В своей карьере программисты пишут много кода: для работодателей, для собственных проектов, а также для других разработчиков (помогая им обучаться).
Код для заказчиков пишется в IDE или текстовых редакторах, а для других разработчиков — на сайтах, в чатах и на StackOverflow.
Однако сейчас этот популярный ресурс находится под серьёзной угрозой. Расскажу, почему так важно, чтобы разработчики его сохранили.
Кто пишет: Миша Ларченко, tech-lead, живёт в Нидерландах. Ведёт блог на YouTube.
Убьют ли нейросети StackOverflow?
В последнее время у StackOverflow начались серьёзные проблемы. Главным предвестником беды стали нейросети, особенно ChatGPT. За последние 6 месяцев популярность сервиса снизилась на 25%.
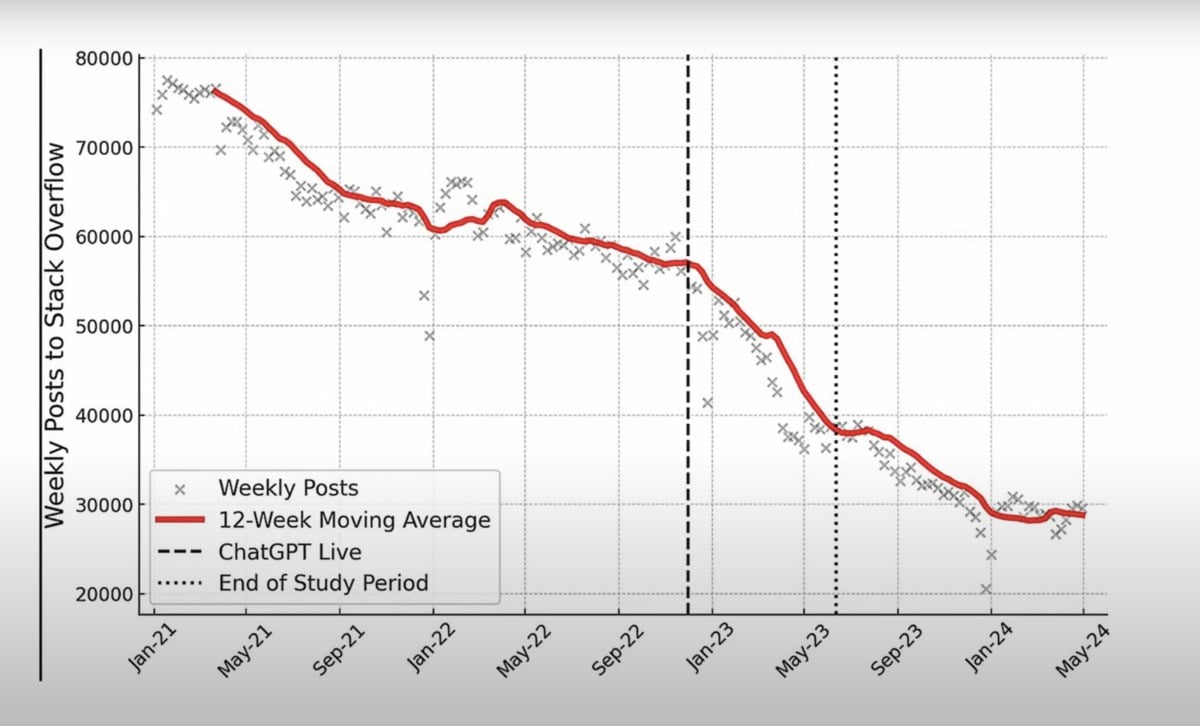
Вот исправленный вариант текста:
Некоторое время назад StackOverflow, чтобы остаться на плаву, разрешил OpenAI (за деньги) использовать код, написанный другими разработчиками на платформе, для обучения своих моделей. В ответ программисты начали удалять свои посты. Им не нравилось, что их бесплатный код будет продан другой компании.
Сейчас всё больше разработчиков задают вопросы ChatGPT, а не StackOverflow. Спрашиваешь, что тебя интересует — и сразу получаешь готовый код.
Особенно мало вопросов на сервисе задают по Python и JavaScript. Эти популярные языки программирования имеют большое количество кода в открытом доступе, на котором обучался ChatGPT. Поэтому нейросети могут решить практически любую задачу, связанную с этими языками.
О других языках программирования ChatGPT знает меньше, поэтому пользователям приходится гуглить. И они всё же возвращаются на StackOverflow.
Почему StackOverflow так важен
Не только потому, что там что-то спросить и получить ответ. StackOverflow — это ещё и огромная база кода. Если верить мемам, каждый проект в интернете так или иначе держится на коде индийского разработчика со StackOverflow. В этой шутке определённо есть доля истины.

