
Обработка естественного языка (Natural Language Processing, или NLP) — это направление в исследовании искусственного интеллекта, задача которого — обучить машину понимать и обрабатывать язык человека. Разработчик Адам Гитги опубликовал статью, в которой описал принципы NLP и рассказал о создании программы для извлечения информации и текста на языке программирования Python.
Компьютеры отлично умеют обрабатывать структурированные данные — например, электронные таблицы и базы данных. Однако люди общаются не таблицами, а с помощью слов. В основном информация в окружающем мире не структурирована и представляет собой необработанный текст на одном из естественных языков. Именно этот поток сырой информации компьютер должен научиться понимать, вычленяя из него значимые сведения.

Может ли компьютер понять человека
С момента появления компьютеров программисты пытаются научить их понимать «человеческие» языки. Люди изобрели письменность тысячи лет назад, и было бы очень удобно, если бы компьютер мог считать и проанализировать накопленную за этот период информацию.
Компьютеры пока что не способны воспринимать английский на уровне человека, но и уже достигнутые ими успехи действительно впечатляют. В отдельных областях технологии NLP позволяют сэкономить исследователям массу времени. Последние разработки в сфере обработки естественного языка свободно доступны в таких открытых библиотеках на Python, как spaCy, textacy и neuralcoref. С помощью нескольких строк кода можно буквально творить чудеса.
Извлечение смысла из текста — сложный процесс
Процесс чтения и понимания английского языка очень непрост, не говоря уже о том, что в нём нет жёстко упорядоченных и логичных норм. Например, вот эта фраза:
«Environmental regulators grill business owner over illegal coal fires»
В английском языке слово «grill» помимо прямого значения «жарить» имеет значение «допросить с пристрастием». Вызывает сомнение, в каком смысле — прямом или переносном — использовали его авторы заголовка. Понять, что именно сделали с бизнесменом органы охраны природы, компьютеру будет очень проблематично.
Чтобы выполнить задачи такой сложности с использованием машинного обучения (МО), обычно строится конвейер. Задача разбивается на несколько очень небольших частей, после чего модели МО решают каждую подпроблему по отдельности. Далее модели соединяются в конвейер, по которому обмениваются информацией, что даёт возможность решать задачи очень высокой сложности. Именно так происходит обработка естественных языков.
Пошаговое построение NLP-конвейера
Вот отрывок из статьи о Лондоне из Википедии:
«London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.»
В этом абзаце есть несколько содержательных фактов. Чтобы компьютер смог обнаружить их, прочитав текст, сначала нужно обучить его базовым принципам письменного языка.
Шаг 1: сегментация на предложения
В первую очередь необходимо разбить текст на отдельные предложения:
- London is the capital and most populous city of England and the United Kingdom.
- Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.
- It was founded by the Romans, who named it Londinium.
Можно допустить, что каждое предложение на английском несёт законченную мысль или идею. Гораздо проще написать программу для понимания одного предложения, чем всего абзаца сразу.
Разработать модель сегментации на предложения несложно: их границы обычно обозначены точками. Но современные NLP-конвейеры часто используют более прогрессивные методы, которые срабатывают даже на плохо отформатированных документах.
Шаг 2: лексический анализ
После разделения текста на предложения, нужно по очереди проанализировать их, начиная с первого:
«London is the capital and most populous city of England and the United Kingdom.»
Теперь необходимо разложить это предложение на отдельные слова, или лексемы. Этот процесс называется «лексическим анализом». Таким образом, получены элементы:
«London», «is», «the», «capital», «and», «most», «populous», «city», «of», «England», «and», «the», «United», «Kingdom», «.»
В естественных языках провести эту операцию тоже нетрудно: слова в предложении отделяются пробелами. Знаки препинания считаются отдельными единицами, так как тоже имеют смысл.
Шаг 3: частеречная разметка
Далее нужно попытаться определить, к какой части речи относится каждая из лексем: существительное, глагол, прилагательное и так далее. Знание того, какую роль то или иное слово выполняет в предложении, поможет прояснить значение предложения.
Это можно сделать, введя каждое из слов (а также несколько стоящих рядом слов, чтобы не вырывать его из контекста) в уже обученный классификатор по частям речи:

Изначально модель тренировалась на миллионах предложений на английском языке, в которых у каждого слова уже была обозначена часть речи, — она должна была научиться по аналогии выполнять эту операцию самостоятельно.
Такие модели опираются исключительно на статистику: они не воспринимают значение слов так, как это делают люди. Они просто угадывают части речи на основе схожих предложений и слов, которые они видели раньше.
Результаты, полученные после анализа всего предложения:

