Как отказаться от использования своих данных для обучения ИИ?
Сегодня многие компании автоматически используют пользовательский контент для обучения генеративных моделей. Можно ли отказаться от использования своих данных для ИИ? Мы описали доступные способы.
Сегодня многие компании автоматически используют пользовательский контент для обучения генеративных моделей. Можно ли отказаться от использования своих данных для ИИ? Мы описали доступные способы.
Не секрет, что все опубликованное в интернете почти наверняка уже использовали разработчики искусственного интеллекта для обучения своих моделей. Данных для обучения постоянно не хватает — и в ход идет любая информация, будь то треды в Reddit, ролики Youtube или рислы Instagram. Даже если вы не загружали свои данные напрямую в чат-бот, есть вероятность, что ваши селфи и комментарии на фейсбуке использовали для машинного обучения.
Эта сомнительная практика уже привела к череде исков и расследований, что заставило ИИ-компании дать людям больше контроля над своими данными. Некоторые разработчики позволяют частным лицам и бизнес-клиентам отказаться от использования их контента в обучении ИИ или продажи третьим лицам.
«Крупнейшая кража в США»: ИИ-стартапы похоронят копирайт
Многие компании уже использовали в обучении ИИ все, что смогли найти в интернете. Это значит, что с большой долей вероятности какая-то часть ваших данных попала в эти датасеты — и эту информацию практически невозможно извлечь или удалить из баз, с такой ситуацией придется лишь смириться. Как поясняют эксперты, ИИ-разработчики не распространяются о том, откуда они получили данные для обучения, и вы вряд ли сможете получить от них внятный ответ.
Также компании часто усложняют отказ от использования данных для обучения ИИ. Даже там, где это возможно, у многих пользователей нет четкого представления, на что они согласились и как их данные используют. Разработчики применяют очень расплывчатые формулировки или прячут отказ от использования данных в глубине настроек, куда пользователи обычно не заглядывают. Чаще всего компании прописывают такие разрешения в своей политике конфиденциальности и заставляют соглашаться с правилами по умолчанию.
Adobe
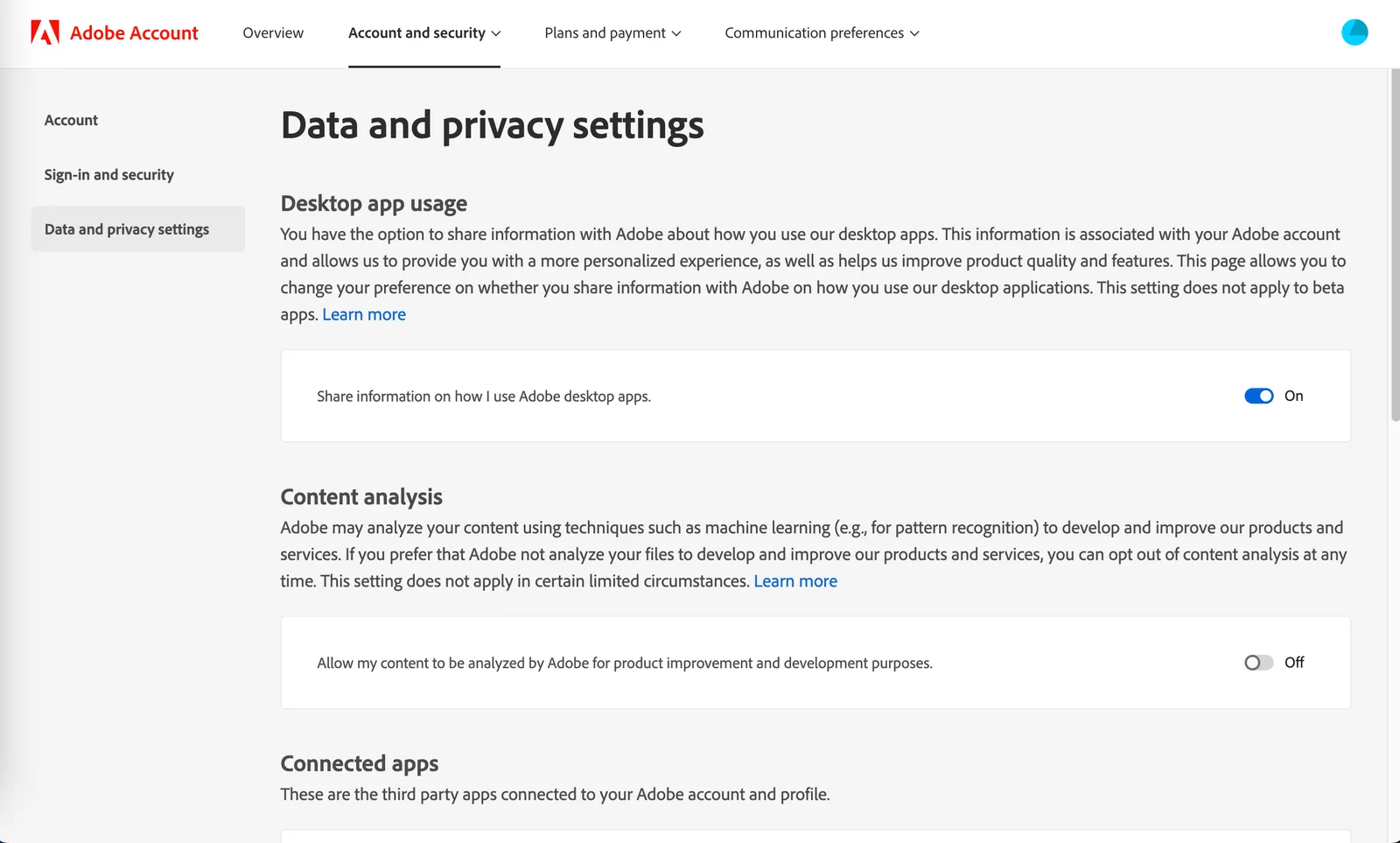
Adobe может анализировать файлы, хранящиеся в Creative Cloud, для улучшения своего программного обеспечения, но это не касается файлов, хранящихся только на вашем устройстве. Файлы не используются для обучения генеративных моделей ИИ, за исключением случаев, если вы сами загружаете их в Adobe Stock. Пользователи персональных аккаунтов могут легко отключить анализ контента в разделе конфиденциальности Adobe: откройте страницу конфиденциальности, прокрутите вниз до раздела Content analysis for product improvement и нажмите «Отключить». Владельцы бизнес- или образовательных аккаунтов автоматически исключены из анализа.