Мы ещё далеки от создания действительно умных нейросетей, способных самостоятельно развиваться. Чтобы нейросети могли обучаться, они должны постоянно получать новую информацию. Но где её взять, если многие сайты запретили использование своих данных для обучения? Если новый код перестанет появляться на StackOverflow и аналогичных платформах, то нейросетям просто неоткуда будет черпать знания, и их развитие замедлится.
Чем чаще разработчики задают вопросы в соцсетях, а не на публичных платформах, тем меньше возможностей у начинающих программистов учиться на их ответах. Это ухудшает обмен знаниями в сообществе.
***
А как вы считаете, убьют ли нейросети StackOverflow? Пишите в комментариях.
Мнение автора может не отражать позицию редакции.
Что ещё почитать у комьюнити о работе:
- «Кузнечик» или плохой специалист? Tech lead делится мнением о тех, кто часто меняет работу;
- Как руководить, если ты «метр с кепкой»;
- Как сделать техническую презентацию ёмкой и понятной: практические советы тем, кто планирует выступать публично.
Релоцировались? Теперь вы можете комментировать без верификации аккаунта.
StackOverflow - токсичное комюнити отчасти поэтому и теряет публичный интерес.
шта?
Ну там за тупые вопросы могут и в гугл послать. Снежинкам не нравится.
что ж такое надо было там искать, чтобы увидеть токсичность?
Может с помершим Твиттером перепутал?
Попробуй позадавать вопросы... обязательно прилетит какой-нить чудак и начнет что то предъявлять, даунвойтить... это даже при том что другой человек уже ответил на вопрос... это примерно как фаундеры второсортных opensource ... открываешь им issue что checkmarx выдает критикал секьюрити проблему... даешь ссылку на репорт с описание проблемы, а они тупо игнорят и пишут какую-то саркастичную хрень..
За 15+ лет спросил пару раз ... пошли они н%й ...я лучше с ChatGPT общаться буду)
Ну понятно. Пошла аналитика по трубам. Не нейросети его убъют. Просто все уже пережевали. Растоманы так те сами себя сожрали, что ожидаемо.
Помрёт и помрёт, никто и не заметит.
Судя по графику, проблемы начались задолго до массового использования chatGPT
Я как-то пробовал активно отвечать там на вопросы. Оказалось, это очень затратное по времени хобби. И стрессовое: пишешь пару часов ответ с примерами, ссылками и диаграмами, а кто-то на 3 минуты раньше тебя постит и требует, чтобы ты свой удалил. Там выше писали про токсичное комьютити - это как раз оно.
И если когда-то давно мне казалось, что профиль StackOverflow с большой кармой (10к+) имел ценность для рекрутеров и работадателей, со временем мне перестало так казаться. Я уже давно не слышал, чтобы кто-то это обсуждал как плюс в резюме. Или рекрутер кого-то нашел по его StackOverflow профилю. Могу понять, почему популярность этого ресурса упала с появлением чего-то более простого и удобного.
Просто посылаешь лесом, или игнорируешь ¯\_(ツ)_/¯
Никогда не имел ценности.
Пользователь отредактировал комментарий 05 октября 2024, 00:49
никогда не говори «никогда»
Я собесился на проект работая на аутсорсера. Все прошло хорошо, но ребята попросили какие-то референсы в паблике, может сслыки на технические статьи в блоге или что-нить подобное. У меня было несколько специфичных вопросов, заданных на stackoverflow. Плюс пару хороших ответов. Я это и использовал как референсы.
не пишите пару часов ответ с примерами
Самые сочные bounty доставались именно за такие ответы
В своё время stack overflow обанкротил паблишеров трэш книг о программировании. Кто-то по ним скучает? Ну так и о самом SO скучать не будут когда он станет read-only как Лурк.
У них была куча проблем когда никаким gpt и не пахло. Они не могли привлечь достаточно новых контрибьюторов уже лет 10 назад, и никак не пытались бороться с biases пользователей, начиная с самых простых: отличный ответ от новичка не получает upvotes, зато любой трэш от условного JonSkeet сразу вылезет наверх (люди с высокой кармой по приколу заводили вторые аккаунты, и прокачать их было уже невозможно).
Пользователь отредактировал комментарий 05 октября 2024, 03:05
А как же "Искусство программирования BIOS" ?
странное сравнение тех. Q&A с помоечным сайтом (лурк), авторы которого как раз выдавали чужие статьи с других ресурсов за свои (пересыпая матерком).
Хочу отметить, что доля правды в этом есть. Я сейчас меняю работу, но уже так отвык делать некоторые базовые вещи, которые раньше были на автомате, что на лайвкодинг-сессии чувствую себя очень дискомфортно. А их, мать его, воткнули все, вообще все компании. А особо изощренные ребята ещё и напихали перед этим ассессментов с извращенными трекерами видео и аудио. Пишешь код и тебя записывают. А потом оно проверяет - пользовался ты там чем-то левым или нет. И знаете, чем я щас занимаюсь в 4 часа ночи? Херачю код для того, чтобы сдать ассессмент по RAG на одном из курсов NVIDIA. Потому что такой вот кризис. Хорошо, что книжками успел закупиться. Ну да ничего, не в первый раз. Но жёстко, прям жёстко.
