OpenAI: ИИ-модели не справляются с большинством реальных фриланс-задач на программирование
OpenAI создала новый бенчмарк SWE-Lancer, который демонстрирует возможности и ограничения ИИ-моделей в разработке софта. Многие задачи им под силу, однако со сложными софтверными проектами, которые требуют глубокого понимания и нетривиальных решений, они пока справляются не очень.
OpenAI создала новый бенчмарк SWE-Lancer, который демонстрирует возможности и ограничения ИИ-моделей в разработке софта. Многие задачи им под силу, однако со сложными софтверными проектами, которые требуют глубокого понимания и нетривиальных решений, они пока справляются не очень.
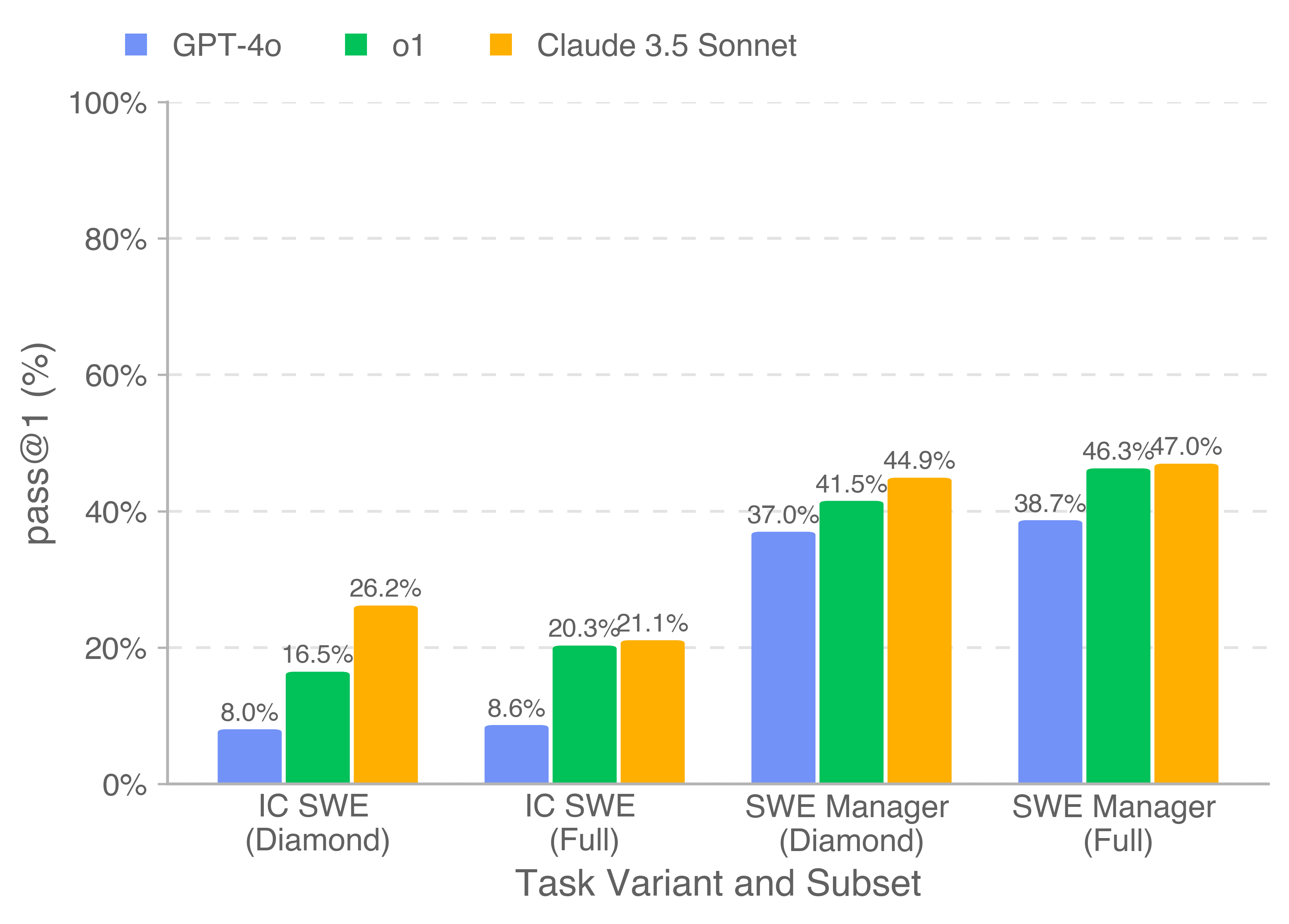
Бенчмарк включает 1400 реальных задач с Upwork в двух областях: собственно разработка и управление проектами. Если выполнить их все, можно заработать $1 млн.
