Я занимаюсь разработкой RAG-приложения и в связи с этим уже некоторое время преисполняюсь изучением больших языковых моделей. Дабы не быть одиноко идущими к этой реке ИИ, собрались с коллегами на стрим обсудить опыт использования LLM на продакшене и актуальную ситуацию с технологией на рынке. Как раз тема немного начинает остывать, хайп устаканивается, и можно давать оценки.
Ко мне присоединились Сергей Щегрикович (СТО в ListAlpha), Вадим Ташликович (архитектор в Scand) и Валерий Селицкий (ML-энтузиаст и автор телеграм-бота Plotvobot).
Делюсь с вами выбранными отрывками нашего разговора. Посмотреть стрим полностью можно здесь.
Кто пишет: Антон Васильев, CTO компании On The Spot.
Традиционный дисклеймер: не претендуем ни на полноту обзора, ни на истину высшей инстанции.
Утерянные 600 млрд и пузырь на рынке LLM
Сергей Щегрикович:
— Sequoia Capital опубликовали новость о том, что инвесторы недосчитались 600 миллиардов прибыли от проектов, связанных с AI. Напрашивается вопрос: можем ли мы говорить о пузыре?
Вадим Ташликович:
— С моей точки зрения, все очень похоже на пузырь. Идёт гонка, кто быстрее сделает модель, у кого она будет мощнее. Поэтому инвесторы вливают очень большие деньги. Если мы посмотрим на «кривую хайпа» от Gartner, то увидим, что LLM и Generative AI уже миновали «пик завышенных ожиданий». Грубо говоря, инвесторы ожидали от AGI (Artificial General Intelligence) быстрой автоматизации, революции на рынке труда и скорого перехода к ASI (Artificial Super Intelligence), но этого не происходит.
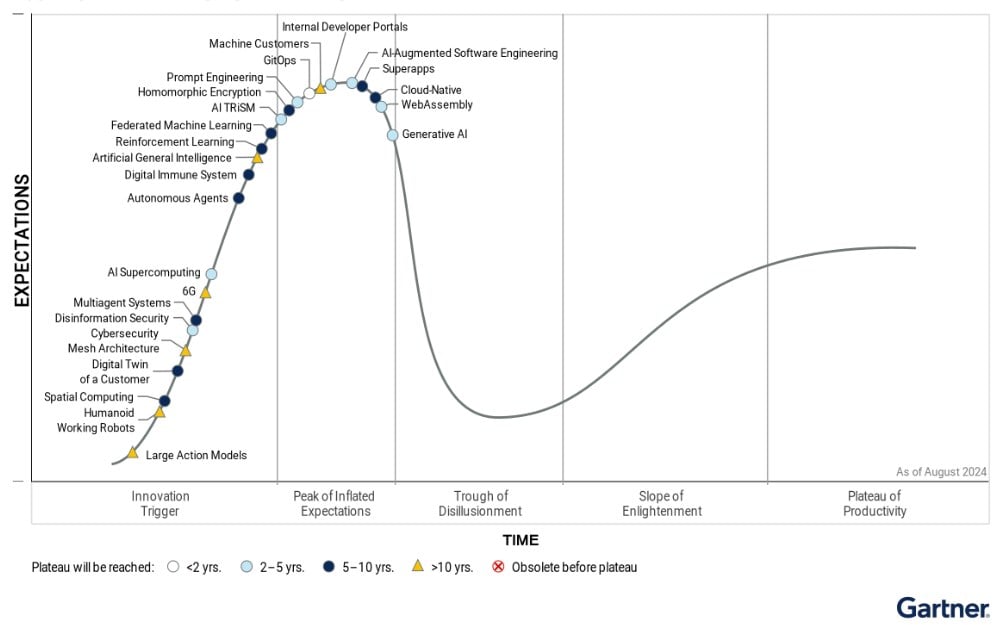
Валерий Селицкий:
— Чтобы этот рынок прогревался дальше, нужен очень крупный повод, которого пока на горизонте нет. Розовые очки спадают, и инвесторы уже ждут какого-то возврата своих инвестиций.
