
Невозможно не восхищаться машинным обучением. Машины невероятно мощны. Даже Стив Балмер считает, что машинное обучение станет новой эрой вычислительной техники. В наши дни этот феномен окружён многочисленными слухами. Ману Дживан (Manu Jeevan) предлагает обзор основных концепций машинного обучения. dev.by публикует перевод его статьи.

Методы ансамблей (коллективные методы)
Классно, когда владеешь этими методами. Дерево принятия решений работает не очень хорошо, но очень быстро.
Методы ансамблей — это алгоритмы обучения, которые строят ряд классификаторов и затем классифицируют новые точки данных, суммируя результаты их предсказаний. В этой статье я буду говорить о некоторых популярных методах, например, бэггинге, бустинге и случайных лесах.
Если бы меня попросили рассказать про методы ансамблей одним предложением, я сформулировал бы это так: «Агрегация предсказаний нескольких классификаторов с целью повышения точности».
Но если вы хотите обучать множественные классификаторы, вам нужно больше данных. Чем больше степеней свободы имеет ваша модель, тем больший объём данных модель старается вместить и тем больше точек данных вам понадобится. Здесь и пригодится бутстрэп.
Бутстрэп
Вы используете имеющиеся данные и пытаетесь их приумножить — в этом суть бутстрэпинга. Возьмите N точек данных и введите N раз с заменой — в результате вы получите несколько наборов одного размера. Поскольку вы используете замену, каждый из этих образцов будет немного отличаться. Вы можете использовать каждый из наборов данных отдельно.
Помните, что вы не можете делать перекрёстную проверку в этом случае, потому что у вас есть бутстрэп образцы х1 и х2 и некоторые точки присутствуют как в х1, так и в х2.
Для лучшего понимания бутстрэпинга читайте эту ветку на Stack Exchange.
Бэггинг
Первый из методов ансамблей, о котором мы поговорим, называется бэггинг (bagging — сокр. от bootstrap aggregation).
Один из недостатков деревьев принятия решений в том, что они выглядят по-разному при наличии небольшой разницы в данных. Ансамбли превращают этот недостаток в преимущество.
Бэггинг состоит из следующих шагов:
- Получение нескольких образцов с помощью замены из вашего набора данных (бутстрэпинг).
- Обучение классификатора для каждого образца.
- Усреднение результатов каждого классификатора.
Когда каждый бутстрэп-образец выглядит немного иначе, вы получаете разные деревья принятия решений. Вы можете усреднить их и получить хорошую классификацию. Бэггинг значительно снижает переобучение.
Основная идея бэггинга — усреднить «шумные» и несмещённые модели для создания модели с низким расхождением в рамках классификации. Посмотрите это видео, чтобы лучше понять, что такое бэггинг.
Случайный лес
Случайный лес использует много деревьев принятия решений для создания классификации. В качестве параметров используется число признаков и число деревьев. Случайный лес — это готовый классификатор, большую часть времени вам не придётся думать об этих параметрах.
Если вы разобрались с концепцией деревьев принятия решений, понять случайные леса вам будет нетрудно. Я бы порекомендовал вам прочесть введение в случайные леса для дилетантов от Эдвина Чена и посмотреть это видео.
Вероятность ошибки случайного леса зависит от корреляции между деревьями и от силы отдельных деревьев.
Но если вы увеличите количество признаков при каждом разделении, увеличится и корреляция между деревьями, и сила отдельных деревьев. Если ваши деревья не очень отличаются, усреднение не даст улучшений, на которые вы рассчитываете. Отдельные деревья должны быть действительно сильными, если вы хотите, чтобы каждое дерево чему-то научилось. Здесь нужен компромисс.
а) Out-Of-Bag-ошибка
OOB-ошибка — это встроенная версия расчёта ошибки теста. Это очень удобно, потому что вам не нужно откладывать набор данных в самом начале. Вы берёте бутстрэп-сэмпл, который покрывает 60% оригинальных точек данных, и у вас есть 30% неиспользованных. Суть в том, что вы можете использовать эти 30% как точки для оценки ошибки теста. Если я делаю бутстрэп-сэмплы и в конце получаю 500 штук — это для каждого отдельного дерева, не для всего леса — у меня есть бутстрэп-сэмпл и оставшиеся точки, которые в него не вошли. Я могу использовать их для оценки результатов теста для каждого отдельного дерева (не всего леса). Суть в том, что вы можете сделать это для каждого дерева, и это даст характеристику случайного леса, потому что вы знаете, насколько сильны отдельные деревья.
И всё же, я не считал бы OOB-ошибку ошибкой теста. Если вы изобразите их зависимость друг от друга, в большинстве случаев вы увидите возрастание, потому что это ненастоящая ошибка теста.
Можно использовать OOB-ошибку для валидации — таким образом вы можете подбирать оптимальное количество деревьев. Прочтите эту статью, чтобы узнать больше о OOB-ошибке.
b) Значимость переменной
Случайные леса позволяют вычислить эвристику для определения «значимости» параметра в предсказании цели. Она замеряет изменения в точности предсказаний, если вы возьмёте и перемешаете значения данного параметра между точками данных в тестовом наборе. Чем больше при этом снижается точность, тем более значимым считается параметр.
Допустим, есть 1000 мужчин и 1000 женщин. Измерим рост каждого человека и смоделируем предсказание роста по полу. В контексте случайного леса вы можете оценить точность предсказания out-of-bag.
Если пол не влияет на рост, вы должны получить примерно ту же точность предсказания при случайном переставлении значений М/Ж.
Так и работает значимость переменной случайных лесов: перемешайте наблюдаемые значения в рамках одной переменной, пересчитайте точности предсказаний и сравните полученные результаты с изначальными данными. Если перемешанные данные дают такие же предсказания, как и исходные, переменная, очевидно, не так важна для предсказания. Если же с перемешанными значениями точность предсказаний падает, переменная значима.
Несбалансированные классы
Несбалансированные классы означают, что у вас есть 8000 точек класса А и 2000 точек класса В. Ваша задача сделать так, чтобы классификатор понимал важность точек класса В. Один из вариантов — использовать сэмплы (продолжайте делать сэмплы, пока не получите два набора данных одинакового размера). Другой вариант — разбить на сэмплы большой класс. Случайный лес предоставляет хорошее решение для этого: вы можете создавать подсэмплы для каждого дерева. Таким образом, все деревья теперь сбалансированы, в итоге алгоритм получит все значения из большого класса.