Amazon: AWS
Сервисы ИИ от Amazon Web Services, такие как Amazon Rekognition и Amazon CodeWhisperer, могут применять данные клиентов для улучшения своих инструментов. Однако у пользователей есть возможность отказаться от использования их данных для обучения ИИ. Процесс заметно упростили — полная инструкция по отказу доступна на странице поддержки Amazon.
Figma
Figma, популярное ПО для дизайна, может использовать ваши данные для обучения моделей. Если вы пользуетесь планами Organization или Enterprise, вы автоматически исключены из использования данных. Однако для пользователей планов Starter и Professional данные используются по умолчанию. Чтобы отключить эту настройку, нужно перейти в настройки команды, открыть вкладку AI и отключить опцию Content training.
Gemini
Google Gemini может выбирать некоторые чаты пользователей для проверки с целью улучшения модели ИИ. Отказаться от этого просто: откройте Gemini в браузере, перейдите в раздел Activity и выберите в выпадающем меню Turn Off. Вы можете либо отключить сбор данных Gemini Apps Activity, либо одновременно отказаться от сбора данных и удалить свои чаты. Однако уже отобранные данные не удалить таким способом. Согласно Центру конфиденциальности Google, такие данные могут храниться до трех лет.
Grammarly
Grammarly обновила свою политику, и теперь пользователи могут отказаться от использования своих данных для обучения ИИ. Для этого зайдите в раздел Account, затем Settings, и отключите Product Improvement and Training. Если ваш аккаунт пользуется корпоративным или образовательным тарифом, вы автоматически исключены из процесса обучения.
Grok
Все миллионы пользователей соцсети X автоматически включены в базу обучения ИИ без уведомления. Если у вас все еще есть аккаунт на X, вы можете отказаться от использования своих данных для обучения Grok. Для этого зайдите в раздел Settings and privacy, затем выберите Privacy and safety, откройте вкладку Grok и снимите опцию data sharing.
HubSpot
HubSpot, популярная платформа для маркетинга и продаж, автоматически использует данные клиентов для улучшения своей модели. Отключить использование данных для обучения ИИ невозможно. Чтобы отказаться от сбора информации, необходимо отправить письмо на [email protected] с запросом об исключении данных, связанных с вашим аккаунтом.
LinkedIn
Компания уведомила пользователей в сентябре этого года, что их данные могут использоваться для обучения моделей ИИ. «В конечном счете, люди хотят преимущества в своей карьере, и наши генеративные ИИ-сервисы помогают им в этом,» — заявил Элеанор Крам, представитель LinkedIn. Вы можете отказаться от использования ваших новых публикаций в LinkedIn для обучения ИИ, перейдя в профиль и открыв Settings. Затем выберите Data Privacy и снимите галочку с опции Use my data for training content creation AI models.