Сергей Щегрикович:
— Может быть, они просто рано ждут? Хайп появился 2,5 года назад, а цикл инвестирования — 5-7 лет. Настоящие продукты могут появиться только через год-два-три, когда все освоят возможности LLM и придумают use кейсы.
Кстати, о тех 600 миллиардах: я считаю, что эти огромные деньги — цена создания новой технологии. Financial Times сообщили, что технологические гиганты планируют вложить еще 100 миллиардов долларов в развитие дата-центров. Инвесторы не остановятся. LLМки уже вряд ли куда-то уйдут.
Как LLM стали частью повседневности разработчиков
Сергей Щегрикович:
— LLМки решают две основные проблемы:
- Разработка становится дешевле. Раньше, чтобы создать продукт, нам была нужна отдельная ML-команда. А сейчас мы можем использовать LLМку как black box ML-модель для всего, включая классификацию и регрессию.
- Любой человек может делать самую разную работу. Например, для создания email-рассылки больше не нужно нанимать маркетинг-специалиста — с этой работой хорошо справляются LLM.
Для вывода продукта на рынок теперь нужно намного меньше людей.
Валерий Селицкий:
— Они выполняют еще и социальную функцию. Моё хобби — делать интерактивного ИИ-бота для Telegram. Он умеет рисовать забавные картинки и ведёт остроумную беседу.
Во времена нескольких даунтаймов, когда я рефакторил код и технически обслуживал инфраструктуру бота, люди без иронии писали мне в личные сообщения, что им становится тревожно и беспокойно без него. То есть они реально снимают стресс, общаясь с Плотвой.
Антон Васильев:
— LLM значительно упрощают поиск информации. Я, например, использую Perplexity ежедневно. Так привык, что обращаюсь к нему даже чаще, чем к Google.
Реальный опыт на продакшене и проблемы
Антон Васильев:
— Я разрабатываю ассистента на базе LLM для фармацевтической индустрии. Задача –– анализировать документы на предмет их соответствия законодательству. Сетап: LlamaIndex, PgVector.
Казалось бы, тривиальная задача, но я столкнулся с несколькими проблемами.
- LLМка не пройдется по всем пунктам и не убедится, что учла все нюансы законодательства. Поэтому нельзя просто «скормить» большой массив текста в модель. Или поделить текст на маленькие кусочки и задавать вопросы по очереди — тогда надо строить внутри приложения дерево решений (модель, в которой в зависимости от предыдущего решения применяются другие правила). Это не идеальный выход, потому что попахивает графом с циклами, кучей зависимостей, опций.
- Работу за ИИ всё равно должен перепроверять человек.
- LLМки не так активно внедряются в менее технологичных сферах.
Но есть и то, что меня порадовало в процессе работы:
- Готовые фреймворки и инструменты, которые упрощают разработку ассистента, избавляя от необходимости работать с «голым» API.
- Ollama, которую можно локальненько развернуть и генерить на ней эмбединги.
Вадим Ташликович:
— Опишу 3 кейса, когда при работе над проектом моя команда использовала LLM.
Кейс 1. Автоматизировали обработку запросов на естественном языке к сервису. Нужно было определить, место, время пользователя и какие сервисы ему понадобятся.
На базе этих данных искали гида, который может оказать услуги в нужной локации — и использовали LLM, чтобы извлечь информацию из текстового запроса и найти подходящих и свободных гидов. Использовали семантический поиск на базе embeddings. Использовалась text embedding модель от OpenAI, а также GPT3.5 по API.
Кейс 2. Читаем все сообщения из группового чата, извлекаем необходимую информацию в формате JSON (с помощью LLM) и сохраняем в базе данных для поиска. Нужно за сутки обрабатывать от 3-х до 5-и тысяч сообщений. И это дорого, если использовать OpenAI GPT3.5/4 или Anthropic Claude 3-й версии. Предложили приобрести видеокарту RTX 3090 она может обрабатывать около 20 токенов в секунду для открытой модели Llama 3 8B. Сейчас бы попробовали использовать Groq с Llama 3.1 8B — дешевле в 80 раз. Цену можете посмотреть здесь.
