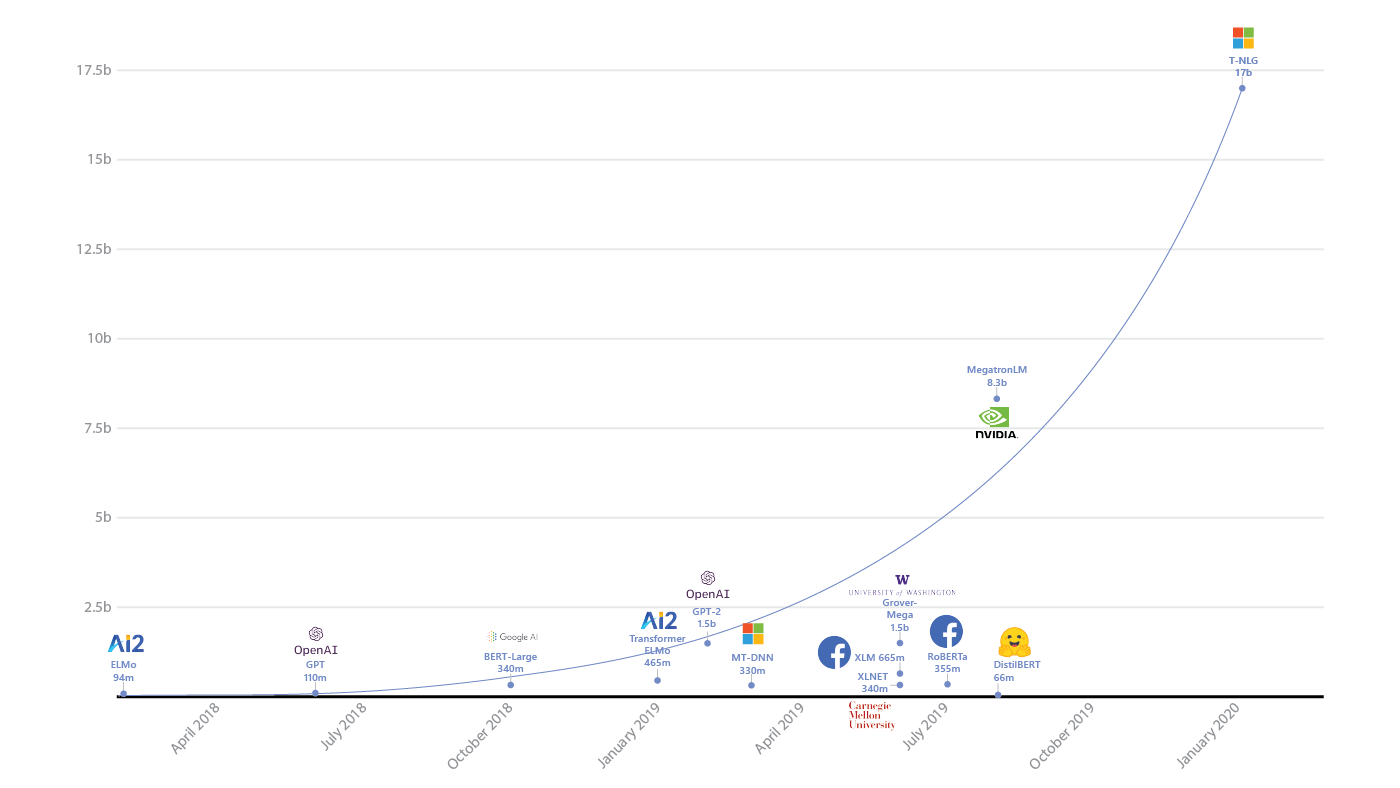
Модель под названием Turing NLG содержит 17 млрд параметров — в два раза больше, чем Megatron от Nvidia, которая теперь стала второй по величине нейросетью с этой архитектурой, и в 10 раз больше, чем генератор новостей GPT-2.
Подобные модели умеют, например, сочинять рассказы, генерировать ответы в виде сложных предложений и резюмировать тексты. Как и в случае с чат-ботом Google Meena или алгоритмом OpenAI, доступ к Turing NLG «на пробу» пока предоставили только небольшому кругу внешних исследователей.
Также разработчики Microsoft опубликовали библиотеку глубокого обучения DeepSpeed, которая упрощает распределенное обучение крупных нейросетей. Она поддерживает модели со 100 млрд или более параметров. Библиотека включает оптимизатор ZeRO для эффективного управления памятью при тренировке моделей и снижения расхода ресурсов. Оптимизатор использовался при обучении Turing NLG.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.