Эта информация позволяет понемногу восстановить смысл фраз. Очевидно, что в предложении присутствуют слова «London» и «capital» — модель может предположить, что речь идёт о Лондоне.
Шаг 4: лемматизация текста (определение начальной формы слов)
В английском, как и в большинстве языков, слова имеют несколько различных форм. Например:
I had a pony.
I had two ponies.
В обоих предложениях употребляется одно существительное «pony», но с разными окончаниями. При обработке текста компьютеру очень полезно знать исходные формы используемых слов, чтобы понимать, что в обоих предложениях речь идёт об одном и том же предмете. Иначе строки «pony» и «ponies» он воспримет как два не связанных между собой слова.
В NLP этот процесс определения начальной формы, или леммы, каждого слова в предложении имеет название «лемматизация».
То же делают и с глаголами. Их также можно лемматизировать, то есть выделить исходную, неспрягаемую форму. Поэтому, предложение «I had two ponies» можно представить как «I [have] two [pony]».
Определение лемм компьютер обычно выполняет по справочным таблицам форм слов, характерных для частей речи, и иногда — набора некоторых правил обработки незнакомых слов.
Вот так будет выглядеть предложение после лемматизации — выделения основной формы глагола:

Единственное изменение в том, что «is» превратилось в «be».
Шаг 5: выявление стоповых слов (слов, которые не несут самостоятельного смысла)
Далее нужно определить смысловую нагрузку слов в предложении. В английском языке присутствует большое число слов-заполнителей, таких как союзы и артикли («and», «the», «a»). При статистическом анализе текста эти слова создают много шума, потому что встречаются значительно чаще других слов. Некоторые NLP-конвейеры идентифицируют их как «стоповые слова», которые перед проведением анализа необходимо опустить. Вот как после этого будет выглядеть предложение:

Эти слова обычно просто проверяют по встроенному списку уже знакомых системе стоповых слов. Но универсального списка таких лишних слов, применимого для всех случаев, не существует: они могут различаться в зависимости от ситуации применения.
Например, при создании поискового движка рок-групп нужно, чтобы система не выбрасывала артикль «the», потому что он встречается во многих названиях. В 1980-х годах была даже группа под названием «The The!»
Шаг 6: синтаксический анализ на основе грамматики зависимостей
Теперь необходимо выяснить, как связаны друг с другом слова в предложении. Для этого проводят синтаксический анализ на основе грамматики (или дерева) зависимостей.
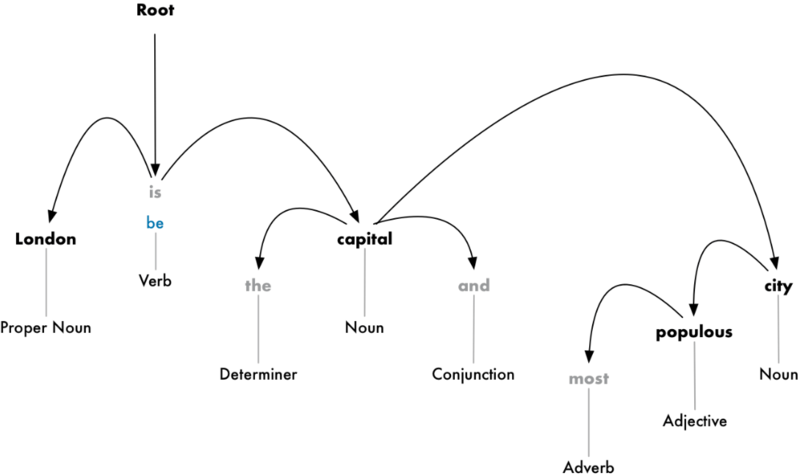
Цель — построить дерево, в котором к каждому слову соответствует одно непроизводное слово. Корень дерева — это ключевой глагол предложения. Вот так будет выглядеть дерево синтаксического анализа вначале:
Но можно пойти дальше: помимо подбора непроизводных слов, можно вычислить тип взаимосвязи между двумя словами в предложении:
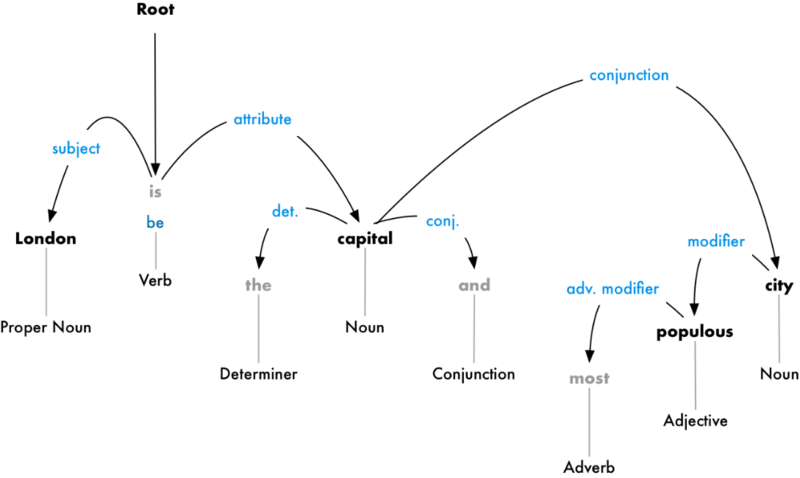
Из этого дерева видно, что подлежащим в предложении является слово «London», которое связано со словом «capital» через слово «be». Удалось выделить значимую информацию: Лондон — это столица. Продолжив анализ, можно выяснить, что Лондон является столицей Соединённого Королевства.
Аналогично тому, как выше модель МО угадывала, к какой части речи относятся слова, для парсинга зависимостей в модель вводят слова и получают некий результат на выходе. Анализ связей между словами — весьма трудоёмкая задача, подробного описания которой хватит на целую отдельную статью. Начать можно со статьи «Parsing English in 500 Lines of Python» Мэтью Хоннибала.
Хотя в 2015 году этот подход считался общепринятым, на сегодняшний день он уже устарел и больше не используется даже самим автором. В 2016 году Google выпустила новый анализатор зависимостей Parsey McParseface, превосходящий остальные инструменты благодаря новому подходу на основе глубокого обучения, который быстро набрал популярность в отрасли. Годом позже компания даже выпустила новую, ещё более совершенную модель ParseySaurus. Таким образом, технологии синтаксического анализа не стоят на месте и постоянно улучшаются.
Важно отметить, что многие предложения на английском языке могут толковаться двояко и нелегко поддаются анализу. В таких случаях модель просто делает предположение, исходя из того, какой вариант ей кажется более вероятным. Но этот способ имеет свои недостатки, так как иногда ответы моделей достаточно далеки от истины. На сайте spaCy можно запустить синтаксический анализ на основе дерева зависимостей для любого предложения.
Шаг 6.1: поиск именных групп
Пока что каждое слово в предложении рассматривалось обособленно от остальных. Но иногда гораздо полезнее группировать слова, которые передают единую мысль или понятие. Для автоматической группировки таких слов можно использовать результаты дерева синтаксического анализа.
Например, вместо
можно объединить именные группы:

Необходимость выполнения этого шага зависит от конечной цели исследования. Но часто это позволяет быстро и просто разложить предложение на части, если не требуется уточнять, к каким частям речи относятся слова, и вместо этого сосредоточиться на общей идее.
Шаг 7: выделение именованных сущностей (named entity recognition, NER)
После парсинга грамматики можно перейти к извлечению смысла текста. В предложении есть следующие имена существительные:

Некоторые из них обозначают объекты реального мира. Например, «London», «England» и «United Kingdom» — это географические названия конкретных мест на карте, которые модель должна уметь опознавать. Зная это, с помощью NLP можно автоматически сгенерировать список реальных мест, упомянутых в предложении.
Цель выделения именованных сущностей — найти эти существительные и маркировать по типу реальных объектов, с которыми они соотносятся, например, в рассматриваемом предложении — как «географические сущности». Вот так будет выглядеть предложение после того, как каждая лексема пройдёт через NER-модель:

Однако NER-системы не просто сверяются со словарём. Они используют контекст (окружение слова в предложении) а также статистическую модель, чтобы определить тип объекта, обозначаемого существительным. Качественные NER-системы с учётом контекста способны, например, отличить актрису Бруклин Деккер от района Бруклин в Нью-Йорке.
Системы выделения именованных сущностей могут присваивать им различные метки, например:
- имена людей
- названия компаний
- географические объекты (на физических и политических картах)
- наименования продуктов
- дата и время
- денежные суммы
- названия событий
NER-системы имеют множество применений, потому что позволяют запросто структурировать представленные в тексте данные при обработке естественных языков. Самостоятельно опробовать модели выделения именованных сущностей также можно на сайте spaCy.
Шаг 8: разрешение кореференции
На данном этапе уже получено много полезной информации о предложении: части речи каждого слова, взаимосвязи между словами и какие из них являются именами собственными.
Однако в естественных языках также присутствует множество местоимений. Они помогают сократить речь, заменяя повторяющиеся существительные. Человек понимает, к какому существительному относится то или иное местоимение из контекста. Но модель обработки естественного языка этого не знает, потому что исследует по одному предложению за раз.
Если проанализировать с помощью NLP-конвейера третье предложение в тексте:
«It was founded by the Romans, who named it Londinium»,
то система увидит, что «it» был основан римлянами. Но при этом ей необходимо понять, что римлянами был основан именно Лондон.
Когда предложение читает человек, он сразу понимает, что местоимение заменяет город. Цель разрешения кореференции — соотнести местоимения в тексте с существительными, на которые они указывают, и найти все местоимения, которые указывают на один и тот же предмет.
Вот результат этой операции для слова «Лондон» в рассмотренном тексте:

Если полученную информацию обобщить с деревом синтаксического анализа и данными об именованных сущностях, это значительно приблизит модель к пониманию смысла всего текста.
Разрешение кореференции — один из наисложнейших этапов всего процесса обработки естественного языка, даже сложнее, чем синтаксический анализ. Новейшие подходы в сфере глубокого обучения обеспечивают более высокую точность, но и они всё же имеют свои недостатки. Подробнее об этом можно прочитать здесь.
А более детально разобраться с разрешением кореференции можно на сайте Hugging Face.
Создание NLP-конвейера на Python
Вот так выглядит алгоритм обработки естественного языка:
входные данные: исходный текст
- сегментация на предложения
- лексический анализ
- частеречная разметка
- лемматизация текста
- выявление стоповых слов
- синтаксический анализ на основе грамматики зависимостей
- поиск именных групп
- выделение именованных сущностей
- разрешение кореференции
выходные данные: структуры данных проанализированного текста

Это базовая модель NLP-конвейера, но в зависимости от целей и способа применения NLP-библиотеки те или иные шаги можно пропускать или менять местами. Например, некоторые библиотеки вроде spaCy проводят сегментацию на предложения на более позднем этапе и используют результаты парсинга зависимостей.
Создать такой конвейер довольно просто, потому что всё необходимое уже реализовано в обширных Python-библиотеках. Например, в spaCy прописан код для каждого шага.
Для начала нужно установить Python 3, после чего установить spaCy с помощью следующего кода:
# Install spaCy pip3 install -U spacy # Download the large English model for spaCy python3 -m spacy download en_core_web_lg # Install textacy which will also be useful pip3 install -U textacy
Далее следует код для запуска NLP-конвейера на фрагменте текста:
import spacy
# Load the large English NLP model
nlp = spacy.load('en_core_web_lg')
# The text we want to examine
text = """London is the capital and most populous city of England and
the United Kingdom. Standing on the River Thames in the south east
of the island of Great Britain, London has been a major settlement
for two millennia. It was founded by the Romans, who named it Londinium.
"""
# Parse the text with spaCy. This runs the entire pipeline.
doc = nlp(text)
# 'doc' now contains a parsed version of text. We can use it to do anything we want!
# For example, this will print out all the named entities that were detected:
for entity in doc.ents:
print(f"{entity.text} ({entity.label_})")
При его выполнении отобразится список именованных сущностей, найденных в документе, и их типов:

Полный список сокращений с расшифровкой можно найти здесь.
Нужно отметить, что здесь модель допустила ошибку: «Лондиний» она интерпретировала как имя человека, а не географическое название. Это могло произойти потому, что в тренировочном наборе данных не было похожих слов, и модель просто выбрала наиболее вероятную догадку. Для выделения именованных сущностей иногда требуется немного преобразовать модель, если в тексте встречается редкая или специальная лексика.
Принцип выявления сущностей можно применить в создании инструмента для очистки данных. Многие компании хранят у себя тысячи документов с информацией, по которой можно установить личности их владельцев. Чтобы соответствовать требованиям нового регламента о защите данных GDPR, компаниям придётся удалить все имена из файлов.
Чтобы вручную просмотреть тысячи документов и скрыть все имена, могут уйти годы: намного рациональнее использовать NLP. Вот простой код, который удалит все найденные в документах имена людей:
import spacy
# Load the large English NLP model
nlp = spacy.load('en_core_web_lg')
# Replace a token with "REDACTED" if it is a name
def replace_name_with_placeholder(token):
if token.ent_iob != 0 and token.ent_type_ == "PERSON":
return "[REDACTED] "
else:
return token.string
# Loop through all the entities in a document and check if they are names
def scrub(text):
doc = nlp(text)
for ent in doc.ents:
ent.merge()
tokens = map(replace_name_with_placeholder, doc)
return "".join(tokens)
s = """
In 1950, Alan Turing published his famous article "Computing Machinery and Intelligence". In 1957, Noam Chomsky’s
Syntactic Structures revolutionized Linguistics with 'universal grammar', a rule based system of syntactic structures.
"""
print(scrub(s))
Вот как будет выглядеть обработанный текст:

Извлечение фактов
Базовый функционал spaCy позволяет делать удивительные вещи. Но проанализированные выходные данные можно далее использовать в более продвинутых алгоритмах извлечения данных. Несколько таких общих алгоритмов помимо spaCy содержит достойная Python-библиотека textacy.
В ней есть алгоритм извлечения полуструктурированных высказываний, который можно применять для поиска по дереву синтаксического анализа простых высказываний с подлежащим «London» и глаголом «be» в одной из форм. Это поможет найти факты о Лондоне.
Пример кода:
import spacy
import textacy.extract
# Load the large English NLP model
nlp = spacy.load('en_core_web_lg')
# The text we want to examine
text = """London is the capital and most populous city of England and the United Kingdom.
Standing on the River Thames in the south east of the island of Great Britain,
London has been a major settlement for two millennia. It was founded by the Romans,
who named it Londinium.
"""
# Parse the document with spaCy
doc = nlp(text)
# Extract semi-structured statements
statements = textacy.extract.semistructured_statements(doc, "London")
# Print the results
print("Here are the things I know about London:")
for statement in statements:
subject, verb, fact = statement
print(f" - {fact}")
На выходе алгоритм сообщит, что Лондон является столицей и самым населённым городом Англии и Соединённого Королевства, а также что его возраст — две тысячи лет:

На первый взгляд, в этом нет ничего особенного. Но если через этот код пропустить статью о Лондоне из Википедии полностью, а не только три предложения, можно получить гораздо более исчерпывающие результаты:

Весь этот объём информации извлекается из статьи автоматически.
Помимо этого, можно загрузить библиотеку neuralcoref и добавить в конвейер разрешение кореференции. Это позволит получить ещё больше фактов за счёт тех предложений, где вместо прямого упоминания Лондона используются местоимения.
Дополнительные возможности NLP
В документации spaCy и textacy есть большое число примеров использования парсированного текста: в этой статье рассмотрен лишь малая доля возможностей библиотек. На их основе можно разработать сайт, который будет содержать информацию о любом городе мира, полученную описанным в последнем примере способом. Если бы в этом сайте был поиск, в него можно было бы добавить функцию автодополнения запросов, как у Google:
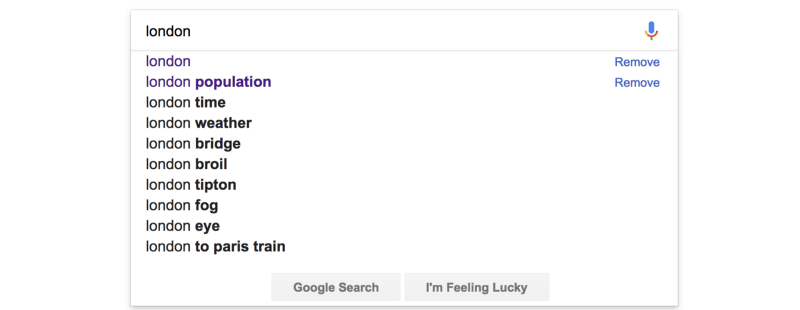
Для этого понадобится список возможных дополнений, которые будут предлагаться пользователю. Чтобы быстро сгенерировать эти данные, можно использовать NLP.
Вот один из способов извлечь самые частотные отрывки фраз из текста о Лондоне:
import spacy
import textacy.extract
# Load the large English NLP model
nlp = spacy.load('en_core_web_lg')
# The text we want to examine
text = """London is [.. shortened for space ..]"""
# Parse the document with spaCy
doc = nlp(text)
# Extract noun chunks that appear
noun_chunks = textacy.extract.noun_chunks(doc, min_freq=3)
# Convert noun chunks to lowercase strings
noun_chunks = map(str, noun_chunks)
noun_chunks = map(str.lower, noun_chunks)
# Print out any nouns that are at least 2 words long
for noun_chunk in set(noun_chunks):
if len(noun_chunk.split(" ")) > 1:
print(noun_chunk)
Если запустить этот код на статье о Лондоне из Википедии, результат будет таким:

Это далеко не всё, для чего можно использовать NLP. Но прежде чем углубляться в более сложные системы, стоит изучить spaCy или другие библиотеки на других языках, потому что все они имеют схожий принцип работы.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.