Кейс 3. Делали классический чат-бот для ответов по набору приватных документов. Довольно пристально выбирали модель (из-за особенностей оборудования). Выбор пал на модель Mistral 7B. Для text embedding была выбрана модель gte-large.
Сергей Щегрикович:
— Недавно в Business Insider писали: бигфарм компания отказалась от использования Copilot для своих 500 сотрудников, потому что «много денег, мало value». Для меня это непонятно, ведь Microsoft предоставили крутое технологическое решение.
Очень круто, что Copilot умеет работать и с обычным языком, и с языками программирования. А ещё можно создавать новые
Copilot не просто создает текст, а как бы «программирует» изменения в презентациях, переводя запросы пользователей на специальный промежуточный язык, который разработала Microsoft. Этот язык легко проверять. Copilot умеет работать как с обычным человеческим языком, так и с языками программирования, что является одной из его крутых возможностей. Microsoft помогает создать своих собственных «копайлот-ассистентов». Для этого нужно разработать язык, который подходит для вашей задачи, создать много примеров для настройки, а затем объединить их. В итоге получится система, которая хорошо отвечает на вопросы пользователей. Это круто, потому что теперь LLM могут использоваться в задачах, где нужно планирование, хотя они изначально не были для этого созданы.
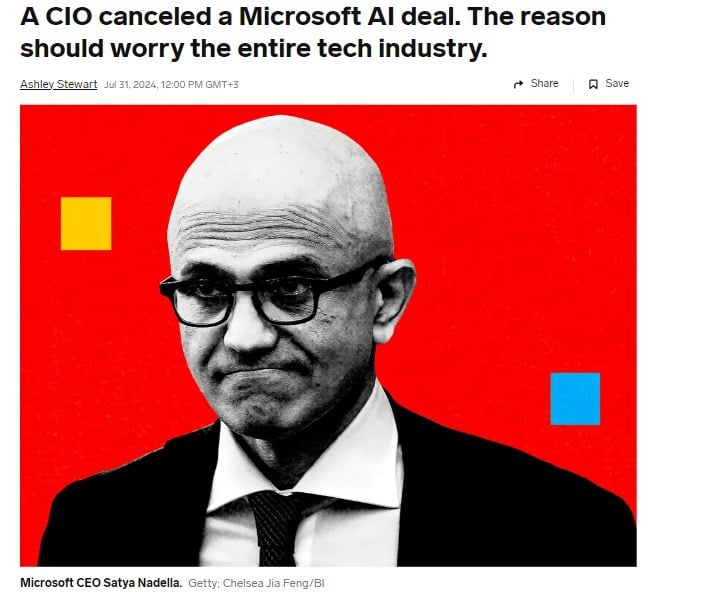
Антон Васильев:
— Возникает вопрос с use кейсом. То есть, Copilot и вообще любой чат-бот предлагается просто как «прикольный» инструмент. Но нет четкого понимания, как его использовать.
Новая технология должна быть настолько привлекательной, чтобы затмить страх перед ней и расходы на ее внедрение. Но когда ты даешь чат, ты не даешь use кейса. Разработчики говорят: «Вот вам технология, а как ей пользоваться, вы разберитесь сами».
И чат-боты не скейлятся, появляются проблемы с монетизацией. Например, пару недель назад вышла новость, что фаундеры стартапа Character AI возвращаются обратно в Google.
Куда движемся дальше? Агентные системы, AI-in-the-middle.
Вадим Ташликович:
— Первоначально задача LLM — быстро выдавать ответы, используя свою внутреннюю базу знаний. Они ограничены заданным контекстом и не могут принимать самостоятельные решения, а только предсказывают следующее слово.
AI-агенты, созданные для LLM, расширяют их возможности, позволяют моделировать диалоги с собой в разных ролях. Вести внутренние рассуждения, анализировать различные варианты ответов и выбирать оптимальный. Microsoft со своим Copilot Workspace собираются зайти ещё дальше. Судя по демоверсии, система сначала структурирует задачу, потом останавливается и предлагает человеку её дополнить или подкорректировать. А потом шаг за шагом генерирует код.