Точность и полнота
Точность и полнота — оценочная метрика проблем классификации с асимметричными классами. Во многих приложениях необходимо контролировать соотношение точности и полноты.
Рассмотрим пример прогнозирования рака. Если вы модифицируете свою гипотезу (h(x)) до 0.7, чтобы уверенно прогнозировать рак, вы получите классификатор с высокой точностью и низкой полнотой. Иными словами, у пациента рак, но вы ошиблись, сообщив ему, что рака нет. Если вы установите (h(x)) на 0.3, вы получите высокую полноту и низкую точность. В этом случае классификатор может предсказать, что у большинства из них есть рак. Для большинства классификаторов это будет компромиссом между точностью и полнотой.
Есть ли способ определить порог автоматически? Как решить, какой из них лучше? И тут наступает очередь F-метрик. F-метрика — средство гармонизации точности и полноты.
Чтобы лучше понять, что такое точность и полнота, посмотрите эти видео-лекции (неделя 6) или прочитайте этот текст.
Бустинг
Это один из методов ансамблей, но он делает больше, чем просто усреднение. Вы обучаете один классификатор, смотрите на результаты и вносите коррективы. Вы обучаете второй, смотрите на результаты, вносите коррективы и усредняете их при помощи весов. Классификатору, который показал хороший результат, я хочу присвоить больший вес, второй получает меньший вес.
Для многих приложений бустинг подходит лучше, чем бэггинг. Читайте больше о бустинге здесь.
AdaBoost
В AdaBoost вы рисуете одну границу решений и смотрите на классификации — несколько точек будут ошибочными. Я присвою этим точкам большой вес (они не классифицированы, линия 1 на рисунке). И следующему классификатору, который буду обучать, я скажу обратить больше внимания на эти точки. В итоге получим другую границу решений (линия 2). Вместо того, чтобы вносить неразбериху, я смотрю на работу предыдущего классификатора и пытаюсь исправить совершенные им ошибки.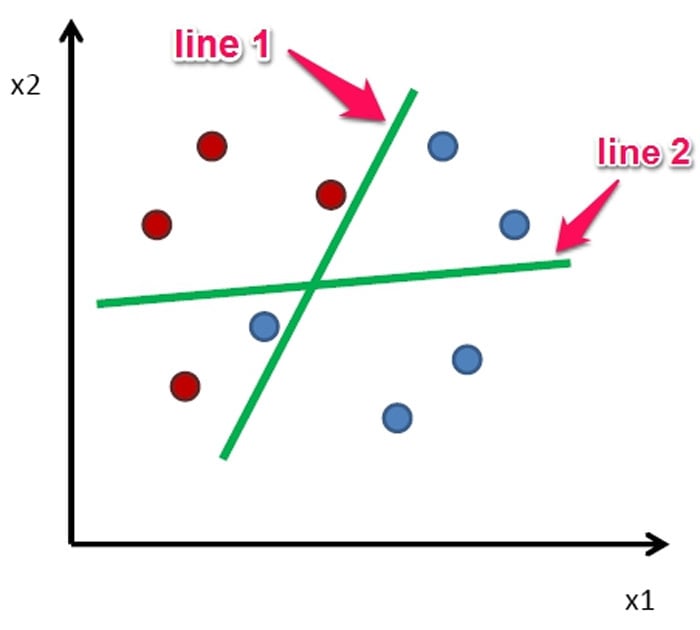
В большинстве случаев AdaBoost работает даже с «пнями». Пни решений — одноуровневое дерево принятия решений, с одним разветвлением. На практике, линия AdaBoost будет не прямой, а ломанной.
Заключение
Итак, я рассказал о некоторых наиболее важных концептах машинного обучения. Концепцию ансамблей я бы хотел передать этой цитатой Джеймса Суровецки (James Surowiecki):
«Коллективное знание разнообразной и независимой группы людей обычно превышает знания каждого отдельного индивида и может быть учтено путем голосования».
Кстати, метод ансамблей использовали победители Netflix prize — посмотрите видео.





Релоцировались? Теперь вы можете комментировать без верификации аккаунта.