Софтверные задачи варьировались от простых на исправление багов за $50 (например, на устранение лишних вызовов API) до реализации сложного функционала за $32 тысячи (например, создание кроссплатформенного функционала для воспроизведения видео для настольных, iOS-, Android- и веб-приложений). Также проверялось, насколько хорошо модели смогут оценить решения, предложенные живыми разработчиками.
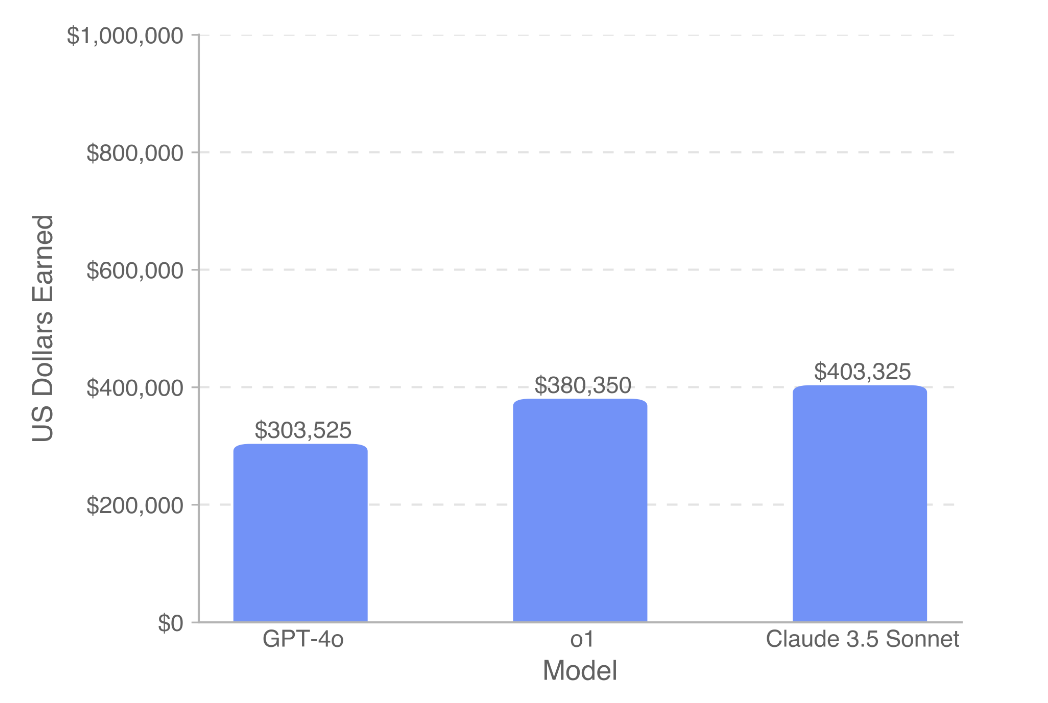
OpenAI испытывала три модели: GPT-4o, o1 и Claude 3.5 Sonnet. Лучший результат показала модель Anthropic — она выполнила 26,2% задач по программированию и 44,9% заданий, связанных с проджект-менеджментом. Это далеко от способностей человека, но всё равно многообещающе. По деньгам эта модель заработала $403 тысячи.
Бенчмарк выложен на GitHub. В своём релизе OpenAI отмечает, что измерение умения ИИ-моделей зарабатывать деньги позволит более детально исследовать их экономический эффект для общества.







Релоцировались? Теперь вы можете комментировать без верификации аккаунта.
Сама заработает, сама потратит.