Что там за ассесмент по RAG? Скормить функцию в llm и написать колбек? Там у OpenAI новая апишка вышла, где RAG как-то встроен в voice-to-voice модель. Вот там прямо дофига кода нужно нагородить, чтобы это заработало. Возможно, скоро и остальные перейдут от простых запросов к стриму через вебсокеты и полной асинхрощине. И gen-AI инженерам придется начать напрягаться. А лайкодинг - да, это прямо в 100% случаев теперь. Да еще хорошо, если удастся leetcode medium задачей отделаться
Пользователь отредактировал комментарий 05 октября 2024, 05:51
Да это просто на эмоциях. После того как немного выхватил на одном собесе за кодинг. Час сначала по теории собеседовали, а потом сразу же - час лайфкодинга без остановки. Короче, я троху занегативил после такого интима и решил сходить куда-то пописать агенты. Нашёл у NVIDIA временно бесплатный курс и вроде как с сертификатом даже, если верить табличке.
https://learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+S-FX-15+V1
Ну и там энв, с которым работаешь: ограничен по времени и поднимается долго, если отрубишь. Видосы посмотрел, мелочевку порешал, а в конце ассессмент. И блин версии либов совсем не те, к которым привык. Время на энв заканчивается, жаба душит (нахаляву же) и в азарт какой-то вошёл.
Кстати, завтра Meta Hacker Cup 2024. Если дойти до третьего раунда, то позовут на собес. Там как раз скоро можно на h1b подаваться. Там не сильно просто, но и не невозможно
А в чем проблема с лайвкодингом? Мне наоборот нравится. Просто берешь и демонстрируешь наглядно свой скилл (если конечно он есть), сильно лучше всяких разговоров о высоком.
И с другой стороны баррикад тоже отлично работает, когда интервьюируешь. Единственный известный мне способ обнаружить косноязычных но талантливых и работящих, лучше тысячи слов.
Очень многие не могут писать когда на них смотрят.
Pun intended.
Проблема СО в том что найти что-то сложное почти невозможно. Гугловый поиск работает очень плохо по таким запросам а гпт даёт хотя бы маленький шанс.
доля правильных ответов у гпт в целом около 40%, а если брать сложные технические вопросы - стремится к нулю
GPT учится на данных со stackoverflow, убивая его. Наш ждёт очень интересное будущее айтишки - когда все готовы писать средний код с помощью AI, но написание действительно качественного кода возможно исключительно при наличии многолетнего опыта, который никогда не появится в датасетах для обучения GenAI. Потому что все платформы обмена опытом убиты GenAI.
Пользователь отредактировал комментарий 05 октября 2024, 19:47
Наверное, не только в айтишке так будет, а вообще повсеместно. Придём на новый виток мануфактур и мастеров с подмастерьями.
Думаю, что не так уж всё и плохо. Появится новый рынок. По торговле кодовой базой "невыстреливших" продуктов. То есть, если стартап не выстрелил, его можно будет продать на "утилизацию" дилерам данных, которые его встроят в датасет для обучения LLM. И чем больше будут деградировать площадки вроде Stackoverflow, тем больше будет расширяться этот рынок и расти цена на выкуп кодовой базы. А это со своей стороны будет снижать риски и расширять для стартаперов, ибо код всегда можно будет продать хотя бы таким способом. Да и большие компании постоянно экспериментируют и их graveyard проектов уже сейчас являются в этом плане способом извлечения выгоды. Это win-win стратегия для всех участников процесса. Сколько сейчас таких проектов, которые как чемодан без ручки? Написаны, с любовью и старанием, но просто не попали в аудиторию. Думаю, что тысячи и тысячи. На толпу выкладывать жалко, а поддерживать и развивать - коммерчески невыгодно.
Пользователь отредактировал комментарий 06 октября 2024, 14:22
Да и не факт, что будующим нейронкам нужно так уж много нового кода. Возможно, они уже знаю достаточно, просто не хватает общей логики, чтобы решать сложные проблемы. Та же О1 модель лучше решает задачи, если дать ей больше попыток. У обычных моделей такого способа скейлиться нет. По сути chain of thoughts дает возможности улучшать reasoning в рантайме. И это работает, если почитать их отчет. При 50 сабмитах она набрала всего 11% на олимпиаде по программированию, а с увеличинем попыток до 10 000 результат стал 93%. В общем, пока все за нехватку данных переживают, они там ищут новые способы заставить логику скейлиться. И вроде даже находят.