Сергей Щегрикович:
— Проблема в том, что человек всё равно должен проверять работу, которую делает искусственный интеллект. Чтобы лучше проверять планы, созданные, например, Copilot, нужен формальный язык, который ясно описывает задачи и их результаты.
Если такой язык появится, проверка будет работать хорошо, а если нет, то ничего не выйдет. И нужно, чтобы изменился UI — всем процессом должен руководить ИИ. В этом направлении уже двигается Perplexity со своими Pages и Anthropic с артефактами.
Говоря о перспективах: в этом году Ян Лекун (Chief AI Scientist в Meta) посоветовал студентам, которые планируют заниматься AI следующего поколения, не идти в компании, исключительно работающие с LLM. Лучше рассмотреть направления, которые не сталкиваются с ограничениями языковых моделей.
Что ещё почитать и что посмотреть, чтобы быть в курсе ИИ-темы?
- 31-страничный доклад Goldman Sachs на тему Gen AI, исследует, насколько оправданы огромные инвестиций в ИИ.
- Интересная статья о том, когда нужно и когда не нужно использовать LLM
- Promptfoo — инструмент для тестирования безопасности и надежности больших языковых моделей.
- LM Studio — программный инструмент для локального запуска больших языковых моделей.
- Aider — для парного программирования с искусственным интеллектом.
- Vast.ai — платформа для аренды графических процессоров для облачных вычислений.
- Канал с новостями по AI/LLM.
- Ежедневная рассылка по AI/LLM — с новостями, инсайтами, анализом и новыми продуктами.
Поделитесь, кого читаете и что слушаете по теме вы?
Релоцировались? Теперь вы можете комментировать без верификации аккаунта.
будущее LLM - классика, кто знает для чего это и как пользоваться, тому это поможет, кто не знает, тому разумеется не поможет. Разумеется, в ближайшие 5 лет будет развит зоопарк сервисов и продуктов массового пользования которые базируются на ЛЛМ.
Это если не случится больше никаких прорывов. В этом году должен подъехать GPT-5. Anthropic тоже планирует серьезное обновление. Они обновили свою среднюю модель - та стала сильно лучше, побила GPT-4 и стала лидером среди LLM. Сейчас работают над обновлением большой модели. Правда, прошел слух, что GPT-5 будет иметь всего в 2 раза больше параметров, чем GPT-4. Раньше они увеличивали циферку с ростом параметров на порядок.
В мире генерации картинок и видео сейчас какое-то безумие в хорошем смысле. Эти технологии прямо сильно продвинулись за этот год. Вот, например https://www.reddit.com/r/FluxAI/comments/1f71b7w/a_weird_90s/ Это сгенерено на домашней видеокарте опенсорсной моделью Flux. Или вот примеры видео: https://www.youtube.com/watch?v=qR6htTXgsiE&t=422s Там в начале нарезка промптов и результатов. Впечатляет. Год назад такого не было и близко.
Гугл пару недель назад показал Дум, который полностью генерируется нейронкой https://www.youtube.com/watch?v=SBdDt4BUIW0 Там нет движка, человек жмет кнопки, а сетка генерит 20 картинок в секунду так, что это трудно отличить от реальной игры.
В общем, там что-то куда-то стремительно развивается. Все еще. Рано говорить о застое и подводить итоги.
Пользователь отредактировал комментарий 05 сентября 2024, 16:41
интересно какие продвижения с САПР, эта тема вскольз только упоминалась.
В генерации 3D моделей примерно тот же прогресс, что и в 2D. Особенно в анимациях. Но в случае с САПР нужна высокая точность и соответствие спецификации. С этим, насколько я знаю, пока сложно. Существующие diffusion модели генерят довольно хаотичные результаты.
Статья понравилась, но видно, что AI у каждого героя решает довольно маленькие проблемы. В основном, векторный поиск по документам. Это нормально для каких-то задач, где нечеткий поиск всех устраивает, но, например, "анализировать документы на предмет их соответствия законодательству" такому решению доверять вряд ли стоит
Хороший материал. Спасибо.