ChatGPT
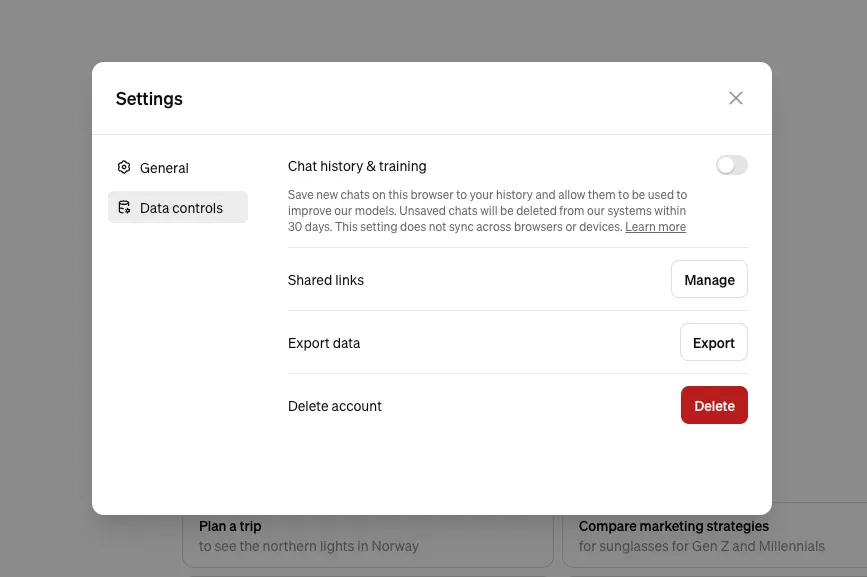
OpenAI предоставляет пользователям несколько способов контроля за тем, что происходит с их данными, включая возможность запретить обучение будущих моделей ИИ на их контенте. Эти опции могут немного различаться в зависимости от типа аккаунта, а данные корпоративных клиентов не используются для обучения моделей. Согласно странице справки OpenAI, пользователи ChatGPT, которые хотят отказаться от использования их данных, должны зайти в Settings, выбрать Data Controls и снять галочку с пункта Chat history & training.
Для пользователей генератора изображений Dall-E 3 компания предоставляет форму, с помощью которой пользователи могут отправлять запрос на удаление изображений из «будущих обучающих наборов данных». В форме необходимо указать имя, электронную почту, владение правами на изображение (или связь с компанией, если это корпоративный запрос), детали изображения и сами файлы.
OpenAI рекомендует пользователям применять в случае необходимости файл robots.txt для сайтов, который запрещает краулерам парсить данные. Традиционно файл robots.txt использовался для указания поисковым системам, можно ли индексировать страницы сайта. Теперь его также можно применять для запрета ИИ-ботам сканировать опубликованный контент.
Perplexity
Perplexity — это стартап, который использует ИИ для поиска информации в интернете и ответов на вопросы. Как и в случае с другими программами из списка, ваши взаимодействия и данные автоматически используются для дальнейшего обучения ИИ Perplexity. Чтобы отключить эту опцию, нажмите на свое имя аккаунта, перейдите в раздел Account и отключите переключатель AI Data Retention.
Slack
Все сообщения в Slack могут быть использованы компанией для обучения своих моделей. Как сказано в политике конфиденциальности сервиса, хотя компания не использует данные клиентов для обучения крупной языковой модели Slack AI, она может использовать ваши взаимодействия, такие как сообщения, контент и файлы, для улучшения возможностей машинного обучения. Единственный способ отказаться от использования ваших данных — это попросить администратора вашей организации отправить письмо на [email protected] с темой письма «Slack Global model opt-out request». В письме необходимо указать URL вашей организации. Slack не предоставляет конкретных сроков обработки таких запросов, но обещает отправить подтверждение после завершения процесса.
Substack
Если вы используете Substack для блогов, рассылок или другого контента, платформа предлагает простой способ отключить использование вашего контента для обучения ИИ с помощью файла robots.txt. В разделе Settings откройте вкладку Publication и включите опцию Block AI training. Однако в справке Substack указано, что это будет действовать только для инструментов ИИ, которые уважают данную настройку.
tumblr
Платформа заявляет, что сотрудничает с ИИ-компания, которые интересуются «обширным и уникальным набором общедоступного контента» на ее сайте. На Tumblr доступна опция «prevent third-party sharing» (запрет на передачу третьим сторонам), которая предотвращает использование ваших публикаций для обучения ИИ, а также их передачу исследователям или другим лицам. Чтобы включить эту опцию в приложении Tumblr, зайдите в Settings вашей учетной записи, выберите ваш блог, нажмите на значок шестеренки, выберите раздел Visibility и активируйте опцию «Prevent third-party sharing».
Wordpress
В WordPress доступна опция «prevent third-party sharing». Чтобы активировать эту настройку, зайдите в панель управления вашего сайта, откройте Settings, затем General, перейдите в раздел Privacy и установите галочку «Prevent third-party sharing».










Релоцировались? Теперь вы можете комментировать без верификации аккаунта.