То есть перебором с 50 попыток до 10к процент правильных ответов вырос с 11% до 93%?
Похоже на генератор случайных ответов.
Соревнования (международная олимпиада по информатике 2024) выглядели так: 6 проблем, 10 часов на все, на каждую проблему можно сабмитить до 50 решений. В зачет идет решение, набирающее больше всего очков. Для каждой проблемы есть открытый список тест кейсов, на котором можно тренироваться. При сабмите прогоняются закрытые тесты, которые не известны. Известно только, сколько решение получает очков.
OpenAI взяли свою O1 модель, дополнительно как-то дообучили на кодинг и запустили на 10 часов. Сначала модель генерила решения, выбирала из них 50 случайных и сабмитила. Такой подход дал 156 условных очков. Затем ей дали возможность прогонять на своих решениях открытые тесты, плюс писать собственные. Сабмитились лучшие 50 решений по итогам тестов - это дало 213 очков (лучше 49% участников). Когда количество сабмитов увеличили до 10 000, модель набрала 362 очка - это уровень золотой медали. Конечно, это читерство с точки зрения кожаных мешков. С другой стороны, людям увеличение количества сабмитов не дает таких уж больших преимуществ. Если не знаешь, как решить сложную задачу, просто наугад на решишь, сколько не сабмить. Да и там же не ответ нужен, а решение в виде кода. Прошлые модели, которые не могут "думать", а просто генерят решения за 1 проход, тоже не сильно умнеют с количеством попыток. Какой-то фитбек они получают после сабмитов, но без возможности итерироваться и обсуждать внутри себя проблему их результат очень низкий.
Затем эту модель и другие отправили решать coding challenge на платформе Codeforces, там всех ограничили 10 сабмитами. Результаты были такие: GPT-4o - 11% (лучше 11% всех участников), O1-preview - 62%, O1 (которая не preview, она еще официально не вышла) - 89%, и та особая O1 из предыдущего абзаца, умеющая выбирал лучшие решения - 93%. Если бы ей еще больше сабмитов дали, она бы набрала 100.
Это все отсюда: https://openai.com/index/learning-to-reason-with-llms/
Там и другие соревнования, не только кодинг. Включая собеседование в OpenAI на позицию researcher.
Вообще, попробуйте дать чату GPT какое-нибудь уравнение с интегралами. Просто в виде картинки. Он в высокой долей вероятности решит. Может где-то в цифрах ошибется, но решение распишет, как надо. Это полчему-то мало кого впечатляет. А должно, по идее. Возможно, близок тот день, когда исследование отдадут такой вот модели, а не человеку, который много лет зубрил математику.
Пользователь отредактировал комментарий 07 октября 2024, 01:52
Спасибо за детали.
Методология действильно случайный перебор и увеличении попыток ожидаемо привело к росту метрик.
Не решит уравнение, а найдёт существующее решение.
Ну или даю бесценный совет подсунуть задачу тысячелетия и получить миллионный приз
хороший код и раньше не сильно выкладывали. Чтобы не выискивать потом клоны проектов.
Если OpenAI не будет выдавать код с синтаксисом из супер новой версии JS, я это переживу. Много ответов генерятся явно из документации, без воды
Разве не накопилась на сайте критическая масса ответов, после которой новые вопросы можно не задавать?
Новые фреймворки появляются, синтаксис, функции, примеры. Их то не появяться в новом сборе данных из-за упадка SO.
Выше уже писали чат боты и так скрейпят документацию и часто на ее основе дают ответы но при такой динамике зачем обертка из бота если я сам могу открыть документацию и найти ответ? Возможно упрощает как то поиск по плохо организованной документации.
Пока есть open source вряд ли ИИ что-то угрожает, а пока есть ИИ у новичков будут нужные им ответы.
новые ответы будут появляться на платформах, с которых нельзя тупо взять и украсть интеллектуальный труд.
Это каким образом? Все можно распарсить. Тем более с ИИ.
Уточню, безнаказанно украсть и выдать за своё без ссылки на первоисточник.
К сожалению пользователи многих платформ тупо подмахнули обновление пользовательского соглашения, что их контент будет использоваться для "обучения LLM" и подобное.
Но у Adobe, например, это не прокатило.
Я понимаю вашу мысль, но это абсолютно нереально. Это как в музыке старая история про 7 нот (или 12 не суть) и плагиат. Поди докажи. Тем более, когда мы имеем дело с чем-то, что способно очень хорошо вносить несущественные изменения для обхода проблем с правообладателем.
Пользователь отредактировал комментарий 27 октября 2024, 10:31
Это не только СтэкОверфлоу продал труды пользователей чатботам. Внимательно читайте пользовательские соглашения и, главное, обновления к ним.
Результат закономерен. Раньше участники зарабатывали имя и репутацию, сейчас даришь Сэму Альтману и Ко.